 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Sep 11, 2025Vision-Language-Action (VLA) models have recently emerged as a powerful paradigm for robotic manipulation. Despite substantial progress enabled by large-scale pretraining and supervised fine-tuning (SFT), these models face two fundamental challenges: (i) the scarcity and high cost of large-scale human-operated robotic trajectories required for SFT scaling, and (ii) limited generalization to tasks involving distribution shift. Recent breakthroughs in Large Reasoning Models (LRMs) demonstrate that reinforcement learning (RL) can dramatically enhance step-by-step reasoning capabilities, raising a natural question: Can RL similarly improve the long-horizon step-by-step action planning of VLA? In this work, we introduce SimpleVLA-RL, an efficient RL framework tailored for VLA models. Building upon veRL, we introduce VLA-specific trajectory sampling, scalable parallelization, multi-environment rendering, and optimized loss computation. When applied to OpenVLA-OFT, SimpleVLA-RL achieves SoTA performance on LIBERO and even outperforms $\pi_0$ on RoboTwin 1.0\&2.0 with the exploration-enhancing strategies we introduce. SimpleVLA-RL not only reduces dependence on large-scale data and enables robust generalization, but also remarkably surpasses SFT in real-world tasks. Moreover, we identify a novel phenomenon ``pushcut'' during RL training, wherein the policy discovers previously unseen patterns beyond those seen in the previous training process. Github: https://github.com/PRIME-RL/SimpleVLA-RL
GROVE: A Generalized Reward for Learning Open-Vocabulary Physical Skill
Apr 05, 2025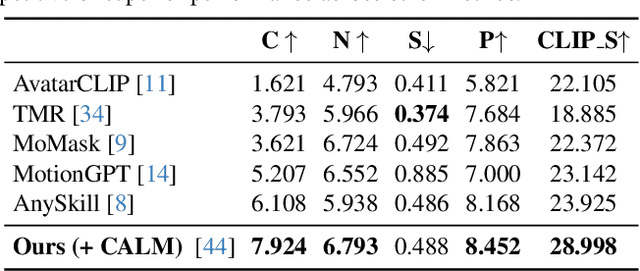
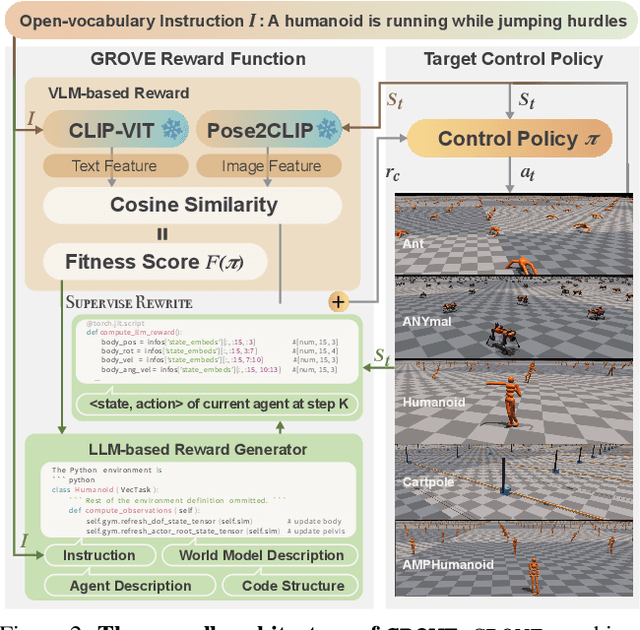
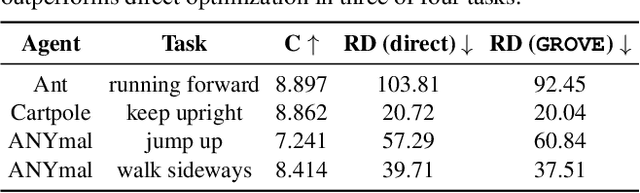

Learning open-vocabulary physical skills for simulated agents presents a significant challenge in artificial intelligence. Current reinforcement learning approaches face critical limitations: manually designed rewards lack scalability across diverse tasks, while demonstration-based methods struggle to generalize beyond their training distribution. We introduce GROVE, a generalized reward framework that enables open-vocabulary physical skill learning without manual engineering or task-specific demonstrations. Our key insight is that Large Language Models(LLMs) and Vision Language Models(VLMs) provide complementary guidance -- LLMs generate precise physical constraints capturing task requirements, while VLMs evaluate motion semantics and naturalness. Through an iterative design process, VLM-based feedback continuously refines LLM-generated constraints, creating a self-improving reward system. To bridge the domain gap between simulation and natural images, we develop Pose2CLIP, a lightweight mapper that efficiently projects agent poses directly into semantic feature space without computationally expensive rendering. Extensive experiments across diverse embodiments and learning paradigms demonstrate GROVE's effectiveness, achieving 22.2% higher motion naturalness and 25.7% better task completion scores while training 8.4x faster than previous methods. These results establish a new foundation for scalable physical skill acquisition in simulated environments.
