 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliability-Hierarchical Memory Network for Scribble-Supervised Video Object Segmentation
Mar 25, 2023This paper aims to solve the video object segmentation (VOS) task in a scribble-supervised manner, in which VOS models are not only trained by the sparse scribble annotations but also initialized with the sparse target scribbles for inference. Thus, the annotation burdens for both training and initialization can be substantially lightened. The difficulties of scribble-supervised VOS lie in two aspects. On the one hand, it requires the powerful ability to learn from the sparse scribble annotations during training. On the other hand, it demands strong reasoning capability during inference given only a sparse initial target scribble. In this work, we propose a Reliability-Hierarchical Memory Network (RHMNet) to predict the target mask in a step-wise expanding strategy w.r.t. the memory reliability level. To be specific, RHMNet first only uses the memory in the high-reliability level to locate the region with high reliability belonging to the target, which is highly similar to the initial target scribble. Then it expands the located high-reliability region to the entire target conditioned on the region itself and the memories in all reliability levels. Besides, we propose a scribble-supervised learning mechanism to facilitate the learning of our model to predict dense results. It mines the pixel-level relation within the single frame and the frame-level relation within the sequence to take full advantage of the scribble annotations in sequence training samples. The favorable performance on two popular benchmarks demonstrates that our method is promising.
Joint Visual Grounding and Tracking with Natural Language Specification
Mar 21, 2023



Tracking by natural language specification aims to locate the referred target in a sequence based on the natural language description. Existing algorithms solve this issue in two steps, visual grounding and tracking, and accordingly deploy the separated grounding model and tracking model to implement these two steps, respectively. Such a separated framework overlooks the link between visual grounding and tracking, which is that the natural language descriptions provide global semantic cues for localizing the target for both two steps. Besides, the separated framework can hardly be trained end-to-end. To handle these issues, we propose a joint visual grounding and tracking framework, which reformulates grounding and tracking as a unified task: localizing the referred target based on the given visual-language references. Specifically, we propose a multi-source relation modeling module to effectively build the relation between the visual-language references and the test image. In addition, we design a temporal modeling module to provide a temporal clue with the guidance of the global semantic information for our model, which effectively improves the adaptability to the appearance variations of the target. Extensive experimental results on TNL2K, LaSOT, OTB99, and RefCOCOg demonstrate that our method performs favorably against state-of-the-art algorithms for both tracking and grounding. Code is available at https://github.com/lizhou-cs/JointNLT.
Global Tracking via Ensemble of Local Trackers
Mar 30, 2022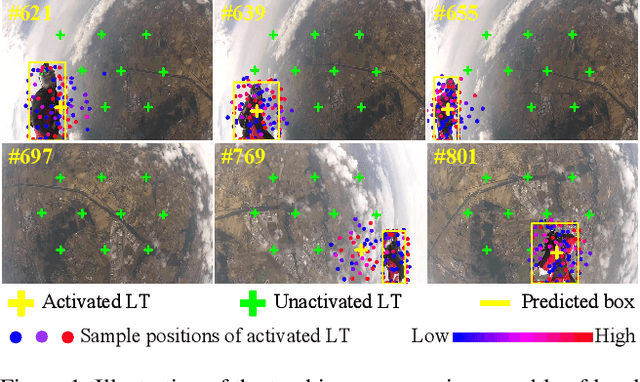
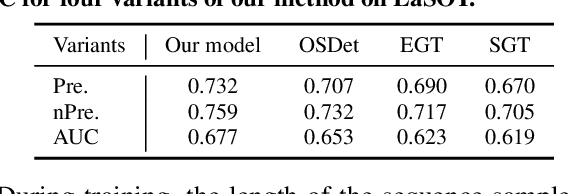
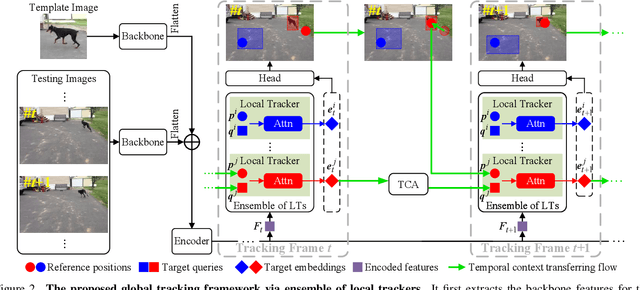
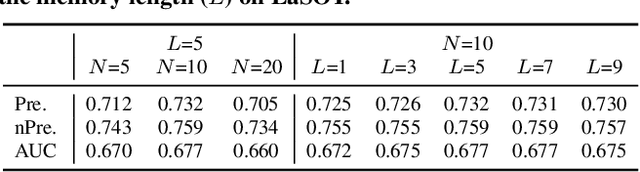
The crux of long-term tracking lies in the difficulty of tracking the target with discontinuous moving caused by out-of-view or occlusion. Existing long-term tracking methods follow two typical strategies. The first strategy employs a local tracker to perform smooth tracking and uses another re-detector to detect the target when the target is lost. While it can exploit the temporal context like historical appearances and locations of the target, a potential limitation of such strategy is that the local tracker tends to misidentify a nearby distractor as the target instead of activating the re-detector when the real target is out of view. The other long-term tracking strategy tracks the target in the entire image globally instead of local tracking based on the previous tracking results. Unfortunately, such global tracking strategy cannot leverage the temporal context effectively. In this work, we combine the advantages of both strategies: tracking the target in a global view while exploiting the temporal context. Specifically, we perform global tracking via ensemble of local trackers spreading the full image. The smooth moving of the target can be handled steadily by one local tracker. When the local tracker accidentally loses the target due to suddenly discontinuous moving, another local tracker close to the target is then activated and can readily take over the tracking to locate the target. While the activated local tracker performs tracking locally by leveraging the temporal context, the ensemble of local trackers renders our model the global view for tracking. Extensive experiments on six datasets demonstrate that our method performs favorably against state-of-the-art algorithms.