 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Context Transformer for Multi-level Semantic Scene Understanding
Feb 21, 2025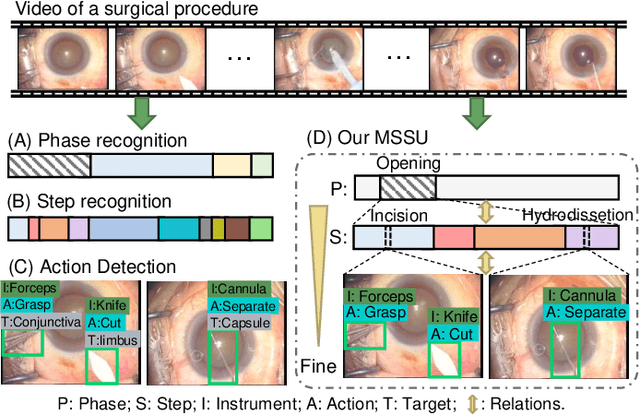

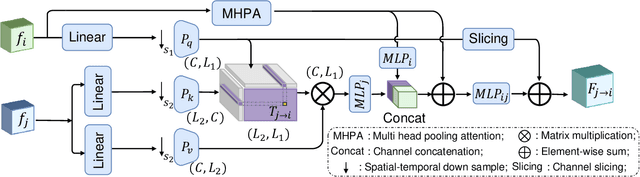

A comprehensive and explicit understanding of surgical scenes plays a vital role in developing context-aware computer-assisted systems in the operating theatre. However, few works provide systematical analysis to enable hierarchical surgical scene understanding. In this work, we propose to represent the tasks set [phase recognition --> step recognition --> action and instrument detection] as multi-level semantic scene understanding (MSSU). For this target, we propose a novel hierarchical context transformer (HCT) network and thoroughly explore the relations across the different level tasks. Specifically, a hierarchical relation aggregation module (HRAM) is designed to concurrently relate entries inside multi-level interaction information and then augment task-specific features. To further boost the representation learning of the different tasks, inter-task contrastive learning (ICL) is presented to guide the model to learn task-wise features via absorbing complementary information from other tasks. Furthermore, considering the computational costs of the transformer, we propose HCT+ to integrate the spatial and temporal adapter to access competitive performance on substantially fewer tunable parameters. Extensive experiments on our cataract dataset and a publicly available endoscopic PSI-AVA dataset demonstrate the outstanding performance of our method, consistently exceeding the state-of-the-art methods by a large margin. The code is available at https://github.com/Aurora-hao/HCT.
ACT-Net: Anchor-context Action Detection in Surgery Videos
Oct 05, 2023Recognition and localization of surgical detailed actions is an essential component of developing a context-aware decision support system. However, most existing detection algorithms fail to provide high-accuracy action classes even having their locations, as they do not consider the surgery procedure's regularity in the whole video. This limitation hinders their application. Moreover, implementing the predictions in clinical applications seriously needs to convey model confidence to earn entrustment, which is unexplored in surgical action prediction. In this paper, to accurately detect fine-grained actions that happen at every moment, we propose an anchor-context action detection network (ACTNet), including an anchor-context detection (ACD) module and a class conditional diffusion (CCD) module, to answer the following questions: 1) where the actions happen; 2) what actions are; 3) how confidence predictions are. Specifically, the proposed ACD module spatially and temporally highlights the regions interacting with the extracted anchor in surgery video, which outputs action location and its class distribution based on anchor-context interactions. Considering the full distribution of action classes in videos, the CCD module adopts a denoising diffusion-based generative model conditioned on our ACD estimator to further reconstruct accurately the action predictions. Moreover, we utilize the stochastic nature of the diffusion model outputs to access model confidence for each prediction. Our method reports the state-of-the-art performance, with improvements of 4.0% mAP against baseline on the surgical video dataset.