 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Facial Geometry Recovery from a Depth View with Attention Guided Generative Adversarial Network
Sep 02, 2020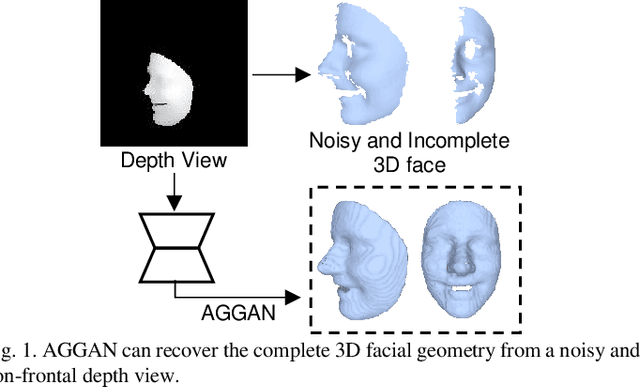


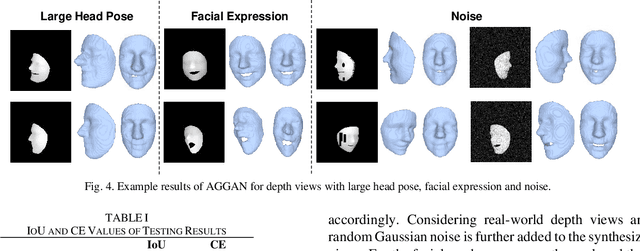
We present to recover the complete 3D facial geometry from a single depth view by proposing an Attention Guided Generative Adversarial Networks (AGGAN). In contrast to existing work which normally requires two or more depth views to recover a full 3D facial geometry, the proposed AGGAN is able to generate a dense 3D voxel grid of the face from a single unconstrained depth view. Specifically, AGGAN encodes the 3D facial geometry within a voxel space and utilizes an attention-guided GAN to model the illposed 2.5D depth-3D mapping. Multiple loss functions, which enforce the 3D facial geometry consistency, together with a prior distribution of facial surface points in voxel space are incorporated to guide the training process. Both qualitative and quantitative comparisons show that AGGAN recovers a more complete and smoother 3D facial shape, with the capability to handle a much wider range of view angles and resist to noise in the depth view than conventional methods