 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe emergence of numerical representations in communicating artificial agents
Feb 11, 2026Human languages provide efficient systems for expressing numerosities, but whether the sheer pressure to communicate is enough for numerical representations to arise in artificial agents, and whether the emergent codes resemble human numerals at all, remains an open question. We study two neural network-based agents that must communicate numerosities in a referential game using either discrete tokens or continuous sketches, thus exploring both symbolic and iconic representations. Without any pre-defined numeric concepts, the agents achieve high in-distribution communication accuracy in both communication channels and converge on high-precision symbol-meaning mappings. However, the emergent code is non-compositional: the agents fail to derive systematic messages for unseen numerosities, typically reusing the symbol of the highest trained numerosity (discrete), or collapsing extrapolated values onto a single sketch (continuous). We conclude that the communication pressure alone suffices for precise transmission of learned numerosities, but additional pressures are needed to yield compositional codes and generalisation abilities.
Learning to Communicate Across Modalities: Perceptual Heterogeneity in Multi-Agent Systems
Jan 29, 2026Emergent communication offers insight into how agents develop shared structured representations, yet most research assumes homogeneous modalities or aligned representational spaces, overlooking the perceptual heterogeneity of real-world settings. We study a heterogeneous multi-step binary communication game where agents differ in modality and lack perceptual grounding. Despite perceptual misalignment, multimodal systems converge to class-consistent messages grounded in perceptual input. Unimodal systems communicate more efficiently, using fewer bits and achieving lower classification entropy, while multimodal agents require greater information exchange and exhibit higher uncertainty. Bit perturbation experiments provide strong evidence that meaning is encoded in a distributional rather than compositional manner, as each bit's contribution depends on its surrounding pattern. Finally, interoperability analyses show that systems trained in different perceptual worlds fail to directly communicate, but limited fine-tuning enables successful cross-system communication. This work positions emergent communication as a framework for studying how agents adapt and transfer representations across heterogeneous modalities, opening new directions for both theory and experimentation.
Physically Embodied Deep Image Optimisation
Jan 20, 2022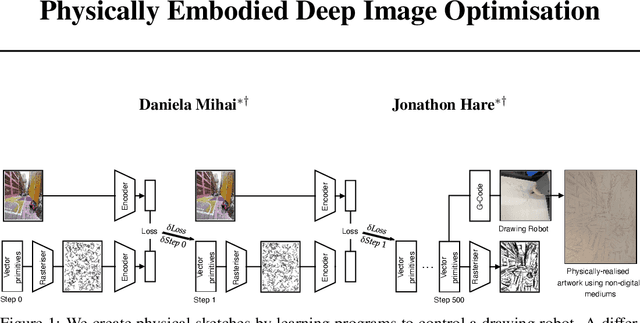



Physical sketches are created by learning programs to control a drawing robot. A differentiable rasteriser is used to optimise sets of drawing strokes to match an input image, using deep networks to provide an encoding for which we can compute a loss. The optimised drawing primitives can then be translated into G-code commands which command a robot to draw the image using drawing instruments such as pens and pencils on a physical support medium.
Shared Visual Representations of Drawing for Communication: How do different biases affect human interpretability and intent?
Oct 15, 2021
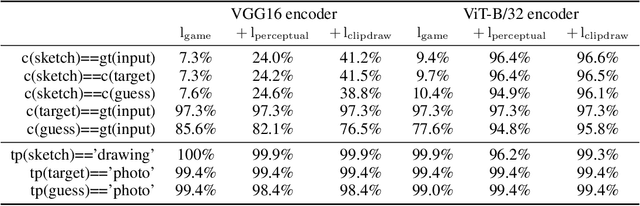


