 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrueCity: Real and Simulated Urban Data for Cross-Domain 3D Scene Understanding
Nov 10, 2025
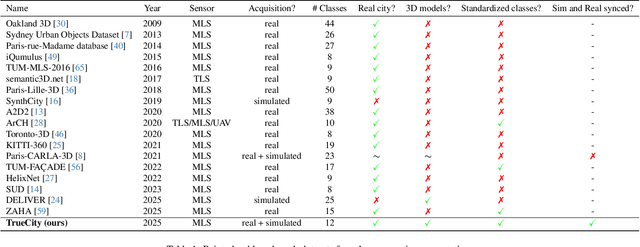
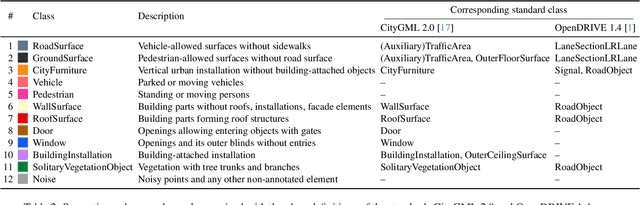
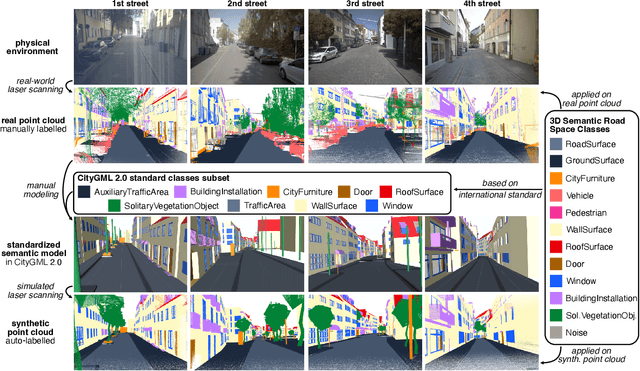
3D semantic scene understanding remains a long-standing challenge in the 3D computer vision community. One of the key issues pertains to limited real-world annotated data to facilitate generalizable models. The common practice to tackle this issue is to simulate new data. Although synthetic datasets offer scalability and perfect labels, their designer-crafted scenes fail to capture real-world complexity and sensor noise, resulting in a synthetic-to-real domain gap. Moreover, no benchmark provides synchronized real and simulated point clouds for segmentation-oriented domain shift analysis. We introduce TrueCity, the first urban semantic segmentation benchmark with cm-accurate annotated real-world point clouds, semantic 3D city models, and annotated simulated point clouds representing the same city. TrueCity proposes segmentation classes aligned with international 3D city modeling standards, enabling consistent evaluation of synthetic-to-real gap. Our extensive experiments on common baselines quantify domain shift and highlight strategies for exploiting synthetic data to enhance real-world 3D scene understanding. We are convinced that the TrueCity dataset will foster further development of sim-to-real gap quantification and enable generalizable data-driven models. The data, code, and 3D models are available online: https://tum-gis.github.io/TrueCity/
Neural ODE Transformers: Analyzing Internal Dynamics and Adaptive Fine-tuning
Mar 03, 2025Recent advancements in large language models (LLMs) based on transformer architectures have sparked significant interest in understanding their inner workings. In this paper, we introduce a novel approach to modeling transformer architectures using highly flexible non-autonomous neural ordinary differential equations (ODEs). Our proposed model parameterizes all weights of attention and feed-forward blocks through neural networks, expressing these weights as functions of a continuous layer index. Through spectral analysis of the model's dynamics, we uncover an increase in eigenvalue magnitude that challenges the weight-sharing assumption prevalent in existing theoretical studies. We also leverage the Lyapunov exponent to examine token-level sensitivity, enhancing model interpretability. Our neural ODE transformer demonstrates performance comparable to or better than vanilla transformers across various configurations and datasets, while offering flexible fine-tuning capabilities that can adapt to different architectural constraints.
