 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikelihood-Free Inference and Hierarchical Data Assimilation for Geological Carbon Storage
Oct 20, 2024
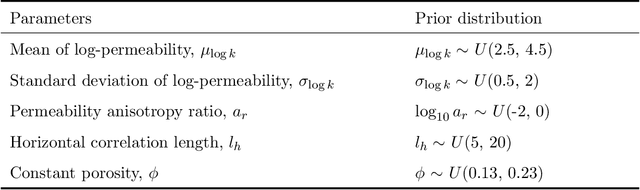


Data assimilation will be essential for the management and expansion of geological carbon storage operations. In traditional data assimilation approaches a fixed set of geological hyperparameters, such as mean and standard deviation of log-permeability, is often assumed. Such hyperparameters, however, may be highly uncertain in practical CO2 storage applications. In this study, we develop a hierarchical data assimilation framework for carbon storage that treats hyperparameters as uncertain variables characterized by hyperprior distributions. To deal with the computationally intractable likelihood function in hyperparameter estimation, we apply a likelihood-free (or simulation-based) inference algorithm, specifically sequential Monte Carlo-based approximate Bayesian computation (SMC-ABC), to draw independent posterior samples of hyperparameters given dynamic monitoring-well data. In the second step we use an ensemble smoother with multiple data assimilation (ESMDA) procedure to provide posterior realizations of grid-block permeability. To reduce computational costs, a 3D recurrent R-U-Net deep-learning surrogate model is applied for forward function evaluations. The accuracy of the surrogate model is established through comparisons to high-fidelity simulation results. A rejection sampling (RS) procedure for data assimilation is applied to provide reference posterior results. Detailed data assimilation results from SMC-ABC-ESMDA are compared to those from the reference RS method. These include marginal posterior distributions of hyperparameters, pairwise posterior samples, and history matching results for pressure and saturation at the monitoring location. Close agreement is achieved with 'converged' RS results, for two synthetic true models, in all quantities considered. Importantly, the SMC-ABC-ESMDA procedure provides speedup of 1-2 orders of magnitude relative to RS for the two cases.
Accelerated training of deep learning surrogate models for surface displacement and flow, with application to MCMC-based history matching of CO2 storage operations
Aug 20, 2024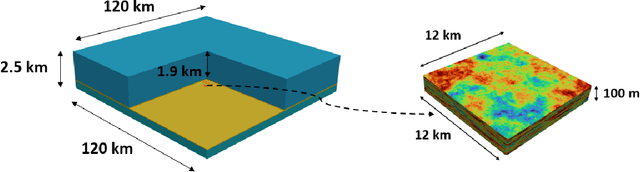


Deep learning surrogate modeling shows great promise for subsurface flow applications, but the training demands can be substantial. Here we introduce a new surrogate modeling framework to predict CO2 saturation, pressure and surface displacement for use in the history matching of carbon storage operations. Rather than train using a large number of expensive coupled flow-geomechanics simulation runs, training here involves a large number of inexpensive flow-only simulations combined with a much smaller number of coupled runs. The flow-only runs use an effective rock compressibility, which is shown to provide accurate predictions for saturation and pressure for our system. A recurrent residual U-Net architecture is applied for the saturation and pressure surrogate models, while a new residual U-Net model is introduced to predict surface displacement. The surface displacement surrogate accepts, as inputs, geomodel quantities along with saturation and pressure surrogate predictions. Median relative error for a diverse test set is less than 4% for all variables. The surrogate models are incorporated into a hierarchical Markov chain Monte Carlo history matching workflow. Surrogate error is included using a new treatment involving the full model error covariance matrix. A high degree of prior uncertainty, with geomodels characterized by uncertain geological scenario parameters (metaparameters) and associated realizations, is considered. History matching results for a synthetic true model are generated using in-situ monitoring-well data only, surface displacement data only, and both data types. The enhanced uncertainty reduction achieved with both data types is quantified. Posterior saturation and surface displacement fields are shown to correspond well with the true solution.
