 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3K: Self-Supervised Semantic Keypoints for Robotic Manipulation via Multi-View Consistency
Oct 13, 2020

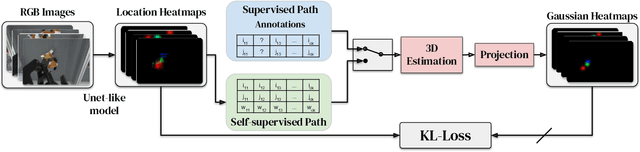
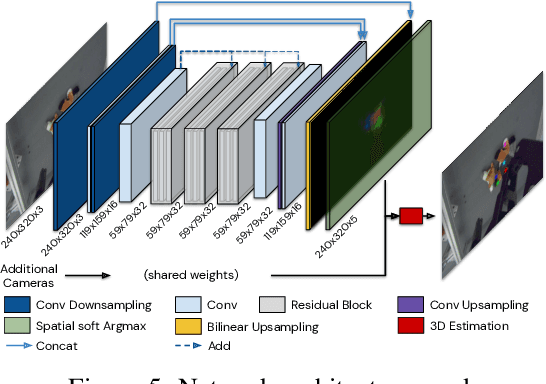
A robot's ability to act is fundamentally constrained by what it can perceive. Many existing approaches to visual representation learning utilize general-purpose training criteria, e.g. image reconstruction, smoothness in latent space, or usefulness for control, or else make use of large datasets annotated with specific features (bounding boxes, segmentations, etc.). However, both approaches often struggle to capture the fine-detail required for precision tasks on specific objects, e.g. grasping and mating a plug and socket. We argue that these difficulties arise from a lack of geometric structure in these models. In this work we advocate semantic 3D keypoints as a visual representation, and present a semi-supervised training objective that can allow instance or category-level keypoints to be trained to 1-5 millimeter-accuracy with minimal supervision. Furthermore, unlike local texture-based approaches, our model integrates contextual information from a large area and is therefore robust to occlusion, noise, and lack of discernible texture. We demonstrate that this ability to locate semantic keypoints enables high level scripting of human understandable behaviours. Finally we show that these keypoints provide a good way to define reward functions for reinforcement learning and are a good representation for training agents.
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
Oct 08, 2018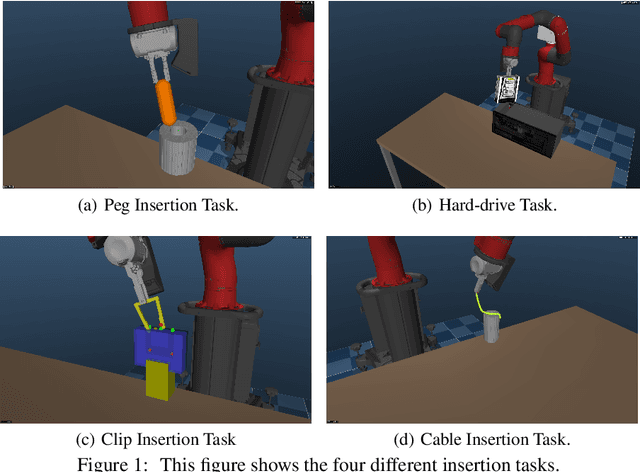

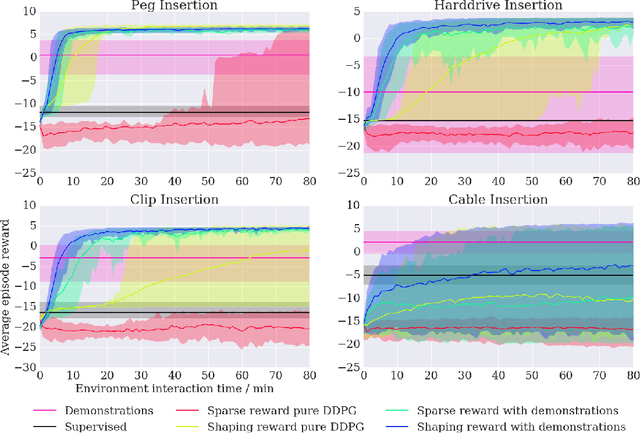
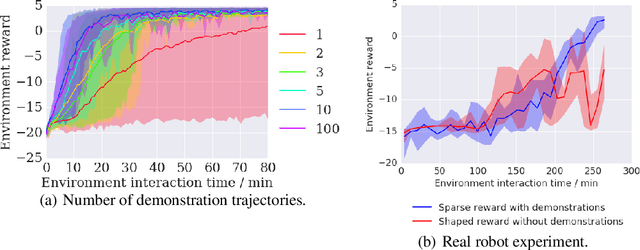
We propose a general and model-free approach for Reinforcement Learning (RL) on real robotics with sparse rewards. We build upon the Deep Deterministic Policy Gradient (DDPG) algorithm to use demonstrations. Both demonstrations and actual interactions are used to fill a replay buffer and the sampling ratio between demonstrations and transitions is automatically tuned via a prioritized replay mechanism. Typically, carefully engineered shaping rewards are required to enable the agents to efficiently explore on high dimensional control problems such as robotics. They are also required for model-based acceleration methods relying on local