 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Convolutional Neural Network Architecture Biases Learned Opponency and Colour Tuning
Oct 06, 2020

Recent work suggests that changing Convolutional Neural Network (CNN) architecture by introducing a bottleneck in the second layer can yield changes in learned function. To understand this relationship fully requires a way of quantitatively comparing trained networks. The fields of electrophysiology and psychophysics have developed a wealth of methods for characterising visual systems which permit such comparisons. Inspired by these methods, we propose an approach to obtaining spatial and colour tuning curves for convolutional neurons, which can be used to classify cells in terms of their spatial and colour opponency. We perform these classifications for a range of CNNs with different depths and bottleneck widths. Our key finding is that networks with a bottleneck show a strong functional organisation: almost all cells in the bottleneck layer become both spatially and colour opponent, cells in the layer following the bottleneck become non-opponent. The colour tuning data can further be used to form a rich understanding of how colour is encoded by a network. As a concrete demonstration, we show that shallower networks without a bottleneck learn a complex non-linear colour system, whereas deeper networks with tight bottlenecks learn a simple channel opponent code in the bottleneck layer. We further develop a method of obtaining a hue sensitivity curve for a trained CNN which enables high level insights that complement the low level findings from the colour tuning data. We go on to train a series of networks under different conditions to ascertain the robustness of the discussed results. Ultimately, our methods and findings coalesce with prior art, strengthening our ability to interpret trained CNNs and furthering our understanding of the connection between architecture and learned representation. Code for all experiments is available at https://github.com/ecs-vlc/opponency.
Understanding and Enhancing Mixed Sample Data Augmentation
Feb 27, 2020



Mixed Sample Data Augmentation (MSDA) has received increasing attention in recent years, with many successful variants such as MixUp and CutMix. Following insight on the efficacy of CutMix in particular, we propose FMix, an MSDA that uses binary masks obtained by applying a threshold to low frequency images sampled from Fourier space. FMix improves performance over MixUp and CutMix for a number of state-of-the-art models across a range of data sets and problem settings. We go on to analyse MixUp, CutMix, and FMix from an information theoretic perspective, characterising learned models in terms of how they progressively compress the input with depth. Ultimately, our analyses allow us to decouple two complementary properties of augmentations, and present a unified framework for reasoning about MSDA. Code for all experiments is available at https://github.com/ecs-vlc/FMix.
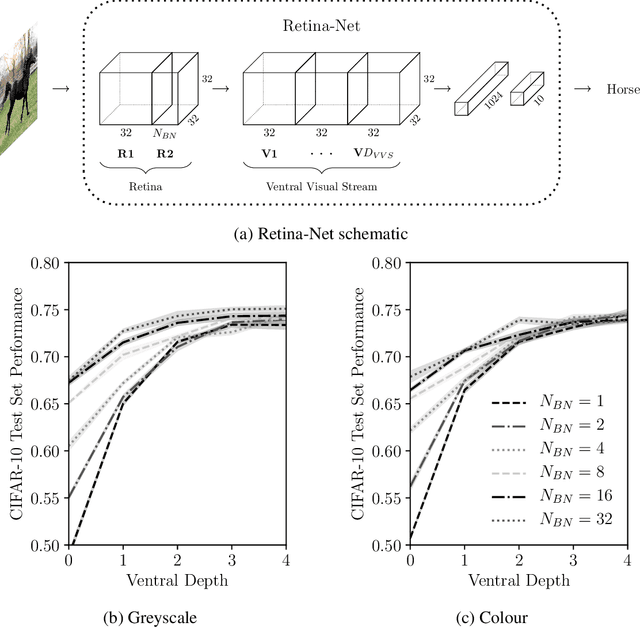
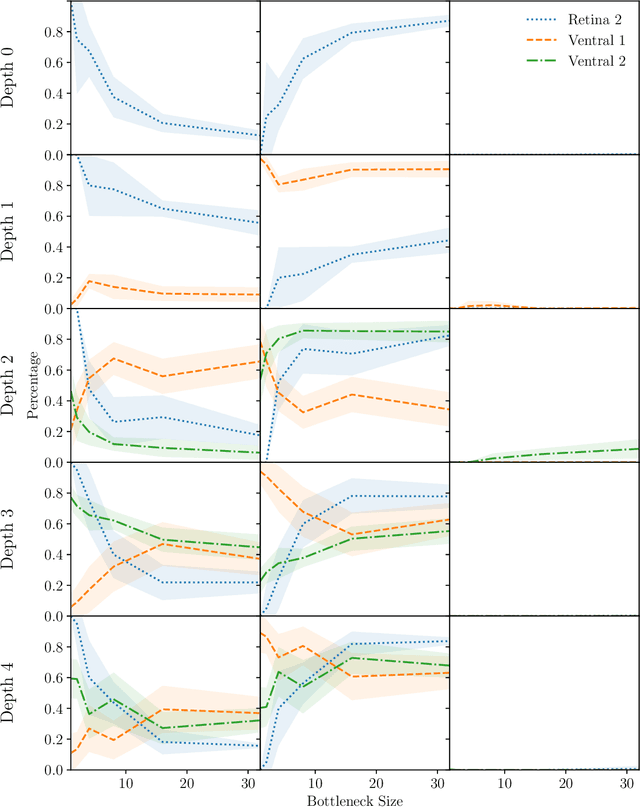
Spatial and Colour Opponency in Anatomically Constrained Deep Networks
Oct 14, 2019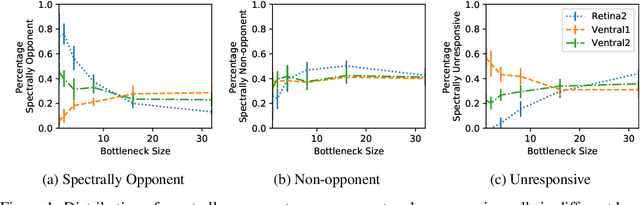
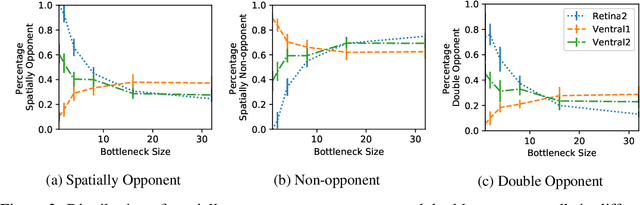
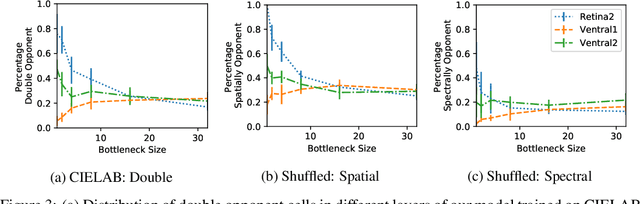

