 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Imitation Learning for Long-horizon Manipulation via Hierarchical Data Collection Space
May 23, 2025Imitation learning (IL) with human demonstrations is a promising method for robotic manipulation tasks. While minimal demonstrations enable robotic action execution, achieving high success rates and generalization requires high cost, e.g., continuously adding data or incrementally conducting human-in-loop processes with complex hardware/software systems. In this paper, we rethink the state/action space of the data collection pipeline as well as the underlying factors responsible for the prediction of non-robust actions. To this end, we introduce a Hierarchical Data Collection Space (HD-Space) for robotic imitation learning, a simple data collection scheme, endowing the model to train with proactive and high-quality data. Specifically, We segment the fine manipulation task into multiple key atomic tasks from a high-level perspective and design atomic state/action spaces for human demonstrations, aiming to generate robust IL data. We conduct empirical evaluations across two simulated and five real-world long-horizon manipulation tasks and demonstrate that IL policy training with HD-Space-based data can achieve significantly enhanced policy performance. HD-Space allows the use of a small amount of demonstration data to train a more powerful policy, particularly for long-horizon manipulation tasks. We aim for HD-Space to offer insights into optimizing data quality and guiding data scaling. project page: https://hd-space-robotics.github.io.
3D Model-based Zero-Shot Pose Estimation Pipeline
May 29, 2023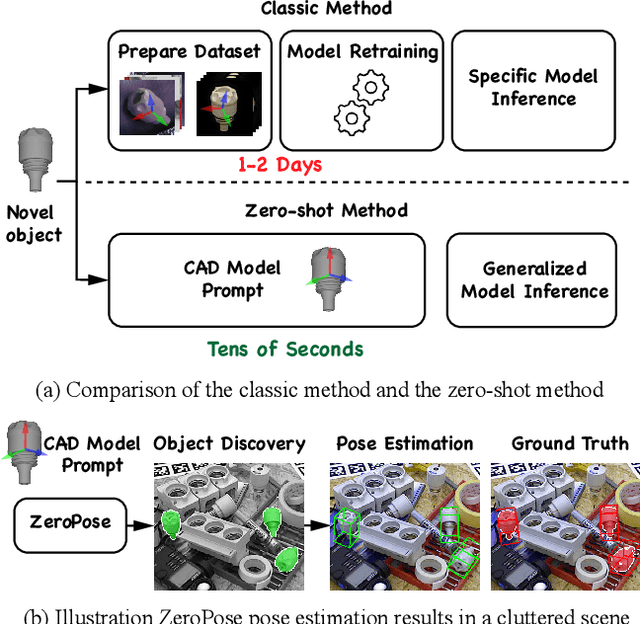
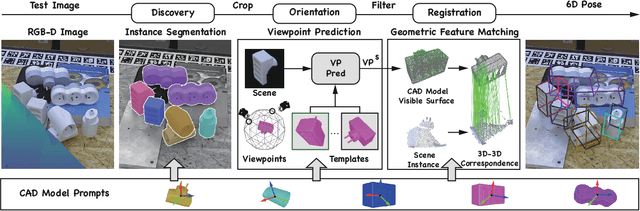
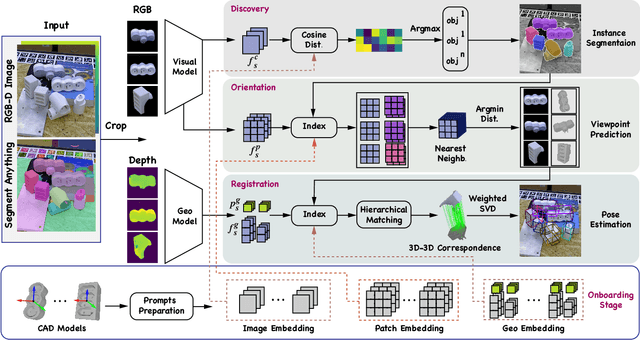
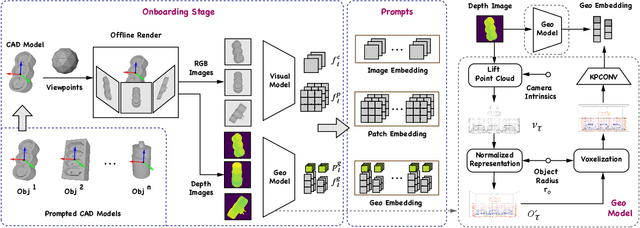
Most existing learning-based pose estimation methods are typically developed for non-zero-shot scenarios, where they can only estimate the poses of objects present in the training dataset. This setting restricts their applicability to unseen objects in the training phase. In this paper, we introduce a fully zero-shot pose estimation pipeline that leverages the 3D models of objects as clues. Specifically, we design a two-step pipeline consisting of 3D model-based zero-shot instance segmentation and a zero-shot pose estimator. For the first step, there is a novel way to perform zero-shot instance segmentation based on the 3D models instead of text descriptions, which can handle complex properties of unseen objects. For the second step, we utilize a hierarchical geometric structure matching mechanism to perform zero-shot pose estimation which is 10 times faster than the current render-based method. Extensive experimental results on the seven core datasets on the BOP challenge show that the proposed method outperforms the zero-shot state-of-the-art method with higher speed and lower computation cost.