solvers such as iLQG (e.g. Guided Policy Search and Normalized Advantage Function). The demonstrations replace the need for carefully engineered rewards, and reduce the exploration problem encountered by classical RL approaches in these domains. Demonstrations are collected by a robot kinesthetically force-controlled by a human demonstrator. Results on four simulated insertion tasks show that DDPG from demonstrations out-performs DDPG, and does not require engineered rewards. Finally, we demonstrate the method on a real robotics task consisting of inserting a clip (flexible object) into a rigid object.
A Practical Approach to Insertion with Variable Socket Position Using Deep Reinforcement Learning
Oct 08, 2018
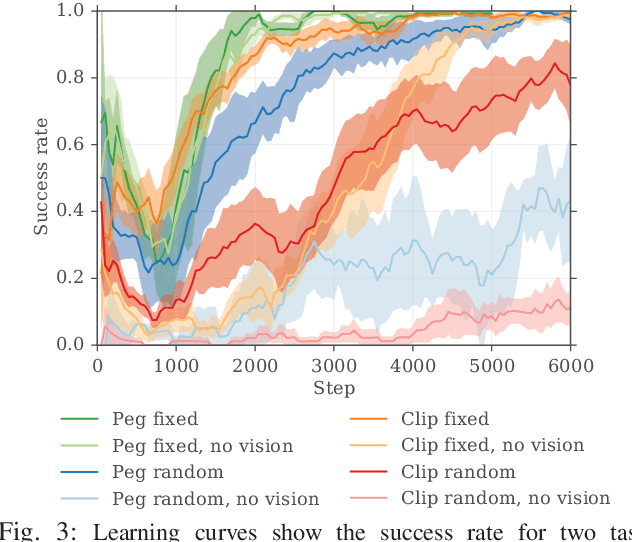
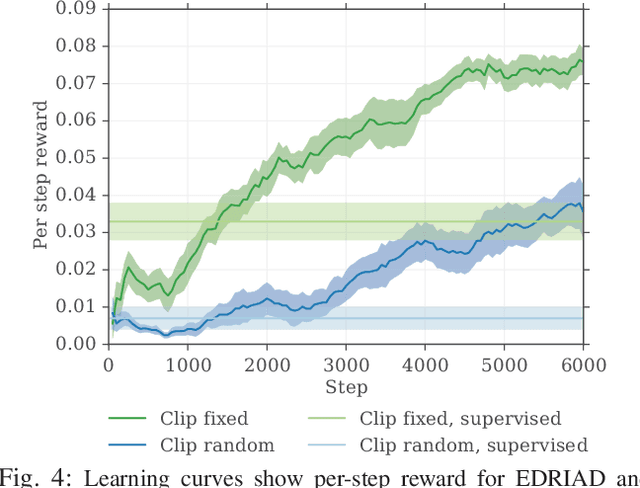
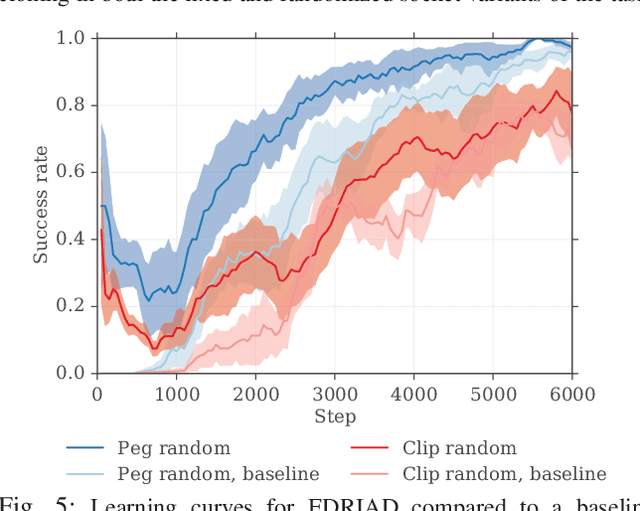
Insertion is a challenging haptic and visual control problem with significant practical value for manufacturing. Existing approaches in the model-based robotics community can be highly effective when task geometry is known, but are complex and cumbersome to implement, and must be tailored to each individual problem by a qualified engineer. Within the learning community there is a long history of insertion research, but existing approaches are typically either too sample-inefficient to run on real robots, or assume access to high-level object features, e.g. socket pose. In this paper we show that relatively minor modifications to an off-the-shelf Deep-RL algorithm (DDPG), combined with a small number of human demonstrations, allows the robot to quickly learn to solve these tasks efficiently and robustly. Our approach requires no modeling or simulation, no parameterized search or alignment behaviors, no vision system aside from raw images, and no reward shaping. We evaluate our approach on a narrow-clearance peg-insertion task and a deformable clip-insertion task, both of which include variability in the socket position. Our results show that these tasks can be solved reliably on the real robot in less than 10 minutes of interaction time, and that the resulting policies are robust to variance in the socket position and orientation.
Sim-to-Real Robot Learning from Pixels with Progressive Nets
May 22, 2018


