 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreenFlow: A Computation Allocation Framework for Building Environmentally Sound Recommendation System
Dec 15, 2023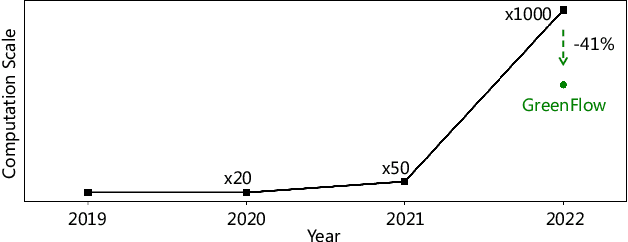
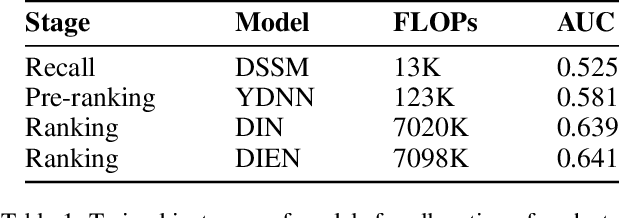
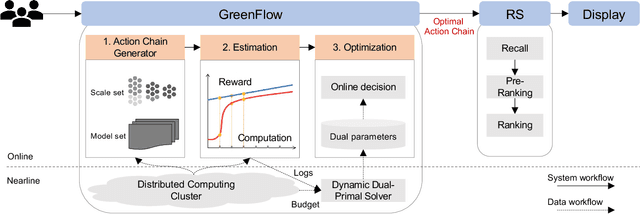
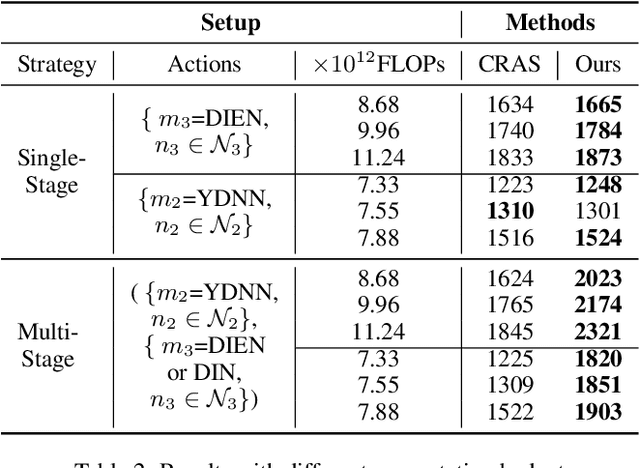
Given the enormous number of users and items, industrial cascade recommendation systems (RS) are continuously expanded in size and complexity to deliver relevant items, such as news, services, and commodities, to the appropriate users. In a real-world scenario with hundreds of thousands requests per second, significant computation is required to infer personalized results for each request, resulting in a massive energy consumption and carbon emission that raises concern. This paper proposes GreenFlow, a practical computation allocation framework for RS, that considers both accuracy and carbon emission during inference. For each stage (e.g., recall, pre-ranking, ranking, etc.) of a cascade RS, when a user triggers a request, we define two actions that determine the computation: (1) the trained instances of models with different computational complexity; and (2) the number of items to be inferred in the stage. We refer to the combinations of actions in all stages as action chains. A reward score is estimated for each action chain, followed by dynamic primal-dual optimization considering both the reward and computation budget. Extensive experiments verify the effectiveness of the framework, reducing computation consumption by 41% in an industrial mobile application while maintaining commercial revenue. Moreover, the proposed framework saves approximately 5000kWh of electricity and reduces 3 tons of carbon emissions per day.
Adversarial Learning for Incentive Optimization in Mobile Payment Marketing
Dec 28, 2021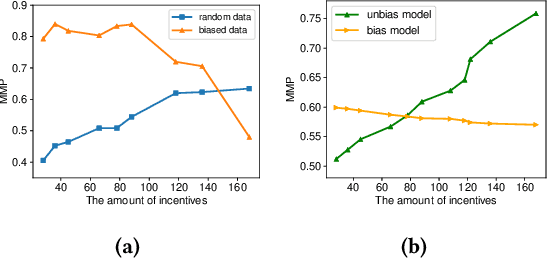
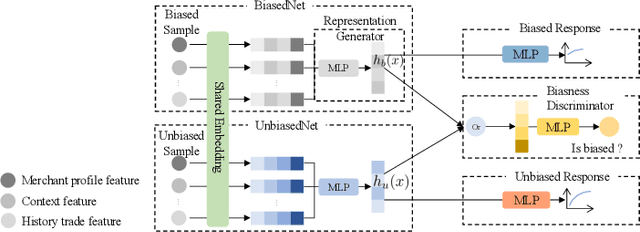
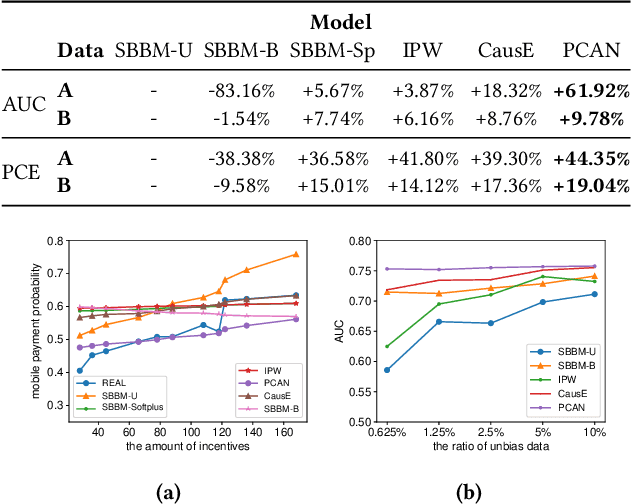
Many payment platforms hold large-scale marketing campaigns, which allocate incentives to encourage users to pay through their applications. To maximize the return on investment, incentive allocations are commonly solved in a two-stage procedure. After training a response estimation model to estimate the users' mobile payment probabilities (MPP), a linear programming process is applied to obtain the optimal incentive allocation. However, the large amount of biased data in the training set, generated by the previous biased allocation policy, causes a biased estimation. This bias deteriorates the performance of the response model and misleads the linear programming process, dramatically degrading the performance of the resulting allocation policy. To overcome this obstacle, we propose a bias correction adversarial network. Our method leverages the small set of unbiased data obtained under a full-randomized allocation policy to train an unbiased model and then uses it to reduce the bias with adversarial learning. Offline and online experimental results demonstrate that our method outperforms state-of-the-art approaches and significantly improves the performance of the resulting allocation policy in a real-world marketing campaign.