 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroBP: Learning Position-Aware Correspondence for Zero-shot 6D Pose Estimation in Bin-Picking
Feb 03, 2025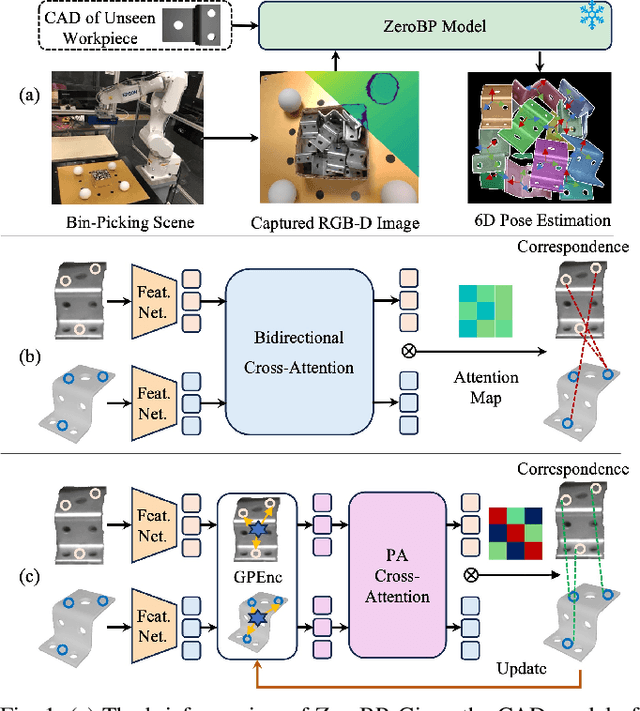



Bin-picking is a practical and challenging robotic manipulation task, where accurate 6D pose estimation plays a pivotal role. The workpieces in bin-picking are typically textureless and randomly stacked in a bin, which poses a significant challenge to 6D pose estimation. Existing solutions are typically learning-based methods, which require object-specific training. Their efficiency of practical deployment for novel workpieces is highly limited by data collection and model retraining. Zero-shot 6D pose estimation is a potential approach to address the issue of deployment efficiency. Nevertheless, existing zero-shot 6D pose estimation methods are designed to leverage feature matching to establish point-to-point correspondences for pose estimation, which is less effective for workpieces with textureless appearances and ambiguous local regions. In this paper, we propose ZeroBP, a zero-shot pose estimation framework designed specifically for the bin-picking task. ZeroBP learns Position-Aware Correspondence (PAC) between the scene instance and its CAD model, leveraging both local features and global positions to resolve the mismatch issue caused by ambiguous regions with similar shapes and appearances. Extensive experiments on the ROBI dataset demonstrate that ZeroBP outperforms state-of-the-art zero-shot pose estimation methods, achieving an improvement of 9.1% in average recall of correct poses.
MambaVLT: Time-Evolving Multimodal State Space Model for Vision-Language Tracking
Nov 23, 2024



The vision-language tracking task aims to perform object tracking based on various modality references. Existing Transformer-based vision-language tracking methods have made remarkable progress by leveraging the global modeling ability of self-attention. However, current approaches still face challenges in effectively exploiting the temporal information and dynamically updating reference features during tracking. Recently, the State Space Model (SSM), known as Mamba, has shown astonishing ability in efficient long-sequence modeling. Particularly, its state space evolving process demonstrates promising capabilities in memorizing multimodal temporal information with linear complexity. Witnessing its success, we propose a Mamba-based vision-language tracking model to exploit its state space evolving ability in temporal space for robust multimodal tracking, dubbed MambaVLT. In particular, our approach mainly integrates a time-evolving hybrid state space block and a selective locality enhancement block, to capture contextual information for multimodal modeling and adaptive reference feature update. Besides, we introduce a modality-selection module that dynamically adjusts the weighting between visual and language references, mitigating potential ambiguities from either reference type. Extensive experimental results show that our method performs favorably against state-of-the-art trackers across diverse benchmarks.