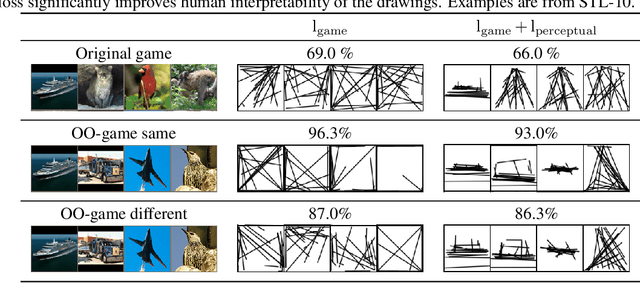
We present an investigation into how representational losses can affect the drawings produced by artificial agents playing a communication game. Building upon recent advances, we show that a combination of powerful pretrained encoder networks, with appropriate inductive biases, can lead to agents that draw recognisable sketches, whilst still communicating well. Further, we start to develop an approach to help automatically analyse the semantic content being conveyed by a sketch and demonstrate that current approaches to inducing perceptual biases lead to a notion of objectness being a key feature despite the agent training being self-supervised.
Learning to Draw: Emergent Communication through Sketching
Jun 03, 2021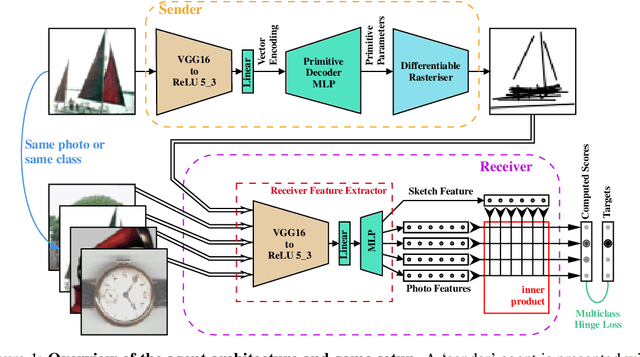
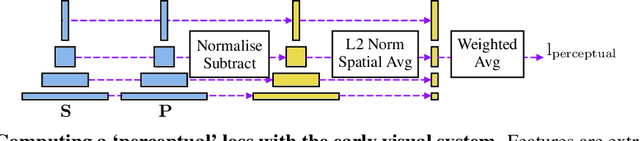

Evidence that visual communication preceded written language and provided a basis for it goes back to prehistory, in forms such as cave and rock paintings depicting traces of our distant ancestors. Emergent communication research has sought to explore how agents can learn to communicate in order to collaboratively solve tasks. Existing research has focused on language, with a learned communication channel transmitting sequences of discrete tokens between the agents. In this work, we explore a visual communication channel between agents that are allowed to draw with simple strokes. Our agents are parameterised by deep neural networks, and the drawing procedure is differentiable, allowing for end-to-end training. In the framework of a referential communication game, we demonstrate that agents can not only successfully learn to communicate by drawing, but with appropriate inductive biases, can do so in a fashion that humans can interpret. We hope to encourage future research to consider visual communication as a more flexible and directly interpretable alternative of training collaborative agents.
Differentiable Drawing and Sketching
Mar 30, 2021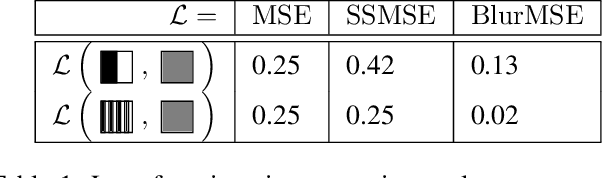


