 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUDRT: Benchmarking the Detection of Human vs. Large Language Models Generated Texts
Paper and Code
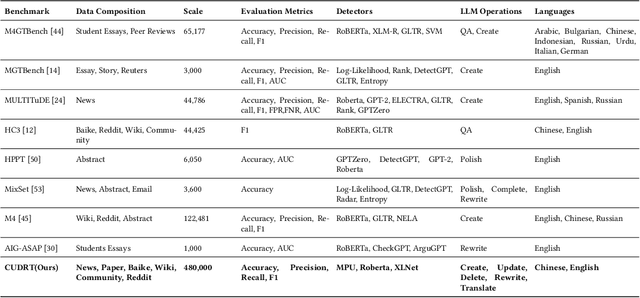
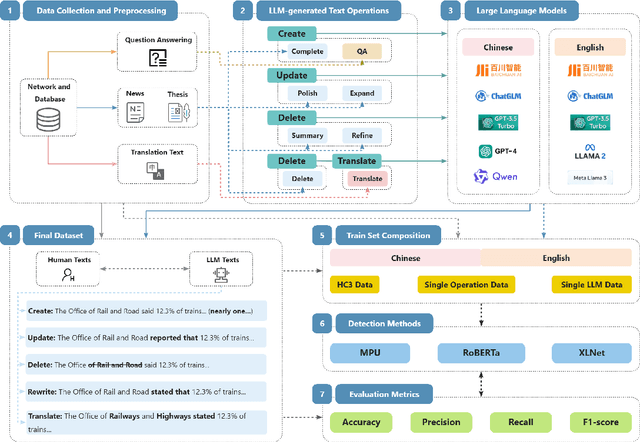
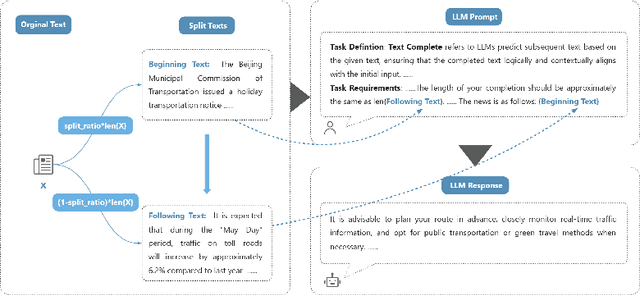
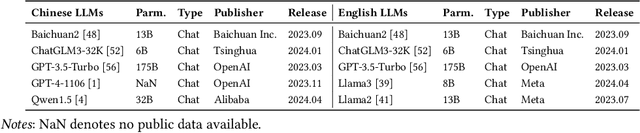
The proliferation of large language models (LLMs) has significantly enhanced text generation capabilities across various industries. However, these models' ability to generate human-like text poses substantial challenges in discerning between human and AI authorship. Despite the effectiveness of existing AI-generated text detectors, their development is hindered by the lack of comprehensive, publicly available benchmarks. Current benchmarks are limited to specific scenarios, such as question answering and text polishing, and predominantly focus on English texts, failing to capture the diverse applications and linguistic nuances of LLMs. To address these limitations, this paper constructs a comprehensive bilingual benchmark in both Chinese and English to evaluate mainstream AI-generated text detectors. We categorize LLM text generation into five distinct operations: Create, Update, Delete, Rewrite, and Translate (CUDRT), encompassing all current LLMs activities. We also establish a robust benchmark evaluation framework to support scalable and reproducible experiments. For each CUDRT category, we have developed extensive datasets to thoroughly assess detector performance. By employing the latest mainstream LLMs specific to each language, our datasets provide a thorough evaluation environment. Extensive experimental results offer critical insights for optimizing AI-generated text detectors and suggest future research directions to improve detection accuracy and generalizability across various scenarios.