3D Model-based Zero-Shot Pose Estimation Pipeline
May 29, 2023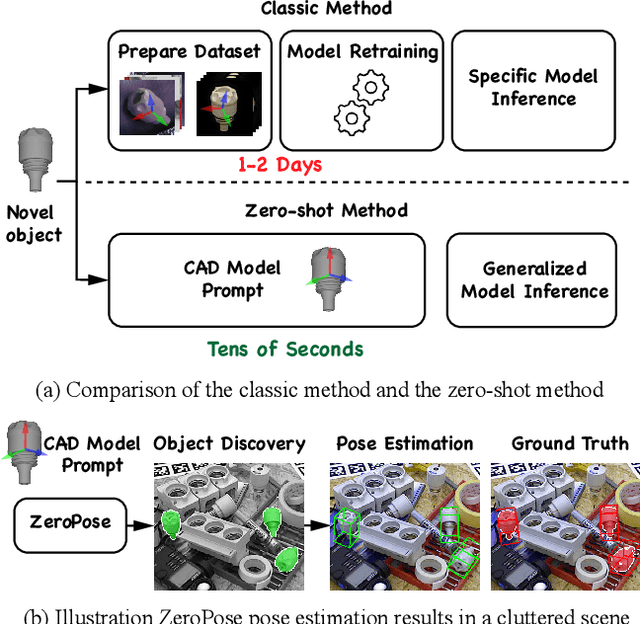
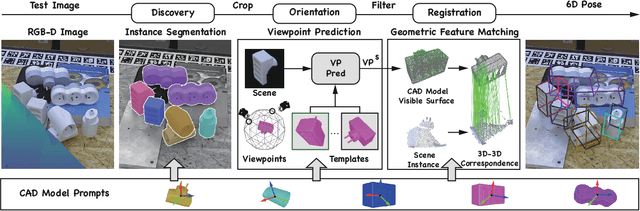
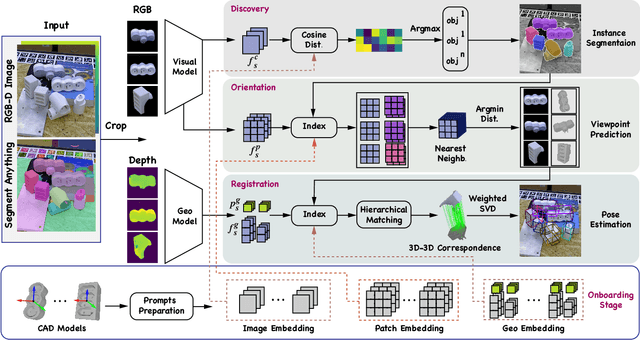
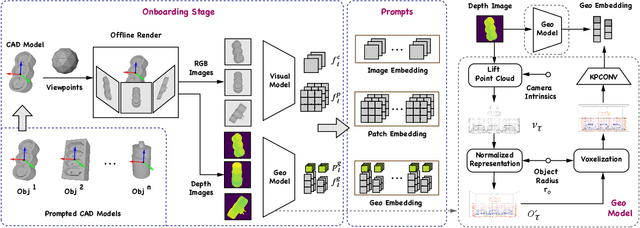
Most existing learning-based pose estimation methods are typically developed for non-zero-shot scenarios, where they can only estimate the poses of objects present in the training dataset. This setting restricts their applicability to unseen objects in the training phase. In this paper, we introduce a fully zero-shot pose estimation pipeline that leverages the 3D models of objects as clues. Specifically, we design a two-step pipeline consisting of 3D model-based zero-shot instance segmentation and a zero-shot pose estimator. For the first step, there is a novel way to perform zero-shot instance segmentation based on the 3D models instead of text descriptions, which can handle complex properties of unseen objects. For the second step, we utilize a hierarchical geometric structure matching mechanism to perform zero-shot pose estimation which is 10 times faster than the current render-based method. Extensive experimental results on the seven core datasets on the BOP challenge show that the proposed method outperforms the zero-shot state-of-the-art method with higher speed and lower computation cost.
Uni6Dv2: Noise Elimination for 6D Pose Estimation
Aug 15, 2022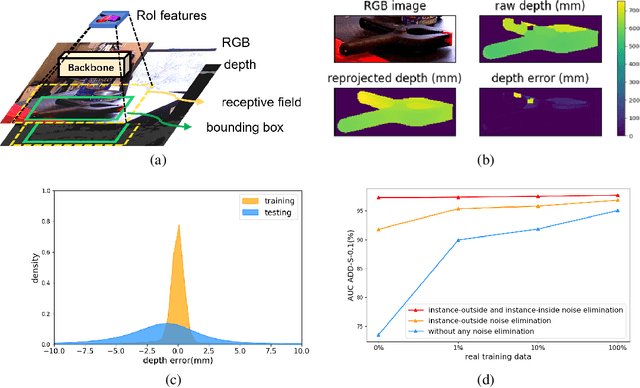
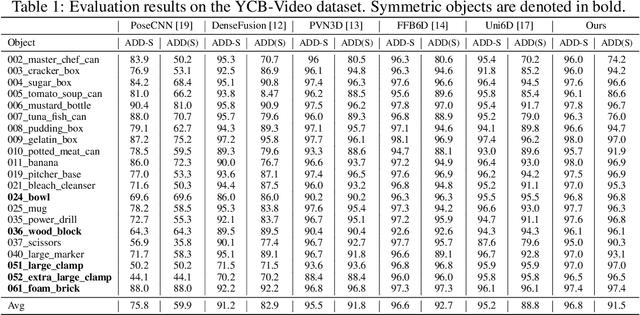
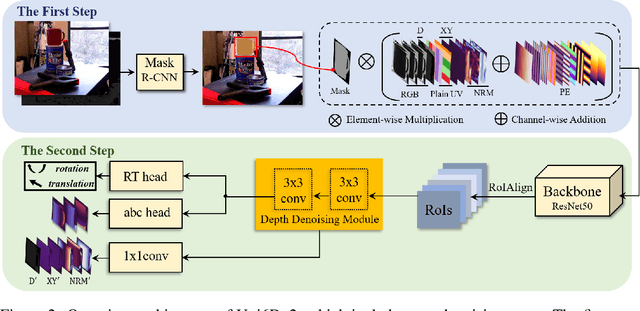
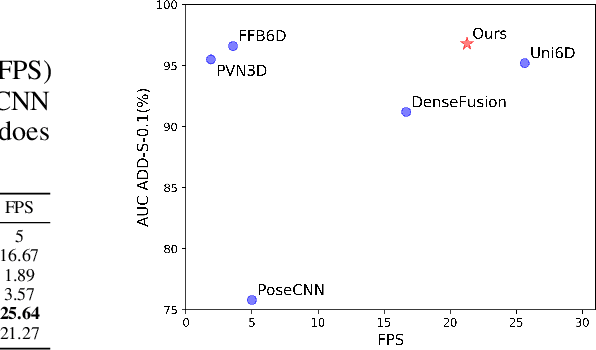
Few prior 6D pose estimation methods use a backbone network to extract features from RGB and depth images, and Uni6D is the pioneer to do so. We find that primary causes of the performance limitation in Uni6D are Instance-Outside and Instance-Inside noise. Uni6D inevitably introduces Instance-Outside noise from background pixels in the receptive field due to its inherently straightforward pipeline design and ignores the Instance-Inside noise in the input depth data. In this work, we propose a two-step denoising method to handle aforementioned noise in Uni6D. In the first step, an instance segmentation network is used to crop and mask the instance to remove noise from non-instance regions. In