 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEIS: Subspace-based Equivariance and Invariance Scores for Neural Representations
Feb 03, 2026Understanding how neural representations respond to geometric transformations is essential for evaluating whether learned features preserve meaningful spatial structure. Existing approaches primarily assess robustness by comparing model outputs under transformed inputs, offering limited insight into how geometric information is organized within internal representations and failing to distinguish between information loss and re-encoding. In this work, we introduce SEIS (Subspace-based Equivariance and Invariance Scores), a subspace metric for analyzing layer-wise feature representations under geometric transformations, disentangling equivariance from invariance without requiring labels or explicit knowledge of the transformation. Synthetic validation confirms that SEIS correctly recovers known transformations. Applied to trained classification networks, SEIS reveals a transition from equivariance in early layers to invariance in deeper layers, and that data augmentation increases invariance while preserving equivariance. We further show that multi-task learning induces synergistic gains in both properties at the shared encoder, and skip connections restore equivariance lost during decoding.
SynthFormer: Equivariant Pharmacophore-based Generation of Molecules for Ligand-Based Drug Design
Oct 03, 2024
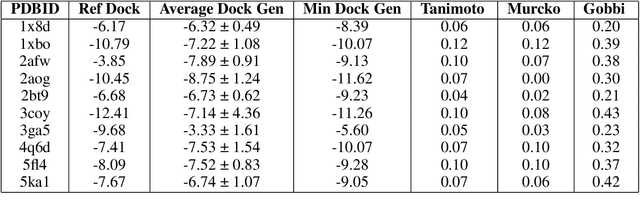


Drug discovery is a complex and resource-intensive process, with significant time and cost investments required to bring new medicines to patients. Recent advancements in generative machine learning (ML) methods offer promising avenues to accelerate early-stage drug discovery by efficiently exploring chemical space. This paper addresses the gap between in silico generative approaches and practical in vitro methodologies, highlighting the need for their integration to optimize molecule discovery. We introduce SynthFormer, a novel ML model that utilizes a 3D equivariant encoder for pharmacophores to generate fully synthesizable molecules, constructed as synthetic trees. Unlike previous methods, SynthFormer incorporates 3D information and provides synthetic paths, enhancing its ability to produce molecules with good docking scores across various proteins. Our contributions include a new methodology for efficient chemical space exploration using 3D information, a novel architecture called Synthformer for translating 3D pharmacophore representations into molecules, and a meaningful embedding space that organizes reagents for drug discovery optimization. Synthformer generates molecules that dock well and enables effective late-stage optimization restricted by synthesis paths.
Cascade Learning Localises Discriminant Features in Visual Scene Classification
Nov 30, 2023Lack of interpretability of deep convolutional neural networks (DCNN) is a well-known problem particularly in the medical domain as clinicians want trustworthy automated decisions. One way to improve trust is to demonstrate the localisation of feature representations with respect to expert labeled regions of interest. In this work, we investigate the localisation of features learned via two varied learning paradigms and demonstrate the superiority of one learning approach with respect to localisation. Our analysis on medical and natural datasets show that the traditional end-to-end (E2E) learning strategy has a limited ability to localise discriminative features across multiple network layers. We show that a layer-wise learning strategy, namely cascade learning (CL), results in more localised features. Considering localisation accuracy, we not only show that CL outperforms E2E but that it is a promising method of predicting regions. On the YOLO object detection framework, our best result shows that CL outperforms the E2E scheme by $2\%$ in mAP.
Improving the Robustness of Neural Multiplication Units with Reversible Stochasticity
Nov 10, 2022Multilayer Perceptrons struggle to learn certain simple arithmetic tasks. Specialist neural modules for arithmetic can outperform classical architectures with gains in extrapolation, interpretability and convergence speeds, but are highly sensitive to the training range. In this paper, we show that Neural Multiplication Units (NMUs) are unable to reliably learn tasks as simple as multiplying two inputs when given different training ranges. Causes of failure are linked to inductive and input biases which encourage convergence to solutions in undesirable optima. A solution, the stochastic NMU (sNMU), is proposed to apply reversible stochasticity, encouraging avoidance of such optima whilst converging to the true solution. Empirically, we show that stochasticity provides improved robustness with the potential to improve learned representations of upstream networks for numerical and image tasks.