Colour vision has long fascinated scientists, who have sought to understand both the physiology of the mechanics of colour vision and the psychophysics of colour perception. We consider representations of colour in anatomically constrained convolutional deep neural networks. Following ideas from neuroscience, we classify cells in early layers into groups relating to their spectral and spatial functionality. We show the emergence of single and double opponent cells in our networks and characterise how the distribution of these cells changes under the constraint of a retinal bottleneck. Our experiments not only open up a new understanding of how deep networks process spatial and colour information, but also provide new tools to help understand the black box of deep learning. The code for all experiments is avaialable at \url{https://github.com/ecs-vlc/opponency}.
A Biologically Inspired Visual Working Memory for Deep Networks
Jan 09, 2019


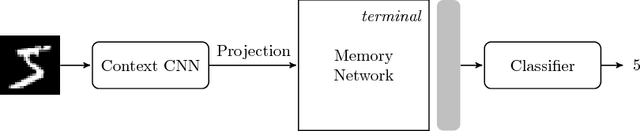
The ability to look multiple times through a series of pose-adjusted glimpses is fundamental to human vision. This critical faculty allows us to understand highly complex visual scenes. Short term memory plays an integral role in aggregating the information obtained from these glimpses and informing our interpretation of the scene. Computational models have attempted to address glimpsing and visual attention but have failed to incorporate the notion of memory. We introduce a novel, biologically inspired visual working memory architecture that we term the Hebb-Rosenblatt memory. We subsequently introduce a fully differentiable Short Term Attentive Working Memory model (STAWM) which uses transformational attention to learn a memory over each image it sees. The state of our Hebb-Rosenblatt memory is embedded in STAWM as the weights space of a layer. By projecting different queries through this layer we can obtain goal-oriented latent representations for tasks including classification and visual reconstruction. Our model obtains highly competitive classification performance on MNIST and CIFAR-10. As demonstrated through the CelebA dataset, to perform reconstruction the model learns to make a sequence of updates to a canvas which constitute a parts-based representation. Classification with the self supervised representation obtained from MNIST is shown to be in line with the state of the art models (none of which use a visual attention mechanism). Finally, we show that STAWM can be trained under the dual constraints of classification and reconstruction to provide an interpretable visual sketchpad which helps open the 'black-box' of deep learning.
Torchbearer: A Model Fitting Library for PyTorch
Sep 10, 2018We introduce torchbearer, a model fitting library for pytorch aimed at researchers working on deep learning or differentiable programming. The torchbearer library provides a high level metric and callback API that can be used for a wide range of applications. We also include a series of built in callbacks that can be used for: model persistence, learning rate decay, logging, data visualization and more. The extensive documentation includes an example library for deep learning and dynamic programming problems and can be found at http://torchbearer.readthedocs.io. The code is licensed under the MIT License and available at https://github.com/ecs-vlc/torchbearer.