 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Pitfalls of Measuring Occlusion Robustness through Data Distortion
Nov 24, 2022Over the past years, the crucial role of data has largely been shadowed by the field's focus on architectures and training procedures. We often cause changes to the data without being aware of their wider implications. In this paper we show that distorting images without accounting for the artefacts introduced leads to biased results when establishing occlusion robustness. To ensure models behave as expected in real-world scenarios, we need to rule out the impact added artefacts have on evaluation. We propose a new approach, iOcclusion, as a fairer alternative for applications where the possible occluders are unknown.
Generalisation and the Risk--Entropy Curve
Feb 15, 2022



In this paper we show that the expected generalisation performance of a learning machine is determined by the distribution of risks or equivalently its logarithm -- a quantity we term the risk entropy -- and the fluctuations in a quantity we call the training ratio. We show that the risk entropy can be empirically inferred for deep neural network models using Markov Chain Monte Carlo techniques. Results are presented for different deep neural networks on a variety of problems. The asymptotic behaviour of the risk entropy acts in an analogous way to the capacity of the learning machine, but the generalisation performance experienced in practical situations is determined by the behaviour of the risk entropy before the asymptotic regime is reached. This performance is strongly dependent on the distribution of the data (features and targets) and not just on the capacity of the learning machine.
On Data-centric Myths
Nov 22, 2021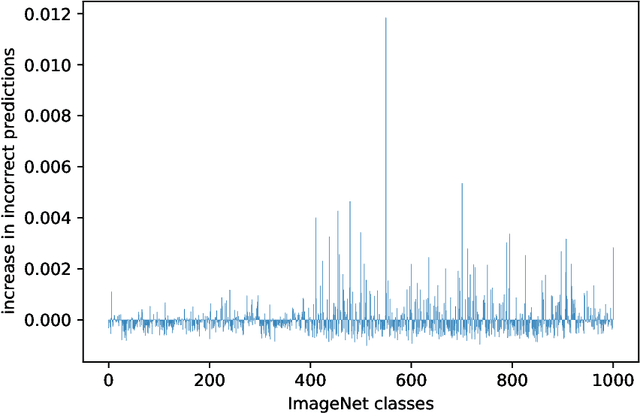

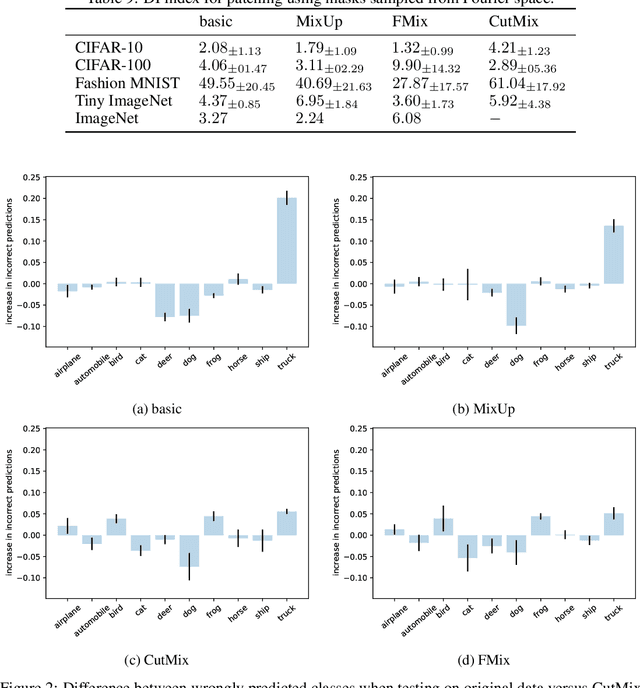

The community lacks theory-informed guidelines for building good data sets. We analyse theoretical directions relating to what aspects of the data matter and conclude that the intuitions derived from the existing literature are incorrect and misleading. Using empirical counter-examples, we show that 1) data dimension should not necessarily be minimised and 2) when manipulating data, preserving the distribution is inessential. This calls for a more data-aware theoretical understanding. Although not explored in this work, we propose the study of the impact of data modification on learned representations as a promising research direction.
On the Effects of Data Distortion on Model Analysis and Training
Oct 26, 2021



Data modification can introduce artificial information. It is often assumed that the resulting artefacts are detrimental to training, whilst being negligible when analysing models. We investigate these assumptions and conclude that in some cases they are unfounded and lead to incorrect results. Specifically, we show current shape bias identification methods and occlusion robustness measures are biased and propose a fairer alternative for the latter. Subsequently, through a series of experiments we seek to correct and strengthen the community's perception of how distorting data affects learning. Based on our empirical results we argue that the impact of the artefacts must be understood and exploited rather than eliminated.
Understanding and Enhancing Mixed Sample Data Augmentation
Feb 27, 2020



