 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnseen Word Representation by Aligning Heterogeneous Lexical Semantic Spaces
Paper and Code
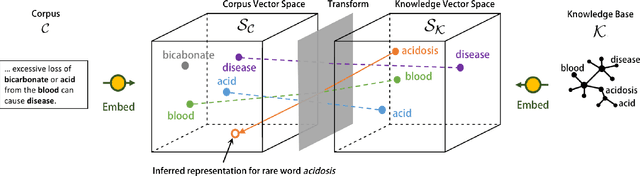

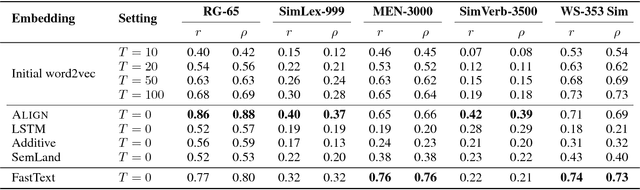
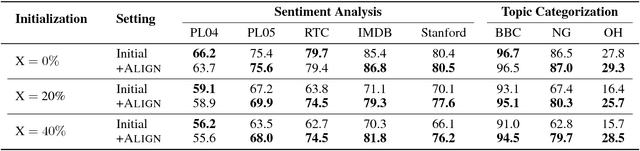
Word embedding techniques heavily rely on the abundance of training data for individual words. Given the Zipfian distribution of words in natural language texts, a large number of words do not usually appear frequently or at all in the training data. In this paper we put forward a technique that exploits the knowledge encoded in lexical resources, such as WordNet, to induce embeddings for unseen words. Our approach adapts graph embedding and cross-lingual vector space transformation techniques in order to merge lexical knowledge encoded in ontologies with that derived from corpus statistics. We show that the approach can provide consistent performance improvements across multiple evaluation benchmarks: in-vitro, on multiple rare word similarity datasets, and in-vivo, in two downstream text classification tasks.