 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAT: Pixel-wise Adaptive Training for Long-tailed Segmentation
Paper and Code
Apr 09, 2024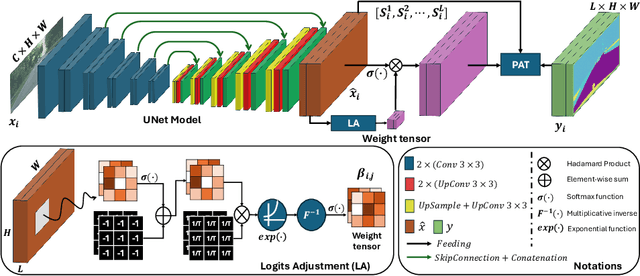
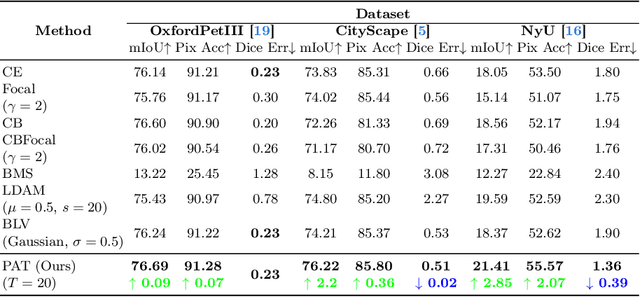
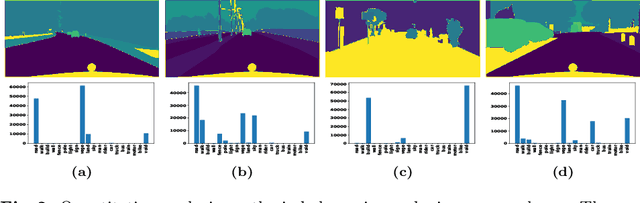
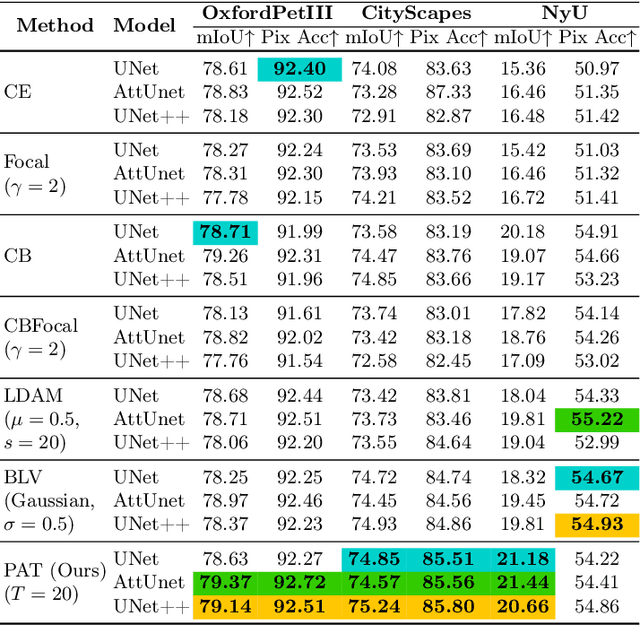
Beyond class frequency, we recognize the impact of class-wise relationships among various class-specific predictions and the imbalance in label masks on long-tailed segmentation learning. To address these challenges, we propose an innovative Pixel-wise Adaptive Training (PAT) technique tailored for long-tailed segmentation. PAT has two key features: 1) class-wise gradient magnitude homogenization, and 2) pixel-wise class-specific loss adaptation (PCLA). First, the class-wise gradient magnitude homogenization helps alleviate the imbalance among label masks by ensuring equal consideration of the class-wise impact on model updates. Second, PCLA tackles the detrimental impact of both rare classes within the long-tailed distribution and inaccurate predictions from previous training stages by encouraging learning classes with low prediction confidence and guarding against forgetting classes with high confidence. This combined approach fosters robust learning while preventing the model from forgetting previously learned knowledge. PAT exhibits significant performance improvements, surpassing the current state-of-the-art by 2.2% in the NyU dataset. Moreover, it enhances overall pixel-wise accuracy by 2.85% and intersection over union value by 2.07%, with a particularly notable declination of 0.39% in detecting rare classes compared to Balance Logits Variation, as demonstrated on the three popular datasets, i.e., OxfordPetIII, CityScape, and NYU.