SeqCo-DETR: Sequence Consistency Training for Self-Supervised Object Detection with Transformers
Mar 15, 2023



Self-supervised pre-training and transformer-based networks have significantly improved the performance of object detection. However, most of the current self-supervised object detection methods are built on convolutional-based architectures. We believe that the transformers' sequence characteristics should be considered when designing a transformer-based self-supervised method for the object detection task. To this end, we propose SeqCo-DETR, a novel Sequence Consistency-based self-supervised method for object DEtection with TRansformers. SeqCo-DETR defines a simple but effective pretext by minimizes the discrepancy of the output sequences of transformers with different image views as input and leverages bipartite matching to find the most relevant sequence pairs to improve the sequence-level self-supervised representation learning performance. Furthermore, we provide a mask-based augmentation strategy incorporated with the sequence consistency strategy to extract more representative contextual information about the object for the object detection task. Our method achieves state-of-the-art results on MS COCO (45.8 AP) and PASCAL VOC (64.1 AP), demonstrating the effectiveness of our approach.
Uni6Dv2: Noise Elimination for 6D Pose Estimation
Aug 15, 2022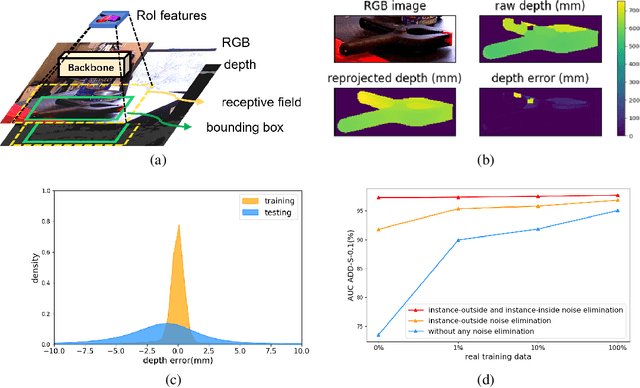
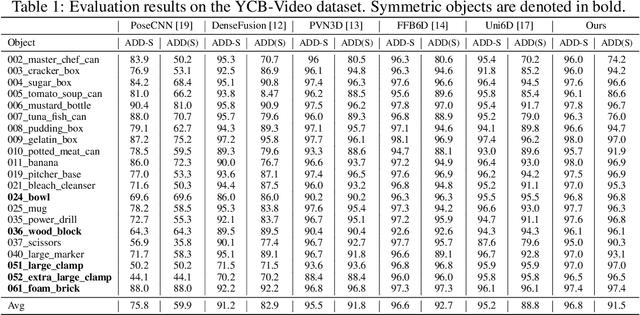
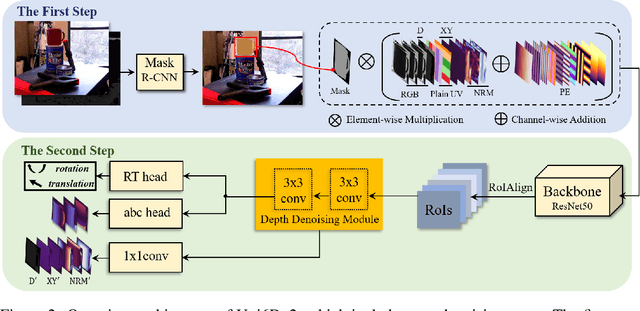
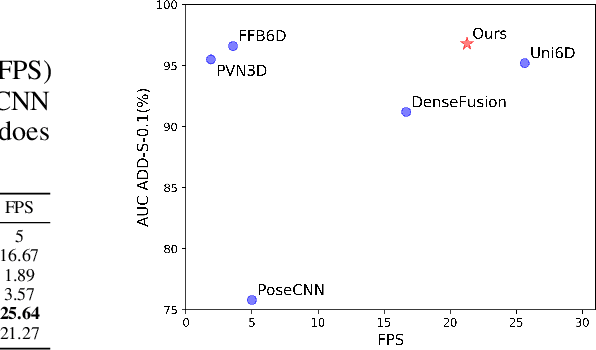
Few prior 6D pose estimation methods use a backbone network to extract features from RGB and depth images, and Uni6D is the pioneer to do so. We find that primary causes of the performance limitation in Uni6D are Instance-Outside and Instance-Inside noise. Uni6D inevitably introduces Instance-Outside noise from background pixels in the receptive field due to its inherently straightforward pipeline design and ignores the Instance-Inside noise in the input depth data. In this work, we propose a two-step denoising method to handle aforementioned noise in Uni6D. In the first step, an instance segmentation network is used to crop and mask the instance to remove noise from non-instance regions. In the second step, a lightweight depth denoising module is proposed to calibrate the depth feature before feeding it into the pose regression network. Extensive experiments show that our method called Uni6Dv2 is able to eliminate the noise effectively and robustly, outperforming Uni6D without sacrificing too much inference efficiency. It also reduces the need for annotated real data that requires costly labeling.