We present a bottom-up differentiable relaxation of the process of drawing points, lines and curves into a pixel raster. Our approach arises from the observation that rasterising a pixel in an image given parameters of a primitive can be reformulated in terms of the primitive's distance transform, and then relaxed to allow the primitive's parameters to be learned. This relaxation allows end-to-end differentiable programs and deep networks to be learned and optimised and provides several building blocks that allow control over how a compositional drawing process is modelled. We emphasise the bottom-up nature of our proposed approach, which allows for drawing operations to be composed in ways that can mimic the physical reality of drawing rather than being tied to, for example, approaches in modern computer graphics. With the proposed approach we demonstrate how sketches can be generated by directly optimising against photographs and how auto-encoders can be built to transform rasterised handwritten digits into vectors without supervision. Extensive experimental results highlight the power of this approach under different modelling assumptions for drawing tasks.
The emergence of visual semantics through communication games
Jan 25, 2021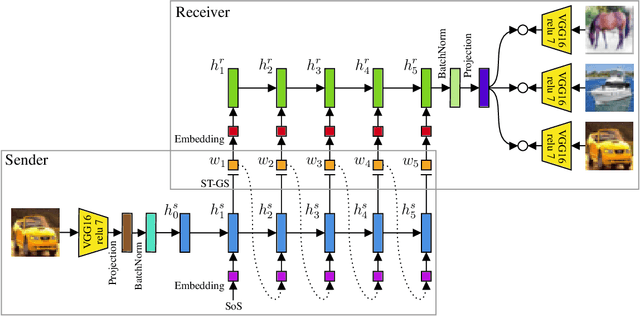

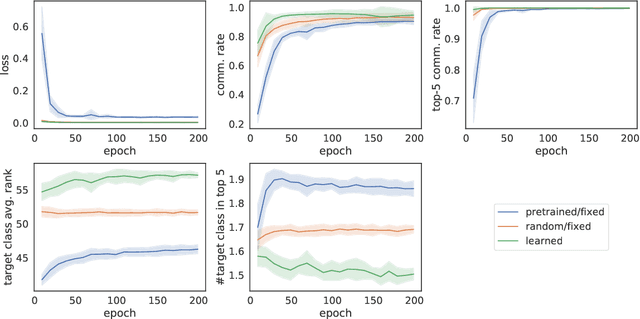
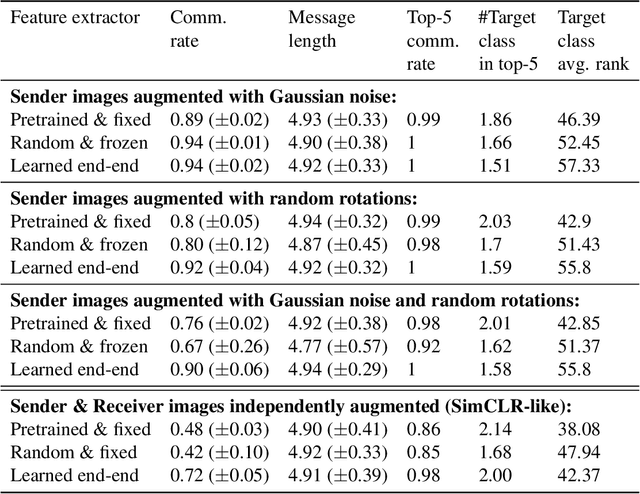
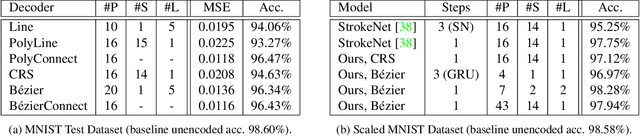
The emergence of communication systems between agents which learn to play referential signalling games with realistic images has attracted a lot of attention recently. The majority of work has focused on using fixed, pretrained image feature extraction networks which potentially bias the information the agents learn to communicate. In this work, we consider a signalling game setting in which a `sender' agent must communicate the information about an image to a `receiver' who must select the correct image from many distractors. We investigate the effect of the feature extractor's weights and of the task being solved on the visual semantics learned by the models. We first demonstrate to what extent the use of pretrained feature extraction networks inductively bias the visual semantics conveyed by emergent communication channel and quantify the visual semantics that are induced. We then go on to explore ways in which inductive biases can be introduced to encourage the emergence of semantically meaningful communication without the need for any form of supervised pretraining of the visual feature extractor. We impose various augmentations to the input images and additional tasks in the game with the aim to induce visual representations which capture conceptual properties of images. Through our experiments, we demonstrate that communication systems which capture visual semantics can be learned in a completely self-supervised manner by playing the right types of game. Our work bridges a gap between emergent communication research and self-supervised feature learning.
How Convolutional Neural Network Architecture Biases Learned Opponency and Colour Tuning
Oct 06, 2020
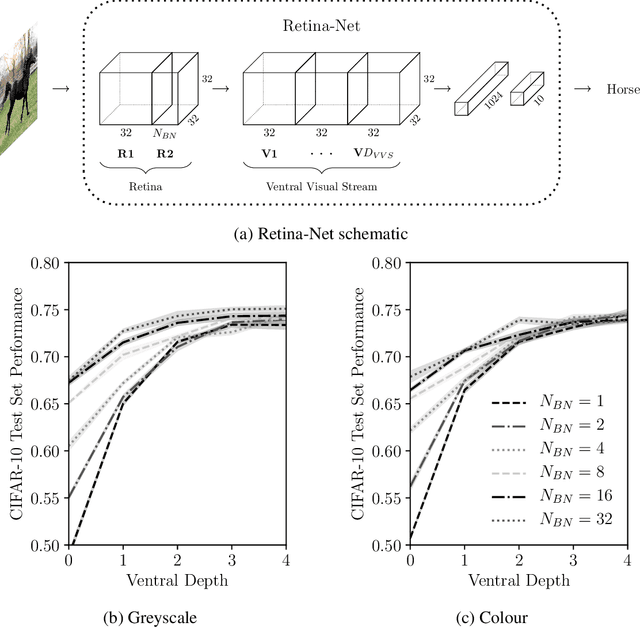