Applying end-to-end learning to solve complex, interactive, pixel-driven control tasks on a robot is an unsolved problem. Deep Reinforcement Learning algorithms are too slow to achieve performance on a real robot, but their potential has been demonstrated in simulated environments. We propose using progressive networks to bridge the reality gap and transfer learned policies from simulation to the real world. The progressive net approach is a general framework that enables reuse of everything from low-level visual features to high-level policies for transfer to new tasks, enabling a compositional, yet simple, approach to building complex skills. We present an early demonstration of this approach with a number of experiments in the domain of robot manipulation that focus on bridging the reality gap. Unlike other proposed approaches, our real-world experiments demonstrate successful task learning from raw visual input on a fully actuated robot manipulator. Moreover, rather than relying on model-based trajectory optimisation, the task learning is accomplished using only deep reinforcement learning and sparse rewards.
Learning Awareness Models
Apr 17, 2018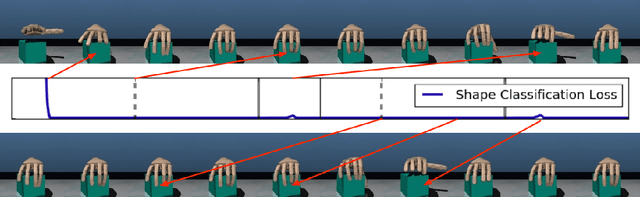

We consider the setting of an agent with a fixed body interacting with an unknown and uncertain external world. We show that models trained to predict proprioceptive information about the agent's body come to represent objects in the external world. In spite of being trained with only internally available signals, these dynamic body models come to represent external objects through the necessity of predicting their effects on the agent's own body. That is, the model learns holistic persistent representations of objects in the world, even though the only training signals are body signals. Our dynamics model is able to successfully predict distributions over 132 sensor readings over 100 steps into the future and we demonstrate that even when the body is no longer in contact with an object, the latent variables of the dynamics model continue to represent its shape. We show that active data collection by maximizing the entropy of predictions about the body---touch sensors, proprioception and vestibular information---leads to learning of dynamic models that show superior performance when used for control. We also collect data from a real robotic hand and show that the same models can be used to answer questions about properties of objects in the real world. Videos with qualitative results of our models are available at https://goo.gl/mZuqAV.