Data-Driven Interpolation for Super-Scarce X-Ray Computed Tomography
May 16, 2022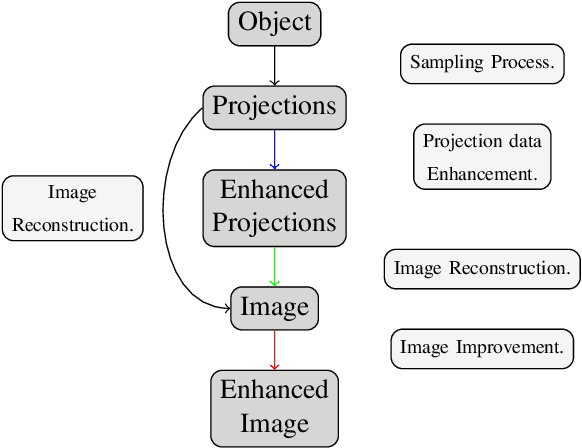
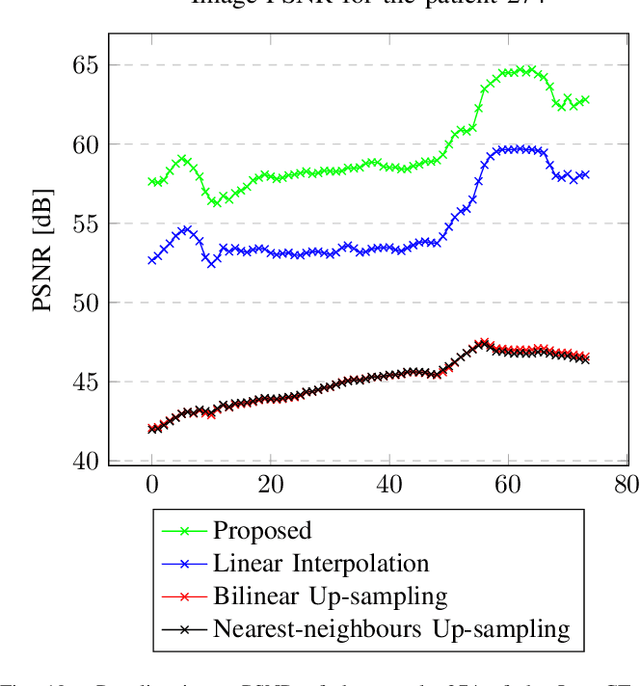
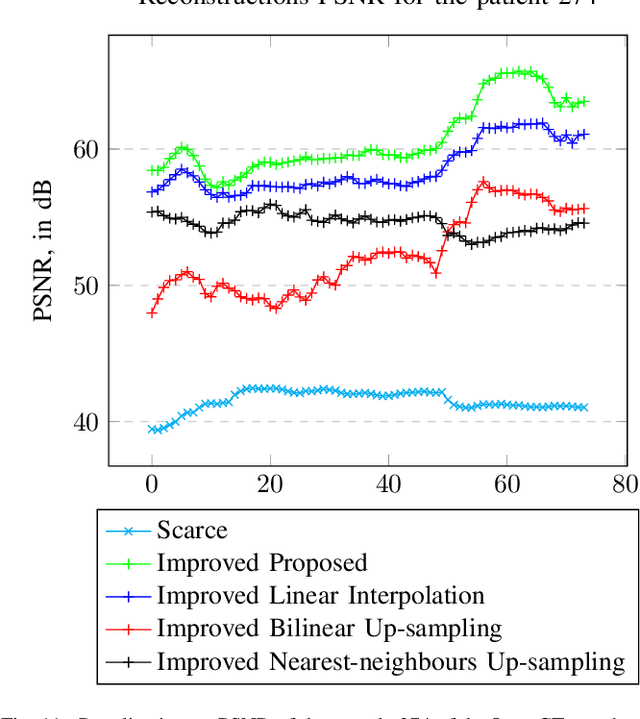
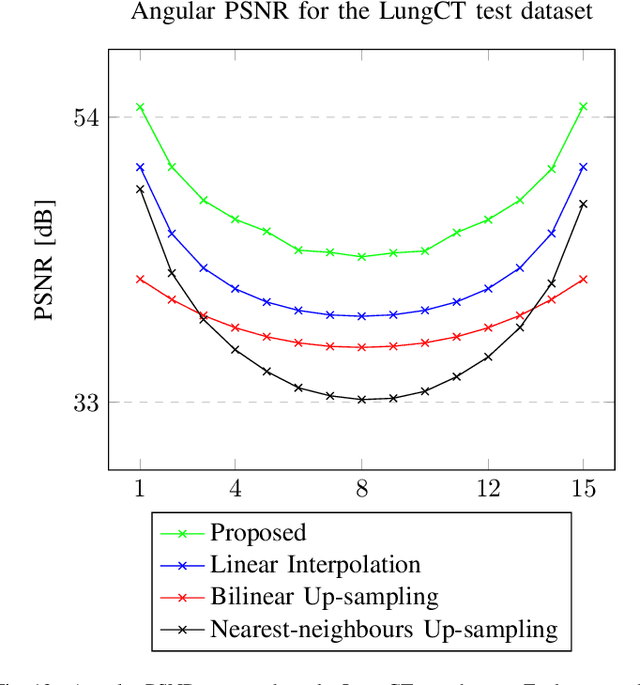
We address the problem of reconstructing X-Ray tomographic images from scarce measurements by interpolating missing acquisitions using a self-supervised approach. To do so, we train shallow neural networks to combine two neighbouring acquisitions into an estimated measurement at an intermediate angle. This procedure yields an enhanced sequence of measurements that can be reconstructed using standard methods, or further enhanced using regularisation approaches. Unlike methods that improve the sequence of acquisitions using an initial deterministic interpolation followed by machine-learning enhancement, we focus on inferring one measurement at once. This allows the method to scale to 3D, the computation to be faster and crucially, the interpolation to be significantly better than the current methods, when they exist. We also establish that a sequence of measurements must be processed as such, rather than as an image or a volume. We do so by comparing interpolation and up-sampling methods, and find that the latter significantly under-perform. We compare the performance of the proposed method against deterministic interpolation and up-sampling procedures and find that it outperforms them, even when used jointly with a state-of-the-art projection-data enhancement approach using machine-learning. These results are obtained for 2D and 3D imaging, on large biomedical datasets, in both projection space and image space.
Modelling nonlinear dependencies in the latent space of inverse scattering
Mar 19, 2022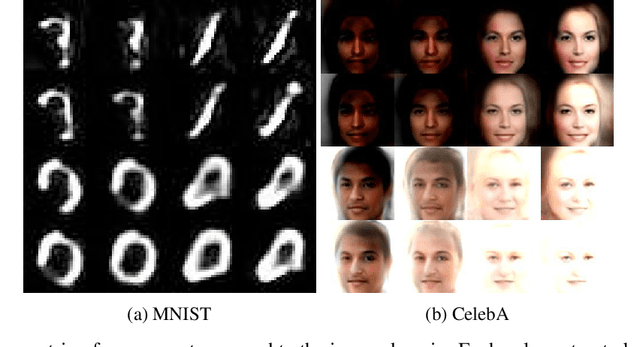