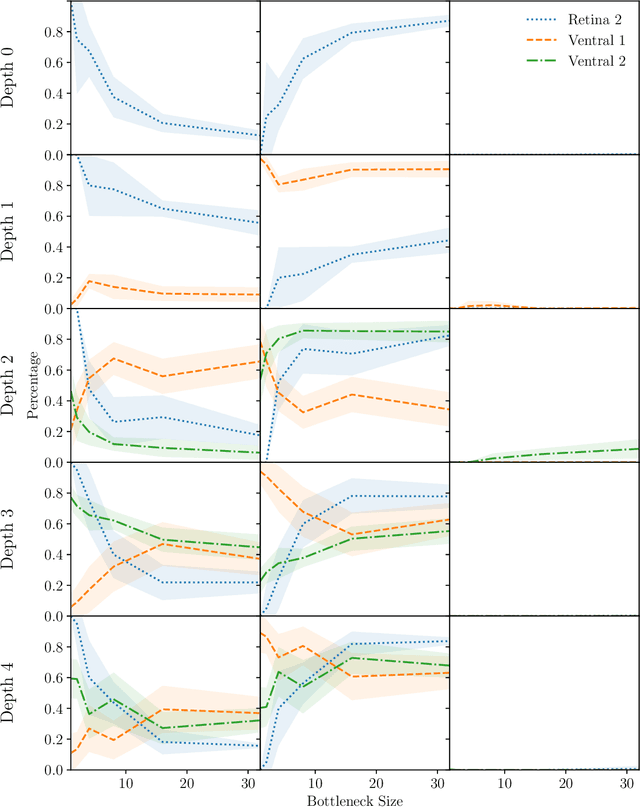
Recent work suggests that changing Convolutional Neural Network (CNN) architecture by introducing a bottleneck in the second layer can yield changes in learned function. To understand this relationship fully requires a way of quantitatively comparing trained networks. The fields of electrophysiology and psychophysics have developed a wealth of methods for characterising visual systems which permit such comparisons. Inspired by these methods, we propose an approach to obtaining spatial and colour tuning curves for convolutional neurons, which can be used to classify cells in terms of their spatial and colour opponency. We perform these classifications for a range of CNNs with different depths and bottleneck widths. Our key finding is that networks with a bottleneck show a strong functional organisation: almost all cells in the bottleneck layer become both spatially and colour opponent, cells in the layer following the bottleneck become non-opponent. The colour tuning data can further be used to form a rich understanding of how colour is encoded by a network. As a concrete demonstration, we show that shallower networks without a bottleneck learn a complex non-linear colour system, whereas deeper networks with tight bottlenecks learn a simple channel opponent code in the bottleneck layer. We further develop a method of obtaining a hue sensitivity curve for a trained CNN which enables high level insights that complement the low level findings from the colour tuning data. We go on to train a series of networks under different conditions to ascertain the robustness of the discussed results. Ultimately, our methods and findings coalesce with prior art, strengthening our ability to interpret trained CNNs and furthering our understanding of the connection between architecture and learned representation. Code for all experiments is available at https://github.com/ecs-vlc/opponency.
Avoiding hashing and encouraging visual semantics in referential emergent language games
Nov 13, 2019