Mixed Sample Data Augmentation (MSDA) has received increasing attention in recent years, with many successful variants such as MixUp and CutMix. Following insight on the efficacy of CutMix in particular, we propose FMix, an MSDA that uses binary masks obtained by applying a threshold to low frequency images sampled from Fourier space. FMix improves performance over MixUp and CutMix for a number of state-of-the-art models across a range of data sets and problem settings. We go on to analyse MixUp, CutMix, and FMix from an information theoretic perspective, characterising learned models in terms of how they progressively compress the input with depth. Ultimately, our analyses allow us to decouple two complementary properties of augmentations, and present a unified framework for reasoning about MSDA. Code for all experiments is available at https://github.com/ecs-vlc/FMix.
Rethinking Generalisation
Nov 11, 2019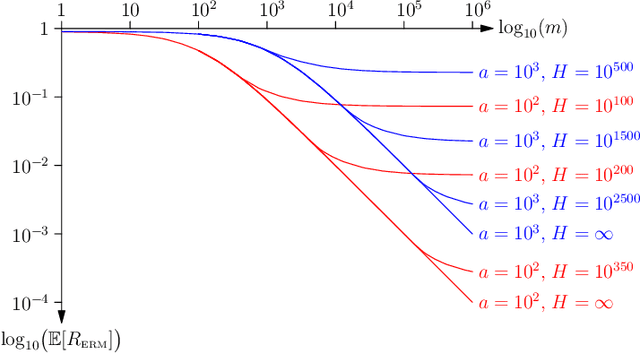
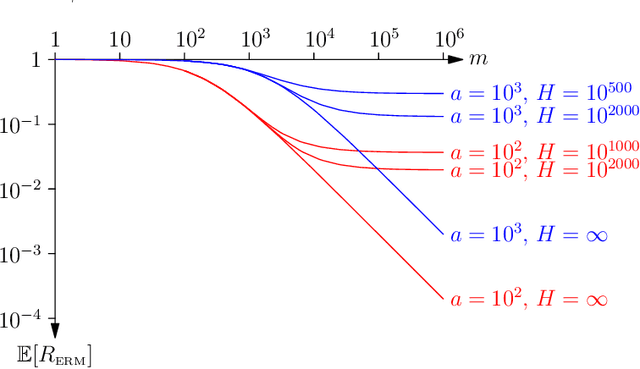
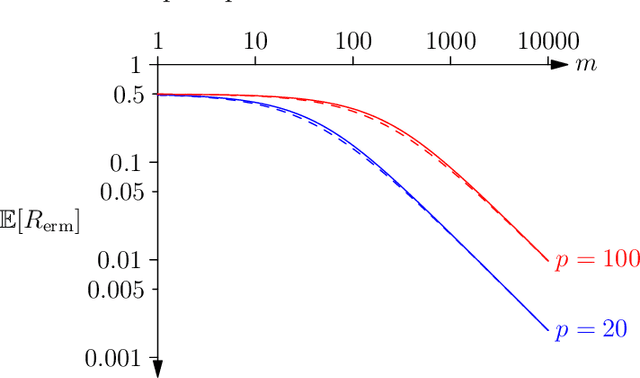
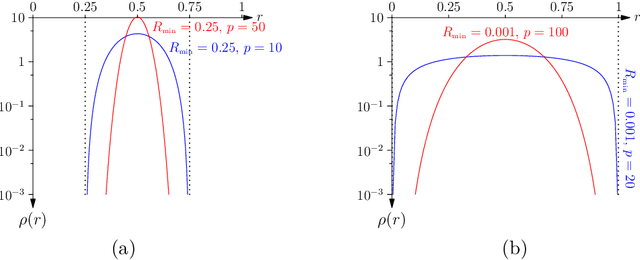
In this paper, we present a new approach to computing the generalisation performance assuming that the distribution of risks, $\rho(r)$, for a learning scenario is known. This allows us to compute the expected error of a learning machine using empirical risk minimisation. We show that it is possible to obtain results for both classification and regression. We show a critical quantity in determining the generalisation performance is the power-law behaviour of $\rho(r)$ around its minimum value. We compute $\rho(r)$ for the case of all Boolean functions and for the perceptron. We start with a simplistic analysis but then do a more formal one later on. We show that the simplistic results are qualitatively correct and provide a good approximation to the actual results if we replace the true training set size with an approximate training set size.