 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart-Insertion-V: Photorealistic Video Insertion via a Closed-Loop Feedback Dual-Stream Framework
May 22, 2026Mask-free video object insertion has emerged as a challenging task, requiring harmonious integration of reference objects into source videos. However, existing methods struggle when references exhibit severe stylistic domain gaps with the source scene. To overcome this, we propose \textit{\textbf{Smart-Insertion-V}}, an end-to-end \textbf{Dual-Stream} framework that concurrently conducts video insertion and image style transfer. Within this framework, the image stream synchronously guides the video generation process, while a \textbf{Closed-loop Feedback} mechanism is further incorporated to ensure robust insertion. Inevitably, integrating these diverse conditioning signals results in feature entanglement and style leakage. To tackle this issue, we design \textbf{Dual-World-View RoPE} to distinguish different signals via spatial-temporal offsets without incurring heavy training overhead. Furthermore, to facilitate spatial grounding and stylistic adaptation, we introduce a \textbf{Decoupled Guidance Module} that leverages a Vision-Language Model for semantic reasoning while preserving original temporal guidance with native text encoder. To bridge data gap for harmonious reference insertion task, we propose a data curation pipeline and will release an \textbf{open-source dataset}. Experiments demonstrate that our method can insert objects into plausible positions while achieving the most harmonious results.
GarmentPainter: Efficient 3D Garment Texture Synthesis with Character-Guided Diffusion Model
Mar 09, 2026Generating high-fidelity, 3D-consistent garment textures remains a challenging problem due to the inherent complexities of garment structures and the stringent requirement for detailed, globally consistent texture synthesis. Existing approaches either rely on 2D-based diffusion models, which inherently struggle with 3D consistency, require expensive multi-step optimization or depend on strict spatial alignment between 2D reference images and 3D meshes, which limits their flexibility and scalability. In this work, we introduce GarmentPainter, a simple yet efficient framework for synthesizing high-quality, 3D-aware garment textures in UV space. Our method leverages a UV position map as the 3D structural guidance, ensuring texture consistency across the garment surface during texture generation. To enhance control and adaptability, we introduce a type selection module, enabling fine-grained texture generation for specific garment components based on a character reference image, without requiring alignment between the reference image and the 3D mesh. GarmentPainter efficiently integrates all guidance signals into the input of a diffusion model in a spatially aligned manner, without modifying the underlying UNet architecture. Extensive experiments demonstrate that GarmentPainter achieves state-of-the-art performance in terms of visual fidelity, 3D consistency, and computational efficiency, outperforming existing methods in both qualitative and quantitative evaluations.
LiftAvatar: Kinematic-Space Completion for Expression-Controlled 3D Gaussian Avatar Animation
Mar 02, 2026We present LiftAvatar, a new paradigm that completes sparse monocular observations in kinematic space (e.g., facial expressions and head pose) and uses the completed signals to drive high-fidelity avatar animation. LiftAvatar is a fine-grained, expression-controllable large-scale video diffusion Transformer that synthesizes high-quality, temporally coherent expression sequences conditioned on single or multiple reference images. The key idea is to lift incomplete input data into a richer kinematic representation, thereby strengthening both reconstruction and animation in downstream 3D avatar pipelines. To this end, we introduce (i) a multi-granularity expression control scheme that combines shading maps with expression coefficients for precise and stable driving, and (ii) a multi-reference conditioning mechanism that aggregates complementary cues from multiple frames, enabling strong 3D consistency and controllability. As a plug-and-play enhancer, LiftAvatar directly addresses the limited expressiveness and reconstruction artifacts of 3D Gaussian Splatting-based avatars caused by sparse kinematic cues in everyday monocular videos. By expanding incomplete observations into diverse pose-expression variations, LiftAvatar also enables effective prior distillation from large-scale video generative models into 3D pipelines, leading to substantial gains. Extensive experiments show that LiftAvatar consistently boosts animation quality and quantitative metrics of state-of-the-art 3D avatar methods, especially under extreme, unseen expressions.
Geometry-as-context: Modulating Explicit 3D in Scene-consistent Video Generation to Geometry Context
Feb 25, 2026Scene-consistent video generation aims to create videos that explore 3D scenes based on a camera trajectory. Previous methods rely on video generation models with external memory for consistency, or iterative 3D reconstruction and inpainting, which accumulate errors during inference due to incorrect intermediary outputs, non-differentiable processes, and separate models. To overcome these limitations, we introduce ``geometry-as-context". It iteratively completes the following steps using an autoregressive camera-controlled video generation model: (1) estimates the geometry of the current view necessary for 3D reconstruction, and (2) simulates and restores novel view images rendered by the 3D scene. Under this multi-task framework, we develop the camera gated attention module to enhance the model's capability to effectively leverage camera poses. During the training phase, text contexts are utilized to ascertain whether geometric or RGB images should be generated. To ensure that the model can generate RGB-only outputs during inference, the geometry context is randomly dropped from the interleaved text-image-geometry training sequence. The method has been tested on scene video generation with one-direction and forth-and-back trajectories. The results show its superiority over previous approaches in maintaining scene consistency and camera control.