the second step, a lightweight depth denoising module is proposed to calibrate the depth feature before feeding it into the pose regression network. Extensive experiments show that our method called Uni6Dv2 is able to eliminate the noise effectively and robustly, outperforming Uni6D without sacrificing too much inference efficiency. It also reduces the need for annotated real data that requires costly labeling.
Global Tracking via Ensemble of Local Trackers
Mar 30, 2022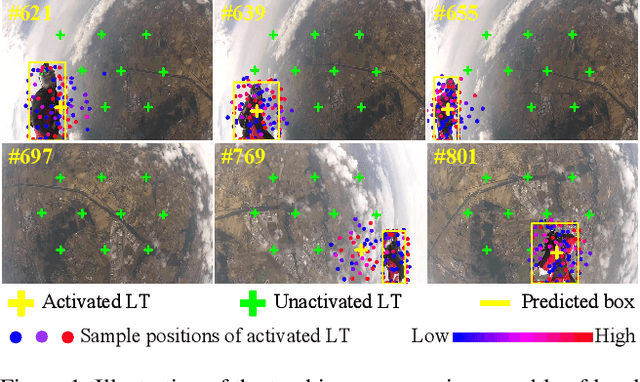
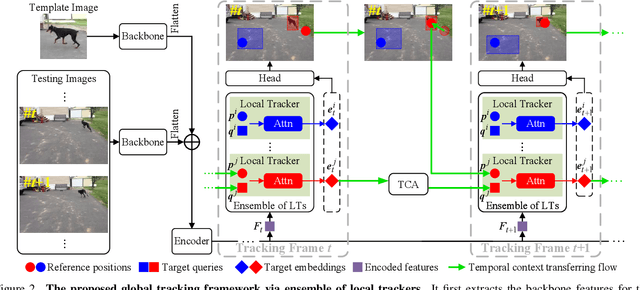
The crux of long-term tracking lies in the difficulty of tracking the target with discontinuous moving caused by out-of-view or occlusion. Existing long-term tracking methods follow two typical strategies. The first strategy employs a local tracker to perform smooth tracking and uses another re-detector to detect the target when the target is lost. While it can exploit the temporal context like historical appearances and locations of the target, a potential limitation of such strategy is that the local tracker tends to misidentify a nearby distractor as the target instead of activating the re-detector when the real target is out of view. The other long-term tracking strategy tracks the target in the entire image globally instead of local tracking based on the previous tracking results. Unfortunately, such global tracking strategy cannot leverage the temporal context effectively. In this work, we combine the advantages of both strategies: tracking the target in a global view while exploiting the temporal context. Specifically, we perform global tracking via ensemble of local trackers spreading the full image. The smooth moving of the target can be handled steadily by one local tracker. When the local tracker accidentally loses the target due to suddenly discontinuous moving, another local tracker close to the target is then activated and can readily take over the tracking to locate the target. While the activated local tracker performs tracking locally by leveraging the temporal context, the ensemble of local trackers renders our model the global view for tracking. Extensive experiments on six datasets demonstrate that our method performs favorably against state-of-the-art algorithms.