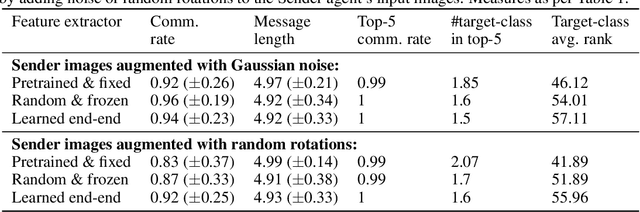

There has been an increasing interest in the area of emergent communication between agents which learn to play referential signalling games with realistic images. In this work, we consider the signalling game setting of Havrylov and Titov and investigate the effect of the feature extractor's weights and of the task being solved on the visual semantics learned or captured by the models. We impose various augmentation to the input images and additional tasks in the game with the aim to induce visual representations which capture conceptual properties of images. Through our set of experiments, we demonstrate that communication systems which capture visual semantics can be learned in a completely self-supervised manner by playing the right types of game.
Spatial and Colour Opponency in Anatomically Constrained Deep Networks
Oct 14, 2019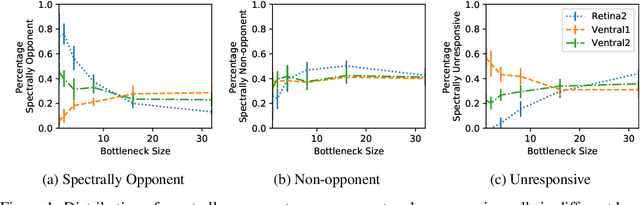
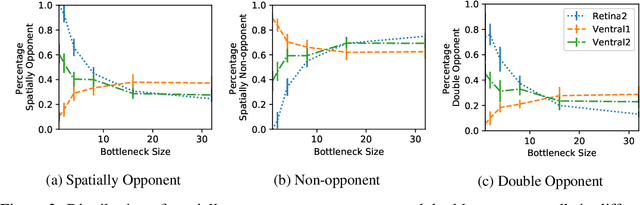
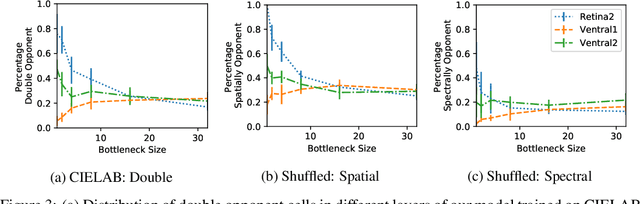

Colour vision has long fascinated scientists, who have sought to understand both the physiology of the mechanics of colour vision and the psychophysics of colour perception. We consider representations of colour in anatomically constrained convolutional deep neural networks. Following ideas from neuroscience, we classify cells in early layers into groups relating to their spectral and spatial functionality. We show the emergence of single and double opponent cells in our networks and characterise how the distribution of these cells changes under the constraint of a retinal bottleneck. Our experiments not only open up a new understanding of how deep networks process spatial and colour information, but also provide new tools to help understand the black box of deep learning. The code for all experiments is avaialable at \url{https://github.com/ecs-vlc/opponency}.