 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Generalisation
Paper and Code
Nov 11, 2019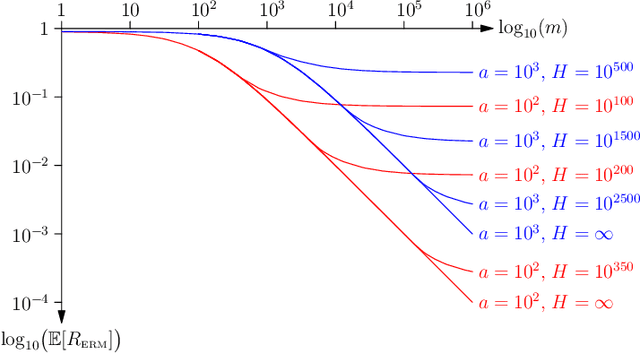
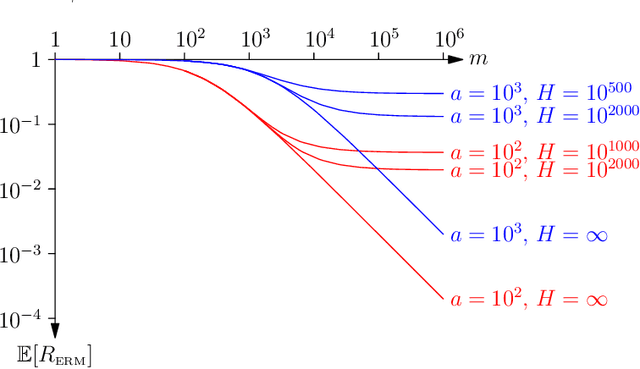
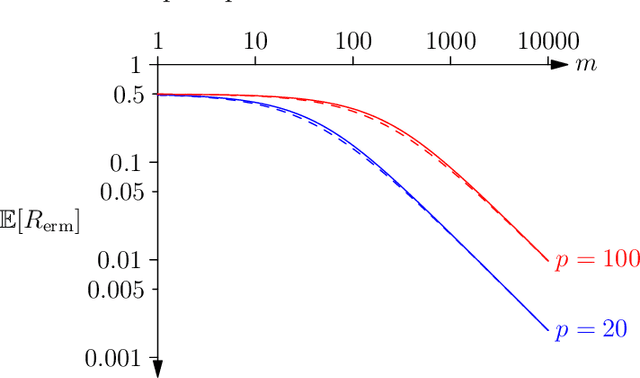
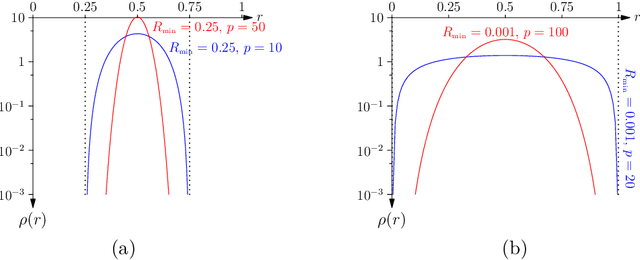
In this paper, we present a new approach to computing the generalisation performance assuming that the distribution of risks, $\rho(r)$, for a learning scenario is known. This allows us to compute the expected error of a learning machine using empirical risk minimisation. We show that it is possible to obtain results for both classification and regression. We show a critical quantity in determining the generalisation performance is the power-law behaviour of $\rho(r)$ around its minimum value. We compute $\rho(r)$ for the case of all Boolean functions and for the perceptron. We start with a simplistic analysis but then do a more formal one later on. We show that the simplistic results are qualitatively correct and provide a good approximation to the actual results if we replace the true training set size with an approximate training set size.