Deep Learning Framework for History Matching CO2 Storage with 4D Seismic and Monitoring Well Data
Aug 02, 2024



Geological carbon storage entails the injection of megatonnes of supercritical CO2 into subsurface formations. The properties of these formations are usually highly uncertain, which makes design and optimization of large-scale storage operations challenging. In this paper we introduce a history matching strategy that enables the calibration of formation properties based on early-time observations. Early-time assessments are essential to assure the operation is performing as planned. Our framework involves two fit-for-purpose deep learning surrogate models that provide predictions for in-situ monitoring well data and interpreted time-lapse (4D) seismic saturation data. These two types of data are at very different scales of resolution, so it is appropriate to construct separate, specialized deep learning networks for their prediction. This approach results in a workflow that is more straightforward to design and more efficient to train than a single surrogate that provides global high-fidelity predictions. The deep learning models are integrated into a hierarchical Markov chain Monte Carlo (MCMC) history matching procedure. History matching is performed on a synthetic case with and without 4D seismic data, which allows us to quantify the impact of 4D seismic on uncertainty reduction. The use of both data types is shown to provide substantial uncertainty reduction in key geomodel parameters and to enable accurate predictions of CO2 plume dynamics. The overall history matching framework developed in this study represents an efficient way to integrate multiple data types and to assess the impact of each on uncertainty reduction and performance predictions.
Latent diffusion models for parameterization and data assimilation of facies-based geomodels
Jun 21, 2024Geological parameterization entails the representation of a geomodel using a small set of latent variables and a mapping from these variables to grid-block properties such as porosity and permeability. Parameterization is useful for data assimilation (history matching), as it maintains geological realism while reducing the number of variables to be determined. Diffusion models are a new class of generative deep-learning procedures that have been shown to outperform previous methods, such as generative adversarial networks, for image generation tasks. Diffusion models are trained to "denoise", which enables them to generate new geological realizations from input fields characterized by random noise. Latent diffusion models, which are the specific variant considered in this study, provide dimension reduction through use of a low-dimensional latent variable. The model developed in this work includes a variational autoencoder for dimension reduction and a U-net for the denoising process. Our application involves conditional 2D three-facies (channel-levee-mud) systems. The latent diffusion model is shown to provide realizations that are visually consistent with samples from geomodeling software. Quantitative metrics involving spatial and flow-response statistics are evaluated, and general agreement between the diffusion-generated models and reference realizations is observed. Stability tests are performed to assess the smoothness of the parameterization method. The latent diffusion model is then used for ensemble-based data assimilation. Two synthetic "true" models are considered. Significant uncertainty reduction, posterior P$_{10}$-P$_{90}$ forecasts that generally bracket observed data, and consistent posterior geomodels, are achieved in both cases.
Graph Network Surrogate Model for Subsurface Flow Optimization
Dec 14, 2023The optimization of well locations and controls is an important step in the design of subsurface flow operations such as oil production or geological CO2 storage. These optimization problems can be computationally expensive, however, as many potential candidate solutions must be evaluated. In this study, we propose a graph network surrogate model (GNSM) for optimizing well placement and controls. The GNSM transforms the flow model into a computational graph that involves an encoding-processing-decoding architecture. Separate networks are constructed to provide global predictions for the pressure and saturation state variables. Model performance is enhanced through the inclusion of the single-phase steady-state pressure solution as a feature. A multistage multistep strategy is used for training. The trained GNSM is applied to predict flow responses in a 2D unstructured model of a channelized reservoir. Results are presented for a large set of test cases, in which five injection wells and five production wells are placed randomly throughout the model, with a random control variable (bottom-hole pressure) assigned to each well. Median relative error in pressure and saturation for 300 such test cases is 1-2%. The ability of the trained GNSM to provide accurate predictions for a new (geologically similar) permeability realization is demonstrated. Finally, the trained GNSM is used to optimize well locations and controls with a differential evolution algorithm. GNSM-based optimization results are comparable to those from simulation-based optimization, with a runtime speedup of a factor of 36. Much larger speedups are expected if the method is used for robust optimization, in which each candidate solution is evaluated on multiple geological models.
