 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Seeking Self-Supervised Representation Learning for Generalizable Person Re-identification
Aug 17, 2023



This paper aims to learn a domain-generalizable (DG) person re-identification (ReID) representation from large-scale videos \textbf{without any annotation}. Prior DG ReID methods employ limited labeled data for training due to the high cost of annotation, which restricts further advances. To overcome the barriers of data and annotation, we propose to utilize large-scale unsupervised data for training. The key issue lies in how to mine identity information. To this end, we propose an Identity-seeking Self-supervised Representation learning (ISR) method. ISR constructs positive pairs from inter-frame images by modeling the instance association as a maximum-weight bipartite matching problem. A reliability-guided contrastive loss is further presented to suppress the adverse impact of noisy positive pairs, ensuring that reliable positive pairs dominate the learning process. The training cost of ISR scales approximately linearly with the data size, making it feasible to utilize large-scale data for training. The learned representation exhibits superior generalization ability. \textbf{Without human annotation and fine-tuning, ISR achieves 87.0\% Rank-1 on Market-1501 and 56.4\% Rank-1 on MSMT17}, outperforming the best supervised domain-generalizable method by 5.0\% and 19.5\%, respectively. In the pre-training$\rightarrow$fine-tuning scenario, ISR achieves state-of-the-art performance, with 88.4\% Rank-1 on MSMT17. The code is at \url{https://github.com/dcp15/ISR_ICCV2023_Oral}.
Generalizable Re-Identification from Videos with Cycle Association
Nov 08, 2022In this paper, we are interested in learning a generalizable person re-identification (re-ID) representation from unlabeled videos. Compared with 1) the popular unsupervised re-ID setting where the training and test sets are typically under the same domain, and 2) the popular domain generalization (DG) re-ID setting where the training samples are labeled, our novel scenario combines their key challenges: the training samples are unlabeled, and collected form various domains which do no align with the test domain. In other words, we aim to learn a representation in an unsupervised manner and directly use the learned representation for re-ID in novel domains. To fulfill this goal, we make two main contributions: First, we propose Cycle Association (CycAs), a scalable self-supervised learning method for re-ID with low training complexity; and second, we construct a large-scale unlabeled re-ID dataset named LMP-video, tailored for the proposed method. Specifically, CycAs learns re-ID features by enforcing cycle consistency of instance association between temporally successive video frame pairs, and the training cost is merely linear to the data size, making large-scale training possible. On the other hand, the LMP-video dataset is extremely large, containing 50 million unlabeled person images cropped from over 10K Youtube videos, therefore is sufficient to serve as fertile soil for self-supervised learning. Trained on LMP-video, we show that CycAs learns good generalization towards novel domains. The achieved results sometimes even outperform supervised domain generalizable models. Remarkably, CycAs achieves 82.2% Rank-1 on Market-1501 and 49.0% Rank-1 on MSMT17 with zero human annotation, surpassing state-of-the-art supervised DG re-ID methods. Moreover, we also demonstrate the superiority of CycAs under the canonical unsupervised re-ID and the pretrain-and-finetune scenarios.
Reliability-Aware Prediction via Uncertainty Learning for Person Image Retrieval
Oct 24, 2022Current person image retrieval methods have achieved great improvements in accuracy metrics. However, they rarely describe the reliability of the prediction. In this paper, we propose an Uncertainty-Aware Learning (UAL) method to remedy this issue. UAL aims at providing reliability-aware predictions by considering data uncertainty and model uncertainty simultaneously. Data uncertainty captures the ``noise" inherent in the sample, while model uncertainty depicts the model's confidence in the sample's prediction. Specifically, in UAL, (1) we propose a sampling-free data uncertainty learning method to adaptively assign weights to different samples during training, down-weighting the low-quality ambiguous samples. (2) we leverage the Bayesian framework to model the model uncertainty by assuming the parameters of the network follow a Bernoulli distribution. (3) the data uncertainty and the model uncertainty are jointly learned in a unified network, and they serve as two fundamental criteria for the reliability assessment: if a probe is high-quality (low data uncertainty) and the model is confident in the prediction of the probe (low model uncertainty), the final ranking will be assessed as reliable. Experiments under the risk-controlled settings and the multi-query settings show the proposed reliability assessment is effective. Our method also shows superior performance on three challenging benchmarks under the vanilla single query settings.