Towards Layer-Wise Personalized Federated Learning: Adaptive Layer Disentanglement via Conflicting Gradients
Oct 03, 2024



In personalized Federated Learning (pFL), high data heterogeneity can cause significant gradient divergence across devices, adversely affecting the learning process. This divergence, especially when gradients from different users form an obtuse angle during aggregation, can negate progress, leading to severe weight and gradient update degradation. To address this issue, we introduce a new approach to pFL design, namely Federated Learning with Layer-wise Aggregation via Gradient Analysis (FedLAG), utilizing the concept of gradient conflict at the layer level. Specifically, when layer-wise gradients of different clients form acute angles, those gradients align in the same direction, enabling updates across different clients toward identifying client-invariant features. Conversely, when layer-wise gradient pairs make create obtuse angles, the layers tend to focus on client-specific tasks. In hindsights, FedLAG assigns layers for personalization based on the extent of layer-wise gradient conflicts. Specifically, layers with gradient conflicts are excluded from the global aggregation process. The theoretical evaluation demonstrates that when integrated into other pFL baselines, FedLAG enhances pFL performance by a certain margin. Therefore, our proposed method achieves superior convergence behavior compared with other baselines. Extensive experiments show that our FedLAG outperforms several state-of-the-art methods and can be easily incorporated with many existing methods to further enhance performance.
A statistical method for crack detection in 3D concrete images
Feb 25, 2024In practical applications, effectively segmenting cracks in large-scale computed tomography (CT) images holds significant importance for understanding the structural integrity of materials. However, classical methods and Machine Learning algorithms often incur high computational costs when dealing with the substantial size of input images. Hence, a robust algorithm is needed to pre-detect crack regions, enabling focused analysis and reducing computational overhead. The proposed approach addresses this challenge by offering a streamlined method for identifying crack regions in CT images with high probability. By efficiently identifying areas of interest, our algorithm allows for a more focused examination of potential anomalies within the material structure. Through comprehensive testing on both semi-synthetic and real 3D CT images, we validate the efficiency of our approach in enhancing crack segmentation while reducing computational resource requirements.
A Novel and Optimal Spectral Method for Permutation Synchronization
Mar 21, 2023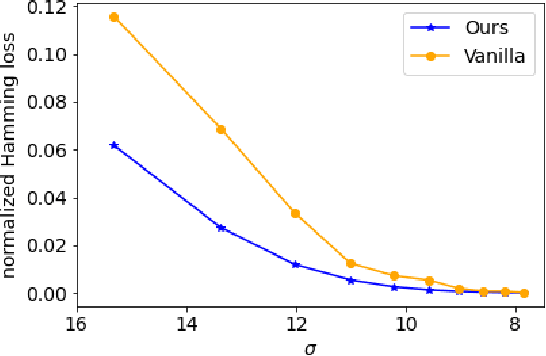
Permutation synchronization is an important problem in computer science that constitutes the key step of many computer vision tasks. The goal is to recover $n$ latent permutations from their noisy and incomplete pairwise measurements. In recent years, spectral methods have gained increasing popularity thanks to their simplicity and computational efficiency. Spectral methods utilize the leading eigenspace $U$ of the data matrix and its block submatrices $U_1,U_2,\ldots, U_n$ to recover the permutations. In this paper, we propose a novel and statistically optimal spectral algorithm. Unlike the existing methods which use $\{U_jU_1^\top\}_{j\geq 2}$, ours constructs an anchor matrix $M$ by aggregating useful information from all the block submatrices and estimates the latent permutations through $\{U_jM^\top\}_{j\geq 1}$. This modification overcomes a crucial limitation of the existing methods caused by the repetitive use of $U_1$ and leads to an improved numerical performance. To establish the optimality of the proposed method, we carry out a fine-grained spectral analysis and obtain a sharp exponential error bound that matches the minimax rate.
Optimal and Private Learning from Human Response Data
Mar 10, 2023



Item response theory (IRT) is the study of how people make probabilistic decisions, with diverse applications in education testing, recommendation systems, among others. The Rasch model of binary response data, one of the most fundamental models in IRT, remains an active area of research with important practical significance. Recently, Nguyen and Zhang (2022) proposed a new spectral estimation algorithm that is efficient and accurate. In this work, we extend their results in two important ways. Firstly, we obtain a refined entrywise error bound for the spectral algorithm, complementing the `average error' $\ell_2$ bound in their work. Notably, under mild sampling conditions, the spectral algorithm achieves the minimax optimal error bound (modulo a log factor). Building on the refined analysis, we also show that the spectral algorithm enjoys optimal sample complexity for top-$K$ recovery (e.g., identifying the best $K$ items from approval/disapproval response data), explaining the empirical findings in the previous work. Our second contribution addresses an important but understudied topic in IRT: privacy. Despite the human-centric applications of IRT, there has not been any proposed privacy-preserving mechanism in the literature. We develop a private extension of the spectral algorithm, leveraging its unique Markov chain formulation and the discrete Gaussian mechanism (Canonne et al., 2020). Experiments show that our approach is significantly more accurate than the baselines in the low-to-moderate privacy regime.