History Matching for Geological Carbon Storage using Data-Space Inversion with Spatio-Temporal Data Parameterization
Oct 05, 2023



History matching based on monitoring data will enable uncertainty reduction, and thus improved aquifer management, in industrial-scale carbon storage operations. In traditional model-based data assimilation, geomodel parameters are modified to force agreement between flow simulation results and observations. In data-space inversion (DSI), history-matched quantities of interest, e.g., posterior pressure and saturation fields conditioned to observations, are inferred directly, without constructing posterior geomodels. This is accomplished efficiently using a set of O(1000) prior simulation results, data parameterization, and posterior sampling within a Bayesian setting. In this study, we develop and implement (in DSI) a deep-learning-based parameterization to represent spatio-temporal pressure and CO2 saturation fields at a set of time steps. The new parameterization uses an adversarial autoencoder (AAE) for dimension reduction and a convolutional long short-term memory (convLSTM) network to represent the spatial distribution and temporal evolution of the pressure and saturation fields. This parameterization is used with an ensemble smoother with multiple data assimilation (ESMDA) in the DSI framework to enable posterior predictions. A realistic 3D system characterized by prior geological realizations drawn from a range of geological scenarios is considered. A local grid refinement procedure is introduced to estimate the error covariance term that appears in the history matching formulation. Extensive history matching results are presented for various quantities, for multiple synthetic true models. Substantial uncertainty reduction in posterior pressure and saturation fields is achieved in all cases. The framework is applied to efficiently provide posterior predictions for a range of error covariance specifications. Such an assessment would be expensive using a model-based approach.
Surrogate Model for Geological CO2 Storage and Its Use in MCMC-based History Matching
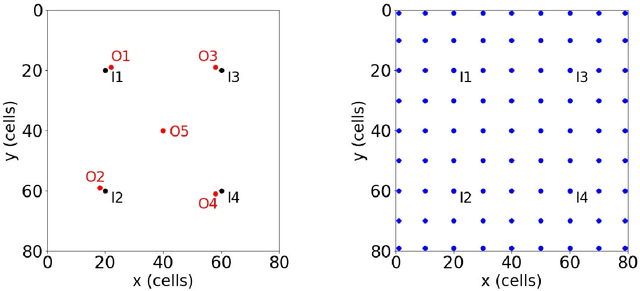
Aug 11, 2023Deep-learning-based surrogate models show great promise for use in geological carbon storage operations. In this work we target an important application - the history matching of storage systems characterized by a high degree of (prior) geological uncertainty. Toward this goal, we extend the recently introduced recurrent R-U-Net surrogate model to treat geomodel realizations drawn from a wide range of geological scenarios. These scenarios are defined by a set of metaparameters, which include the mean and standard deviation of log-permeability, permeability anisotropy ratio, horizontal correlation length, etc. An infinite number of realizations can be generated for each set of metaparameters, so the range of prior uncertainty is large. The surrogate model is trained with flow simulation results, generated using the open-source simulator GEOS, for 2000 random realizations. The flow problems involve four wells, each injecting 1 Mt CO2/year, for 30 years. The trained surrogate model is shown to provide accurate predictions for new realizations over the full range of geological scenarios, with median relative error of 1.3% in pressure and 4.5% in saturation. The surrogate model is incorporated into a Markov chain Monte Carlo history matching workflow, where the goal is to generate history matched realizations and posterior estimates of the metaparameters. We show that, using observed data from monitoring wells in synthetic `true' models, geological uncertainty is reduced substantially. This leads to posterior 3D pressure and saturation fields that display much closer agreement with the true-model responses than do prior predictions.