Multi-hop Reading Comprehension across Documents with Path-based Graph Convolutional Network
Jun 12, 2020
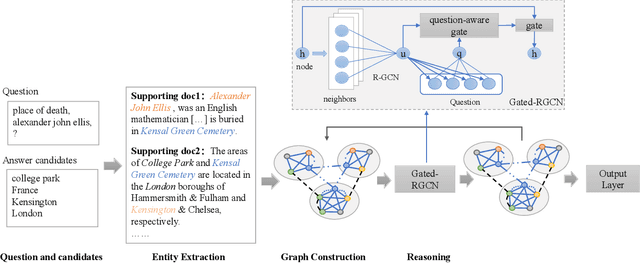

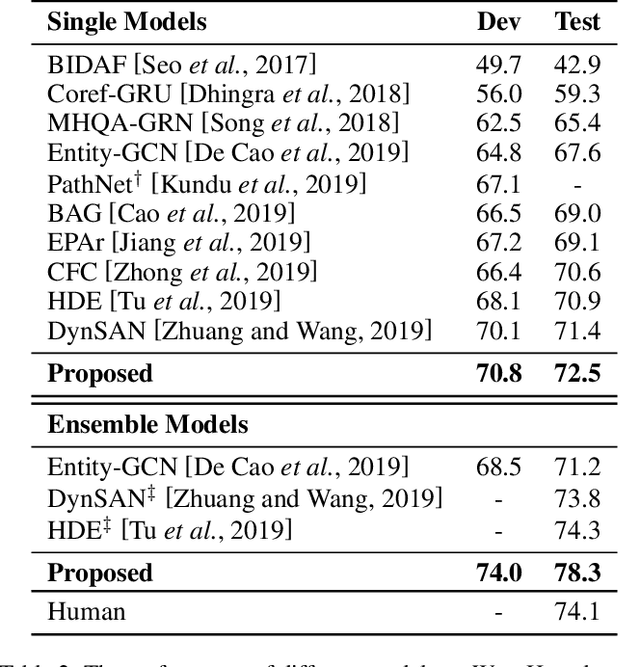
Multi-hop reading comprehension across multiple documents attracts much attention recently. In this paper, we propose a novel approach to tackle this multi-hop reading comprehension problem. Inspired by human reasoning processing, we construct a path-based reasoning graph from supporting documents. This graph can combine both the idea of the graph-based and path-based approaches, so it is better for multi-hop reasoning. Meanwhile, we propose Gated-RGCN to accumulate evidence on the path-based reasoning graph, which contains a new question-aware gating mechanism to regulate the usefulness of information propagating across documents and add question information during reasoning. We evaluate our approach on WikiHop dataset, and our approach achieves state-of-the-art accuracy against previously published approaches. Especially, our ensemble model surpasses human performance by 4.2%.