 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Rare Word Representations using Semantic Bridging
Paper and Code
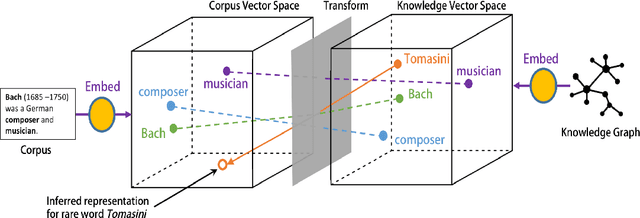

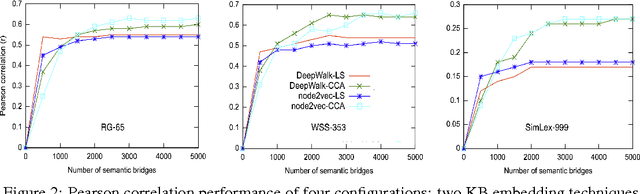

We propose a methodology that adapts graph embedding techniques (DeepWalk (Perozzi et al., 2014) and node2vec (Grover and Leskovec, 2016)) as well as cross-lingual vector space mapping approaches (Least Squares and Canonical Correlation Analysis) in order to merge the corpus and ontological sources of lexical knowledge. We also perform comparative analysis of the used algorithms in order to identify the best combination for the proposed system. We then apply this to the task of enhancing the coverage of an existing word embedding's vocabulary with rare and unseen words. We show that our technique can provide considerable extra coverage (over 99%), leading to consistent performance gain (around 10% absolute gain is achieved with w2v-gn-500K cf.\S 3.3) on the Rare Word Similarity dataset.