 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Large Language Models Generated Texts: A Multi-Level Fine-Grained Detection Framework
Oct 18, 2024



Large language models (LLMs) have transformed human writing by enhancing grammar correction, content expansion, and stylistic refinement. However, their widespread use raises concerns about authorship, originality, and ethics, even potentially threatening scholarly integrity. Existing detection methods, which mainly rely on single-feature analysis and binary classification, often fail to effectively identify LLM-generated text in academic contexts. To address these challenges, we propose a novel Multi-level Fine-grained Detection (MFD) framework that detects LLM-generated text by integrating low-level structural, high-level semantic, and deep-level linguistic features, while conducting sentence-level evaluations of lexicon, grammar, and syntax for comprehensive analysis. To improve detection of subtle differences in LLM-generated text and enhance robustness against paraphrasing, we apply two mainstream evasion techniques to rewrite the text. These variations, along with original texts, are used to train a text encoder via contrastive learning, extracting high-level semantic features of sentence to boost detection generalization. Furthermore, we leverage advanced LLM to analyze the entire text and extract deep-level linguistic features, enhancing the model's ability to capture complex patterns and nuances while effectively incorporating contextual information. Extensive experiments on public datasets show that the MFD model outperforms existing methods, achieving an MAE of 0.1346 and an accuracy of 88.56%. Our research provides institutions and publishers with an effective mechanism to detect LLM-generated text, mitigating risks of compromised authorship. Educators and editors can use the model's predictions to refine verification and plagiarism prevention protocols, ensuring adherence to standards.
CUDRT: Benchmarking the Detection of Human vs. Large Language Models Generated Texts
Jun 13, 2024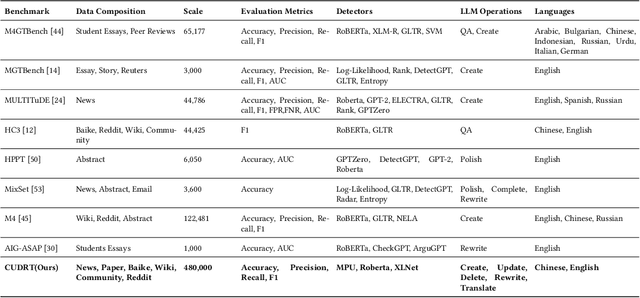
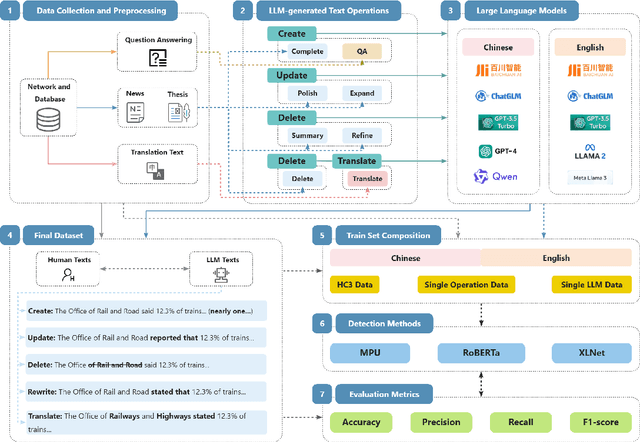
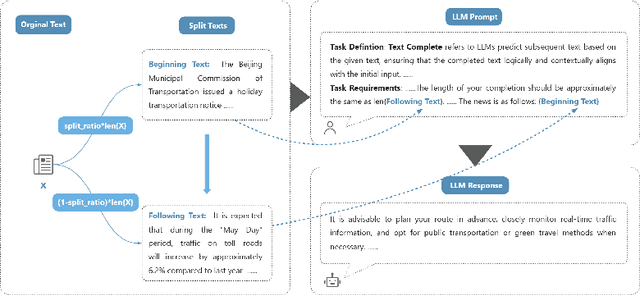
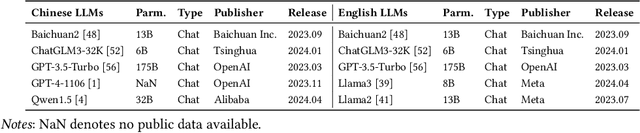
The proliferation of large language models (LLMs) has significantly enhanced text generation capabilities across various industries. However, these models' ability to generate human-like text poses substantial challenges in discerning between human and AI authorship. Despite the effectiveness of existing AI-generated text detectors, their development is hindered by the lack of comprehensive, publicly available benchmarks. Current benchmarks are limited to specific scenarios, such as question answering and text polishing, and predominantly focus on English texts, failing to capture the diverse applications and linguistic nuances of LLMs. To address these limitations, this paper constructs a comprehensive bilingual benchmark in both Chinese and English to evaluate mainstream AI-generated text detectors. We categorize LLM text generation into five distinct operations: Create, Update, Delete, Rewrite, and Translate (CUDRT), encompassing all current LLMs activities. We also establish a robust benchmark evaluation framework to support scalable and reproducible experiments. For each CUDRT category, we have developed extensive datasets to thoroughly assess detector performance. By employing the latest mainstream LLMs specific to each language, our datasets provide a thorough evaluation environment. Extensive experimental results offer critical insights for optimizing AI-generated text detectors and suggest future research directions to improve detection accuracy and generalizability across various scenarios.
Fake Artificial Intelligence Generated Contents (FAIGC): A Survey of Theories, Detection Methods, and Opportunities
Apr 25, 2024