Efficient and Accurate Learning of Mixtures of Plackett-Luce Models
Feb 10, 2023Mixture models of Plackett-Luce (PL) -- one of the most fundamental ranking models -- are an active research area of both theoretical and practical significance. Most previously proposed parameter estimation algorithms instantiate the EM algorithm, often with random initialization. However, such an initialization scheme may not yield a good initial estimate and the algorithms require multiple restarts, incurring a large time complexity. As for the EM procedure, while the E-step can be performed efficiently, maximizing the log-likelihood in the M-step is difficult due to the combinatorial nature of the PL likelihood function (Gormley and Murphy 2008). Therefore, previous authors favor algorithms that maximize surrogate likelihood functions (Zhao et al. 2018, 2020). However, the final estimate may deviate from the true maximum likelihood estimate as a consequence. In this paper, we address these known limitations. We propose an initialization algorithm that can provide a provably accurate initial estimate and an EM algorithm that maximizes the true log-likelihood function efficiently. Experiments on both synthetic and real datasets show that our algorithm is competitive in terms of accuracy and speed to baseline algorithms, especially on datasets with a large number of items.
A Spectral Approach to Item Response Theory
Oct 09, 2022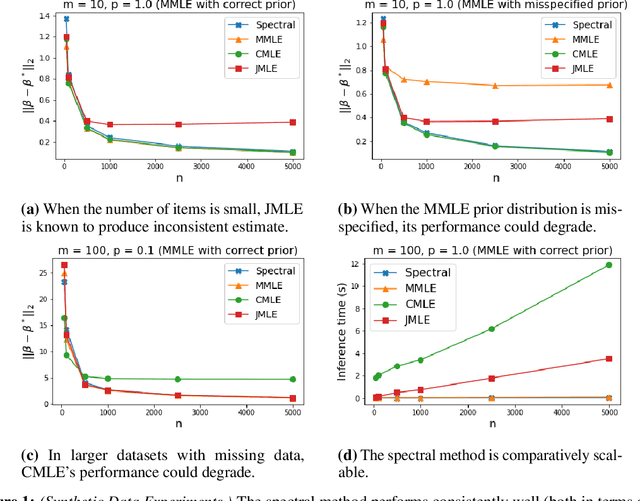
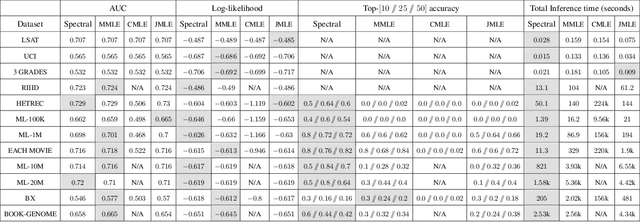
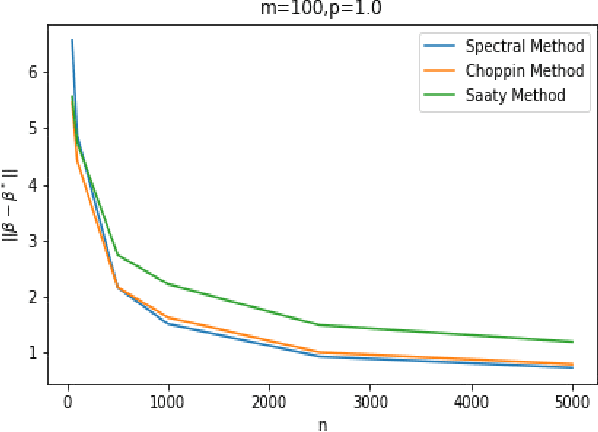
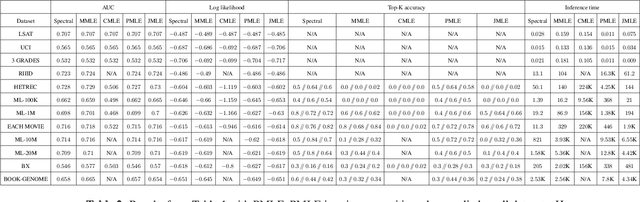
The Rasch model is one of the most fundamental models in \emph{item response theory} and has wide-ranging applications from education testing to recommendation systems. In a universe with $n$ users and $m$ items, the Rasch model assumes that the binary response $X_{li} \in \{0,1\}$ of a user $l$ with parameter $\theta^*_l$ to an item $i$ with parameter $\beta^*_i$ (e.g., a user likes a movie, a student correctly solves a problem) is distributed as $\Pr(X_{li}=1) = 1/(1 + \exp{-(\theta^*_l - \beta^*_i)})$. In this paper, we propose a \emph{new item estimation} algorithm for this celebrated model (i.e., to estimate $\beta^*$). The core of our algorithm is the computation of the stationary distribution of a Markov chain defined on an item-item graph. We complement our algorithmic contributions with finite-sample error guarantees, the first of their kind in the literature, showing that our algorithm is consistent and enjoys favorable optimality properties. We discuss practical modifications to accelerate and robustify the algorithm that practitioners can adopt. Experiments on synthetic and real-life datasets, ranging from small education testing datasets to large recommendation systems datasets show that our algorithm is scalable, accurate, and competitive with the most commonly used methods in the literature.
Orthogonal Gated Recurrent Unit with Neumann-Cayley Transformation
Aug 12, 2022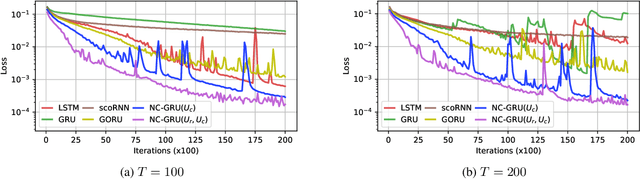
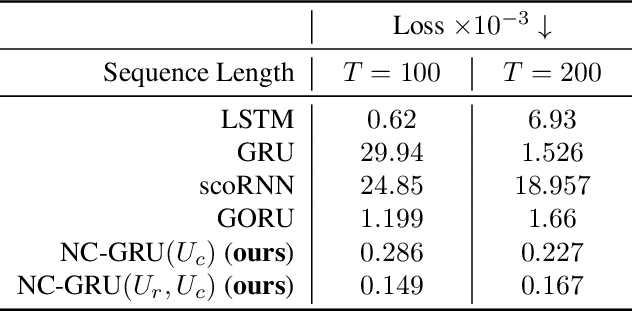
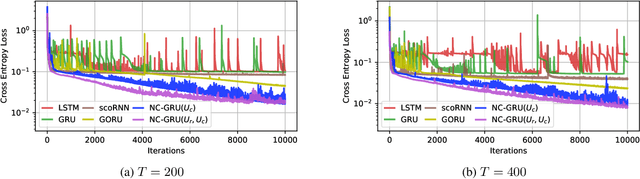
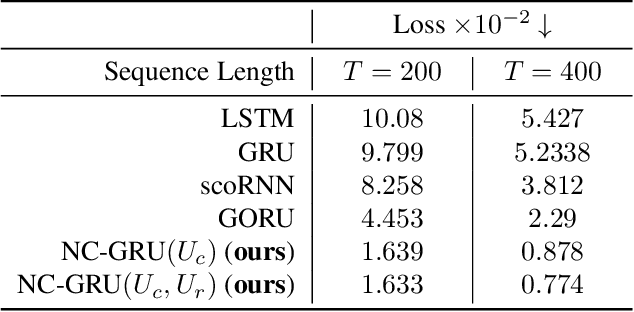
In recent years, using orthogonal matrices has been shown to be a promising approach in improving Recurrent Neural Networks (RNNs) with training, stability, and convergence, particularly, to control gradients. While Gated Recurrent Unit (GRU) and Long Short Term Memory (LSTM) architectures address the vanishing gradient problem by using a variety of gates and memory cells, they are still prone to the exploding gradient problem. In this work, we analyze the gradients in GRU and propose the usage of orthogonal matrices to prevent exploding gradient problems and enhance long-term memory. We study where to use orthogonal matrices and we propose a Neumann series-based Scaled Cayley transformation for training orthogonal matrices in GRU, which we call Neumann-Cayley Orthogonal GRU, or simply NC-GRU. We present detailed experiments of our model on several synthetic and real-world tasks, which show that NC-GRU significantly outperforms GRU as well as several other RNNs.