Multi-Asset Closed-Loop Reservoir Management Using Deep Reinforcement Learning
Jul 21, 2022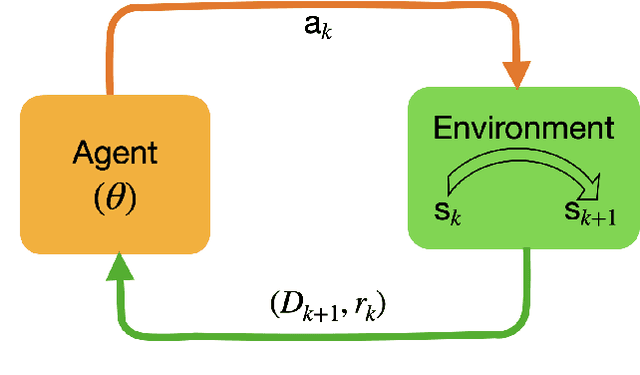
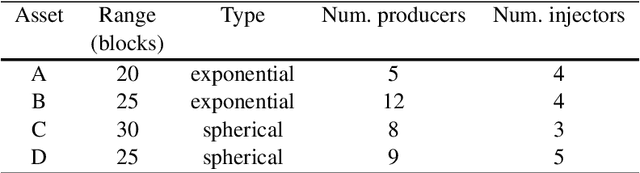
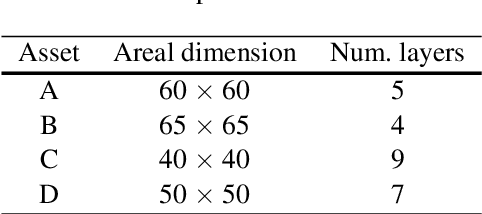
Closed-loop reservoir management (CLRM), in which history matching and production optimization are performed multiple times over the life of an asset, can provide significant improvement in the specified objective. These procedures are computationally expensive due to the large number of flow simulations required for data assimilation and optimization. Existing CLRM procedures are applied asset by asset, without utilizing information that could be useful over a range assets. Here, we develop a CLRM framework for multiple assets with varying numbers of wells. We use deep reinforcement learning to train a single global control policy that is applicable for all assets considered. The new framework is an extension of a recently introduced control policy methodology for individual assets. Embedding layers are incorporated into the representation to handle the different numbers of decision variables that arise for the different assets. Because the global control policy learns a unified representation of useful features from multiple assets, it is less expensive to construct than asset-by-asset training (we observe about 3x speedup in our examples). The production optimization problem includes a relative-change constraint on the well settings, which renders the results suitable for practical use. We apply the multi-asset CLRM framework to 2D and 3D water-flooding examples. In both cases, four assets with different well counts, well configurations, and geostatistical descriptions are considered. Numerical experiments demonstrate that the global control policy provides objective function values, for both the 2D and 3D cases, that are nearly identical to those from control policies trained individually for each asset. This promising finding suggests that multi-asset CLRM may indeed represent a viable practical strategy.
Use of Multifidelity Training Data and Transfer Learning for Efficient Construction of Subsurface Flow Surrogate Models
Apr 23, 2022
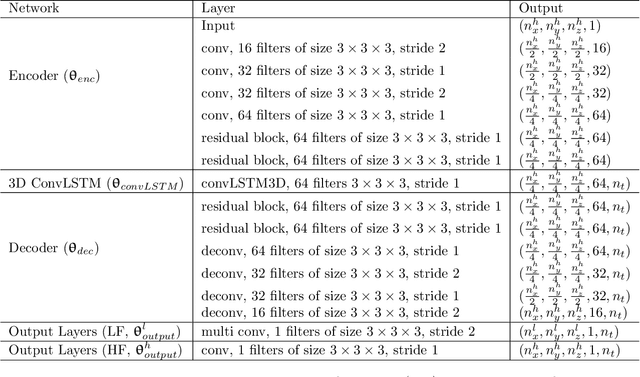


Data assimilation presents computational challenges because many high-fidelity models must be simulated. Various deep-learning-based surrogate modeling techniques have been developed to reduce the simulation costs associated with these applications. However, to construct data-driven surrogate models, several thousand high-fidelity simulation runs may be required to provide training samples, and these computations can make training prohibitively expensive. To address this issue, in this work we present a framework where most of the training simulations are performed on coarsened geomodels. These models are constructed using a flow-based upscaling method. The framework entails the use of a transfer-learning procedure, incorporated within an existing recurrent residual U-Net architecture, in which network training is accomplished in three steps. In the first step. where the bulk of the training is performed, only low-fidelity simulation results are used. The second and third steps, in which the output layer is trained and the overall network is fine-tuned, require a relatively small number of high-fidelity simulations. Here we use 2500 low-fidelity runs and 200 high-fidelity runs, which leads to about a 90% reduction in training simulation costs. The method is applied for two-phase subsurface flow in 3D channelized systems, with flow driven by wells. The surrogate model trained with multifidelity data is shown to be nearly as accurate as a reference surrogate trained with only high-fidelity data in predicting dynamic pressure and saturation fields in new geomodels. Importantly, the network provides results that are significantly more accurate than the low-fidelity simulations used for most of the training. The multifidelity surrogate is also applied for history matching using an ensemble-based procedure, where accuracy relative to reference results is again demonstrated.