In recent years, generative artificial intelligence models, represented by Large Language Models (LLMs) and Diffusion Models (DMs), have revolutionized content production methods. These artificial intelligence-generated content (AIGC) have become deeply embedded in various aspects of daily life and work, spanning texts, images, videos, and audio. The authenticity of AI-generated content is progressively enhancing, approaching human-level creative standards. However, these technologies have also led to the emergence of Fake Artificial Intelligence Generated Content (FAIGC), posing new challenges in distinguishing genuine information. It is crucial to recognize that AIGC technology is akin to a double-edged sword; its potent generative capabilities, while beneficial, also pose risks for the creation and dissemination of FAIGC. In this survey, We propose a new taxonomy that provides a more comprehensive breakdown of the space of FAIGC methods today. Next, we explore the modalities and generative technologies of FAIGC, categorized under AI-generated disinformation and AI-generated misinformation. From various perspectives, we then introduce FAIGC detection methods, including Deceptive FAIGC Detection, Deepfake Detection, and Hallucination-based FAIGC Detection. Finally, we discuss outstanding challenges and promising areas for future research.
CAT-LLM: Prompting Large Language Models with Text Style Definition for Chinese Article-style Transfer
Jan 11, 2024



Text style transfer is increasingly prominent in online entertainment and social media. However, existing research mainly concentrates on style transfer within individual English sentences, while ignoring the complexity of long Chinese texts, which limits the wider applicability of style transfer in digital media realm. To bridge this gap, we propose a Chinese Article-style Transfer framework (CAT-LLM), leveraging the capabilities of Large Language Models (LLMs). CAT-LLM incorporates a bespoke, pluggable Text Style Definition (TSD) module aimed at comprehensively analyzing text features in articles, prompting LLMs to efficiently transfer Chinese article-style. The TSD module integrates a series of machine learning algorithms to analyze article-style from both words and sentences levels, thereby aiding LLMs thoroughly grasp the target style without compromising the integrity of the original text. In addition, this module supports dynamic expansion of internal style trees, showcasing robust compatibility and allowing flexible optimization in subsequent research. Moreover, we select five Chinese articles with distinct styles and create five parallel datasets using ChatGPT, enhancing the models' performance evaluation accuracy and establishing a novel paradigm for evaluating subsequent research on article-style transfer. Extensive experimental results affirm that CAT-LLM outperforms current research in terms of transfer accuracy and content preservation, and has remarkable applicability to various types of LLMs.