Tele-Omni: a Unified Multimodal Framework for Video Generation and Editing
Feb 10, 2026Recent advances in diffusion-based video generation have substantially improved visual fidelity and temporal coherence. However, most existing approaches remain task-specific and rely primarily on textual instructions, limiting their ability to handle multimodal inputs, contextual references, and diverse video generation and editing scenarios within a unified framework. Moreover, many video editing methods depend on carefully engineered pipelines tailored to individual operations, which hinders scalability and composability. In this paper, we propose Tele-Omni, a unified multimodal framework for video generation and editing that follows multimodal instructions, including text, images, and reference videos, within a single model. Tele-Omni leverages pretrained multimodal large language models to parse heterogeneous instructions and infer structured generation or editing intents, while diffusion-based generators perform high-quality video synthesis conditioned on these structured signals. To enable joint training across heterogeneous video tasks, we introduce a task-aware data processing pipeline that unifies multimodal inputs into a structured instruction format while preserving task-specific constraints. Tele-Omni supports a wide range of video-centric tasks, including text-to-video generation, image-to-video generation, first-last-frame video generation, in-context video generation, and in-context video editing. By decoupling instruction parsing from video synthesis and combining it with task-aware data design, Tele-Omni achieves flexible multimodal control while maintaining strong temporal coherence and visual consistency. Experimental results demonstrate that Tele-Omni achieves competitive performance across multiple tasks.
TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
Omni-View: Unlocking How Generation Facilitates Understanding in Unified 3D Model based on Multiview images
Nov 10, 2025This paper presents Omni-View, which extends the unified multimodal understanding and generation to 3D scenes based on multiview images, exploring the principle that "generation facilitates understanding". Consisting of understanding model, texture module, and geometry module, Omni-View jointly models scene understanding, novel view synthesis, and geometry estimation, enabling synergistic interaction between 3D scene understanding and generation tasks. By design, it leverages the spatiotemporal modeling capabilities of its texture module responsible for appearance synthesis, alongside the explicit geometric constraints provided by its dedicated geometry module, thereby enriching the model's holistic understanding of 3D scenes. Trained with a two-stage strategy, Omni-View achieves a state-of-the-art score of 55.4 on the VSI-Bench benchmark, outperforming existing specialized 3D understanding models, while simultaneously delivering strong performance in both novel view synthesis and 3D scene generation.
TexGaussian: Generating High-quality PBR Material via Octree-based 3D Gaussian Splatting
Nov 29, 2024
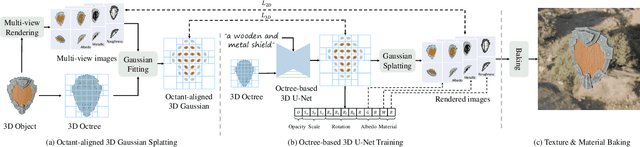


Physically Based Rendering (PBR) materials play a crucial role in modern graphics, enabling photorealistic rendering across diverse environment maps. Developing an effective and efficient algorithm that is capable of automatically generating high-quality PBR materials rather than RGB texture for 3D meshes can significantly streamline the 3D content creation. Most existing methods leverage pre-trained 2D diffusion models for multi-view image synthesis, which often leads to severe inconsistency between the generated textures and input 3D meshes. This paper presents TexGaussian, a novel method that uses octant-aligned 3D Gaussian Splatting for rapid PBR material generation. Specifically, we place each 3D Gaussian on the finest leaf node of the octree built from the input 3D mesh to render the multiview images not only for the albedo map but also for roughness and metallic. Moreover, our model is trained in a regression manner instead of diffusion denoising, capable of generating the PBR material for a 3D mesh in a single feed-forward process. Extensive experiments on publicly available benchmarks demonstrate that our method synthesizes more visually pleasing PBR materials and runs faster than previous methods in both unconditional and text-conditional scenarios, which exhibit better consistency with the given geometry. Our code and trained models are available at https://3d-aigc.github.io/TexGaussian.
PRG: Prompt-Based Distillation Without Annotation via Proxy Relational Graph
Aug 22, 2024



In this paper, we propose a new distillation method for extracting knowledge from Large Foundation Models (LFM) into lightweight models, introducing a novel supervision mode that does not require manually annotated data. While LFMs exhibit exceptional zero-shot classification abilities across datasets, relying solely on LFM-generated embeddings for distillation poses two main challenges: LFM's task-irrelevant knowledge and the high density of features. The transfer of task-irrelevant knowledge could compromise the student model's discriminative capabilities, and the high density of features within target domains obstructs the extraction of discriminative knowledge essential for the task. To address this issue, we introduce the Proxy Relational Graph (PRG) method. We initially extract task-relevant knowledge from LFMs by calculating a weighted average of logits obtained through text prompt embeddings. Then we construct sample-class proxy graphs for LFM and student models, respectively, to model the correlation between samples and class proxies. Then, we achieve the distillation of selective knowledge by aligning the relational graphs produced by both the LFM and the student model. Specifically, the distillation from LFM to the student model is achieved through two types of alignment: 1) aligning the sample nodes produced by the student model with those produced by the LFM, and 2) aligning the edge relationships in the student model's graph with those in the LFM's graph. Our experimental results validate the effectiveness of PRG, demonstrating its ability to leverage the extensive knowledge base of LFMs while skillfully circumventing their inherent limitations in focused learning scenarios. Notably, in our annotation-free framework, PRG achieves an accuracy of 76.23\% (T: 77.9\%) on CIFAR-100 and 72.44\% (T: 75.3\%) on the ImageNet-1K.
TexRO: Generating Delicate Textures of 3D Models by Recursive Optimization
Mar 22, 2024This paper presents TexRO, a novel method for generating delicate textures of a known 3D mesh by optimizing its UV texture. The key contributions are two-fold. We propose an optimal viewpoint selection strategy, that finds the most miniature set of viewpoints covering all the faces of a mesh. Our viewpoint selection strategy guarantees the completeness of a generated result. We propose a recursive optimization pipeline that optimizes a UV texture at increasing resolutions, with an adaptive denoising method that re-uses existing textures for new texture generation. Through extensive experimentation, we demonstrate the superior performance of TexRO in terms of texture quality, detail preservation, visual consistency, and, notably runtime speed, outperforming other current methods. The broad applicability of TexRO is further confirmed through its successful use on diverse 3D models.