Deep reinforcement learning for optimal well control in subsurface systems with uncertain geology
Mar 24, 2022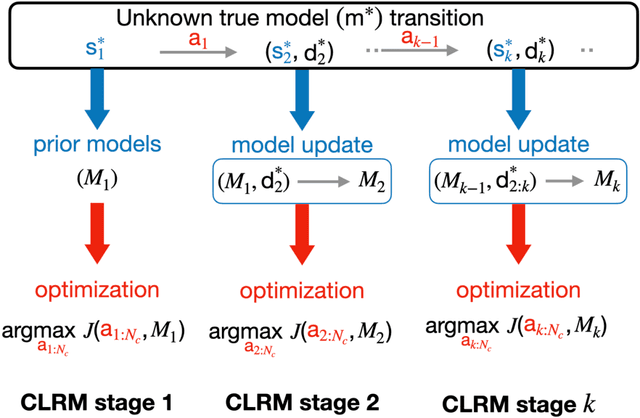

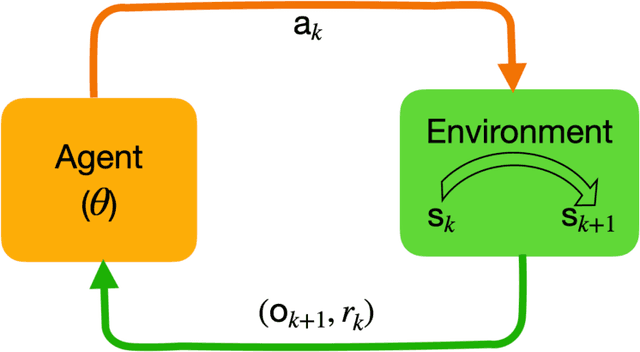
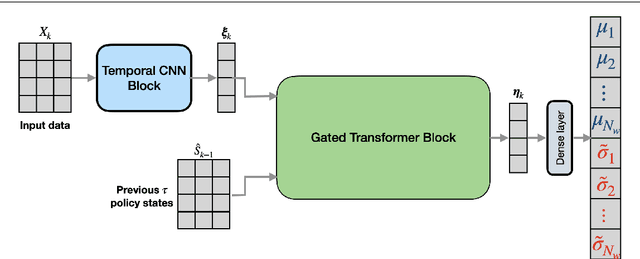
A general control policy framework based on deep reinforcement learning (DRL) is introduced for closed-loop decision making in subsurface flow settings. Traditional closed-loop modeling workflows in this context involve the repeated application of data assimilation/history matching and robust optimization steps. Data assimilation can be particularly challenging in cases where both the geological style (scenario) and individual model realizations are uncertain. The closed-loop reservoir management (CLRM) problem is formulated here as a partially observable Markov decision process, with the associated optimization problem solved using a proximal policy optimization algorithm. This provides a control policy that instantaneously maps flow data observed at wells (as are available in practice) to optimal well pressure settings. The policy is represented by a temporal convolution and gated transformer blocks. Training is performed in a preprocessing step with an ensemble of prior geological models, which can be drawn from multiple geological scenarios. Example cases involving the production of oil via water injection, with both 2D and 3D geological models, are presented. The DRL-based methodology is shown to result in an NPV increase of 15% (for the 2D cases) and 33% (3D cases) relative to robust optimization over prior models, and to an average improvement of 4% in NPV relative to traditional CLRM. The solutions from the control policy are found to be comparable to those from deterministic optimization, in which the geological model is assumed to be known, even when multiple geological scenarios are considered. The control policy approach results in a 76% decrease in computational cost relative to traditional CLRM with the algorithms and parameter settings considered in this work.