 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPL: Empirical Prototype Learning for Deep Face Recognition
May 21, 2024Prototype learning is widely used in face recognition, which takes the row vectors of coefficient matrix in the last linear layer of the feature extraction model as the prototypes for each class. When the prototypes are updated using the facial sample feature gradients in the model training, they are prone to being pulled away from the class center by the hard samples, resulting in decreased overall model performance. In this paper, we explicitly define prototypes as the expectations of sample features in each class and design the empirical prototypes using the existing samples in the dataset. We then devise a strategy to adaptively update these empirical prototypes during the model training based on the similarity between the sample features and the empirical prototypes. Furthermore, we propose an empirical prototype learning (EPL) method, which utilizes an adaptive margin parameter with respect to sample features. EPL assigns larger margins to the normal samples and smaller margins to the hard samples, allowing the learned empirical prototypes to better reflect the class center dominated by the normal samples and finally pull the hard samples towards the empirical prototypes through the learning. The extensive experiments on MFR, IJB-C, LFW, CFP-FP, AgeDB, and MegaFace demonstrate the effectiveness of EPL. Our code is available at $\href{https://github.com/WakingHours-GitHub/EPL}{https://github.com/WakingHours-GitHub/EPL}$.
Rediscovering BCE Loss for Uniform Classification
Mar 12, 2024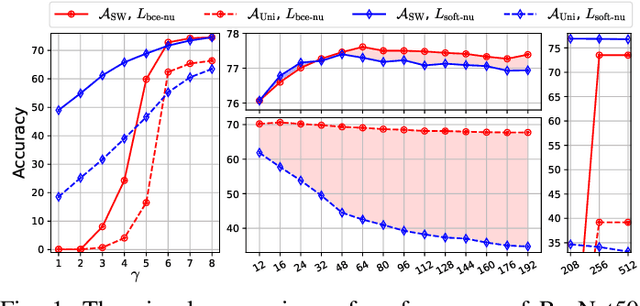
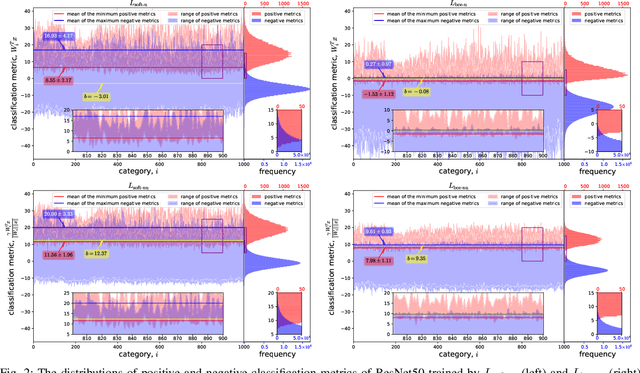

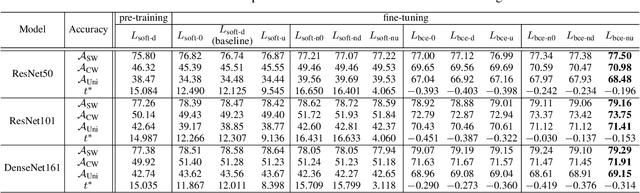
This paper introduces the concept of uniform classification, which employs a unified threshold to classify all samples rather than adaptive threshold classifying each individual sample. We also propose the uniform classification accuracy as a metric to measure the model's performance in uniform classification. Furthermore, begin with a naive loss, we mathematically derive a loss function suitable for the uniform classification, which is the BCE function integrated with a unified bias. We demonstrate the unified threshold could be learned via the bias. The extensive experiments on six classification datasets and three feature extraction models show that, compared to the SoftMax loss, the models trained with the BCE loss not only exhibit higher uniform classification accuracy but also higher sample-wise classification accuracy. In addition, the learned bias from BCE loss is very close to the unified threshold used in the uniform classification. The features extracted by the models trained with BCE loss not only possess uniformity but also demonstrate better intra-class compactness and inter-class distinctiveness, yielding superior performance on open-set tasks such as face recognition.
UniTSFace: Unified Threshold Integrated Sample-to-Sample Loss for Face Recognition
Nov 04, 2023



Sample-to-class-based face recognition models can not fully explore the cross-sample relationship among large amounts of facial images, while sample-to-sample-based models require sophisticated pairing processes for training. Furthermore, neither method satisfies the requirements of real-world face verification applications, which expect a unified threshold separating positive from negative facial pairs. In this paper, we propose a unified threshold integrated sample-to-sample based loss (USS loss), which features an explicit unified threshold for distinguishing positive from negative pairs. Inspired by our USS loss, we also derive the sample-to-sample based softmax and BCE losses, and discuss their relationship. Extensive evaluation on multiple benchmark datasets, including MFR, IJB-C, LFW, CFP-FP, AgeDB, and MegaFace, demonstrates that the proposed USS loss is highly efficient and can work seamlessly with sample-to-class-based losses. The embedded loss (USS and sample-to-class Softmax loss) overcomes the pitfalls of previous approaches and the trained facial model UniTSFace exhibits exceptional performance, outperforming state-of-the-art methods, such as CosFace, ArcFace, VPL, AnchorFace, and UNPG. Our code is available.