Efficient and Accurate Top-$K$ Recovery from Choice Data
Jun 23, 2022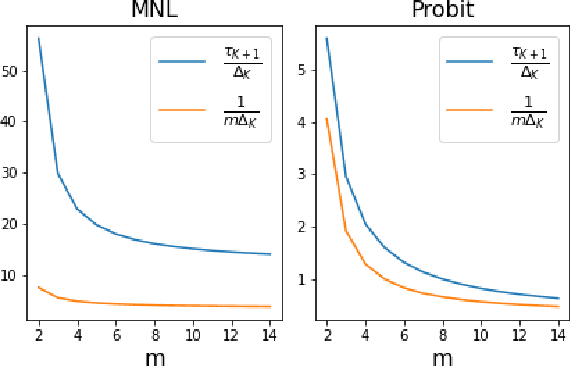
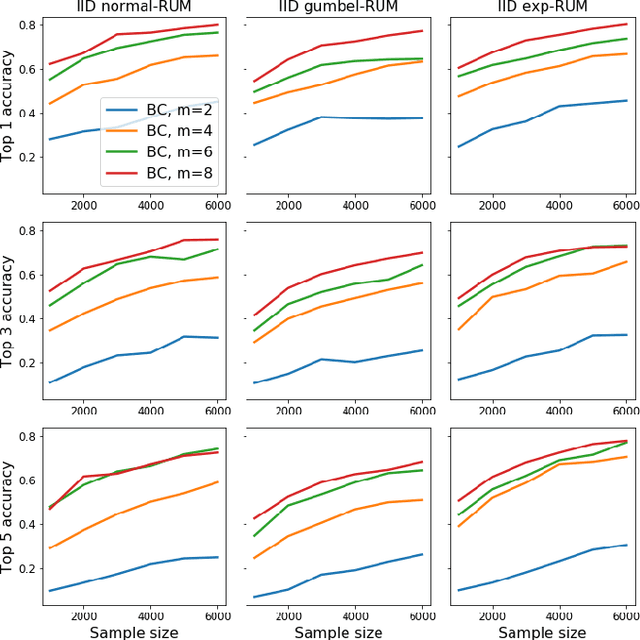
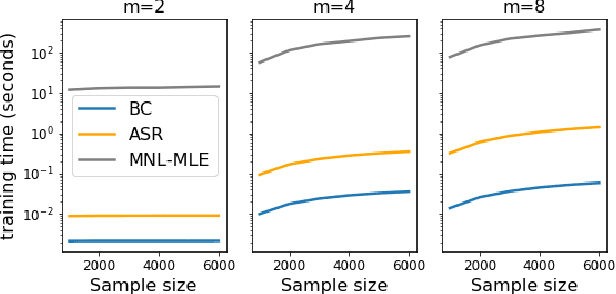
The intersection of learning to rank and choice modeling is an active area of research with applications in e-commerce, information retrieval and the social sciences. In some applications such as recommendation systems, the statistician is primarily interested in recovering the set of the top ranked items from a large pool of items as efficiently as possible using passively collected discrete choice data, i.e., the user picks one item from a set of multiple items. Motivated by this practical consideration, we propose the choice-based Borda count algorithm as a fast and accurate ranking algorithm for top $K$-recovery i.e., correctly identifying all of the top $K$ items. We show that the choice-based Borda count algorithm has optimal sample complexity for top-$K$ recovery under a broad class of random utility models. We prove that in the limit, the choice-based Borda count algorithm produces the same top-$K$ estimate as the commonly used Maximum Likelihood Estimate method but the former's speed and simplicity brings considerable advantages in practice. Experiments on both synthetic and real datasets show that the counting algorithm is competitive with commonly used ranking algorithms in terms of accuracy while being several orders of magnitude faster.