Portrait Interpretation and a Benchmark
Jul 27, 2022We propose a task we name Portrait Interpretation and construct a dataset named Portrait250K for it. Current researches on portraits such as human attribute recognition and person re-identification have achieved many successes, but generally, they: 1) may lack mining the interrelationship between various tasks and the possible benefits it may bring; 2) design deep models specifically for each task, which is inefficient; 3) may be unable to cope with the needs of a unified model and comprehensive perception in actual scenes. In this paper, the proposed portrait interpretation recognizes the perception of humans from a new systematic perspective. We divide the perception of portraits into three aspects, namely Appearance, Posture, and Emotion, and design corresponding sub-tasks for each aspect. Based on the framework of multi-task learning, portrait interpretation requires a comprehensive description of static attributes and dynamic states of portraits. To invigorate research on this new task, we construct a new dataset that contains 250,000 images labeled with identity, gender, age, physique, height, expression, and posture of the whole body and arms. Our dataset is collected from 51 movies, hence covering extensive diversity. Furthermore, we focus on representation learning for portrait interpretation and propose a baseline that reflects our systematic perspective. We also propose an appropriate metric for this task. Our experimental results demonstrate that combining the tasks related to portrait interpretation can yield benefits. Code and dataset will be made public.
Deep Representation Learning on Long-tailed Data: A Learnable Embedding Augmentation Perspective
Feb 26, 2020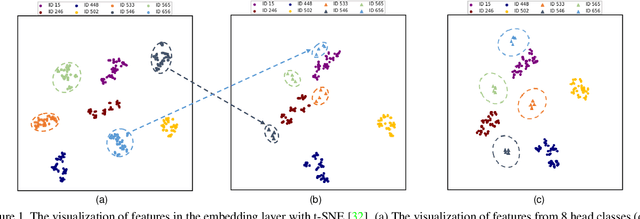
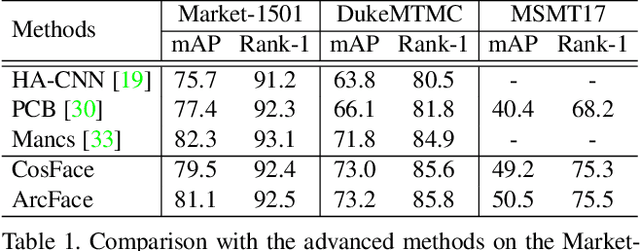
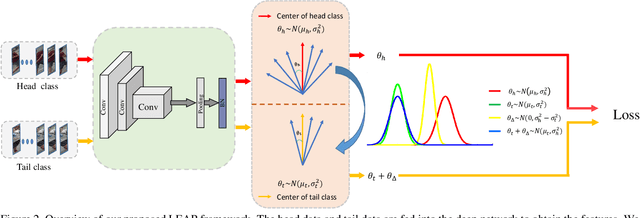

This paper considers learning deep features from long-tailed data. We observe that in the deep feature space, the head classes and the tail classes present different distribution patterns. The head classes have a relatively large spatial span, while the tail classes have significantly small spatial span, due to the lack of intra-class diversity. This uneven distribution between head and tail classes distorts the overall feature space, which compromises the discriminative ability of the learned features. Intuitively, we seek to expand the distribution of the tail classes by transferring from the head classes, so as to alleviate the distortion of the feature space. To this end, we propose to construct each feature into a "feature cloud". If a sample belongs to a tail class, the corresponding feature cloud will have relatively large distribution range, in compensation to its lack of diversity. It allows each tail sample to push the samples from other classes far away, recovering the intra-class diversity of tail classes. Extensive experimental evaluations on person re-identification and face recognition tasks confirm the effectiveness of our method.