 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint3D: tracking actions as moving points with 3D CNNs
Paper and Code
Mar 20, 2022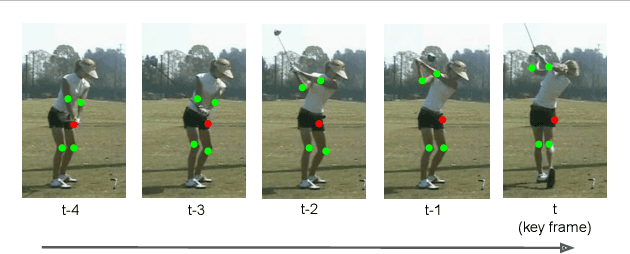
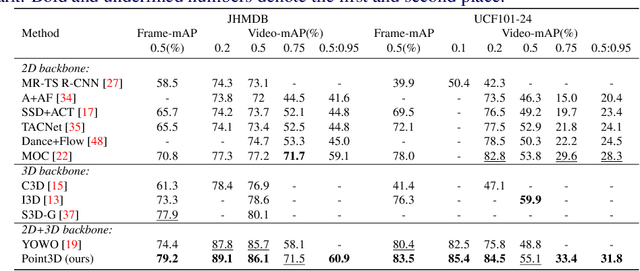
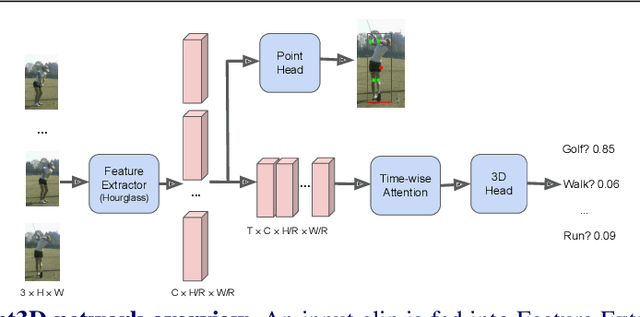

Spatio-temporal action recognition has been a challenging task that involves detecting where and when actions occur. Current state-of-the-art action detectors are mostly anchor-based, requiring sensitive anchor designs and huge computations due to calculating large numbers of anchor boxes. Motivated by nascent anchor-free approaches, we propose Point3D, a flexible and computationally efficient network with high precision for spatio-temporal action recognition. Our Point3D consists of a Point Head for action localization and a 3D Head for action classification. Firstly, Point Head is used to track center points and knot key points of humans to localize the bounding box of an action. These location features are then piped into a time-wise attention to learn long-range dependencies across frames. The 3D Head is later deployed for the final action classification. Our Point3D achieves state-of-the-art performance on the JHMDB, UCF101-24, and AVA benchmarks in terms of frame-mAP and video-mAP. Comprehensive ablation studies also demonstrate the effectiveness of each module proposed in our Point3D.