The problem of inverse scattering proposed by Angles and Mallat in 2018, concerns training a deep neural network to invert the scattering transform applied to an image. After such a network is trained, it can be used as a generative model given that we can sample from the distribution of principal components of scattering coefficients. For this purpose, Angles and Mallat simply use samples from independent Gaussians. However, as shown in this paper, the distribution of interest can actually be very far from normal and non-negligible dependencies might exist between different coefficients. This motivates using models for this distribution that allow for non-linear dependencies between variables. Within this paper, two such models are explored, namely a Variational AutoEncoder and a Generative Adversarial Network. We demonstrate the results obtained can be extremely realistic on some datasets and look better than those produced by Angles and Mallat. The conducted meta-analysis also shows a clear practical advantage of such constructed generative models in terms of the efficiency of their training process compared to existing generative models for images.
Sinogram Enhancement with Generative Adversarial Networks using Shape Priors
Feb 01, 2022



Compensating scarce measurements by inferring them from computational models is a way to address ill-posed inverse problems. We tackle Limited Angle Tomography by completing the set of acquisitions using a generative model and prior-knowledge about the scanned object. Using a Generative Adversarial Network as model and Computer-Assisted Design data as shape prior, we demonstrate a quantitative and qualitative advantage of our technique over other state-of-the-art methods. Inferring a substantial number of consecutive missing measurements, we offer an alternative to other image inpainting techniques that fall short of providing a satisfying answer to our research question: can X-Ray exposition be reduced by using generative models to infer lacking measurements?
Learning Division with Neural Arithmetic Logic Modules
Oct 12, 2021
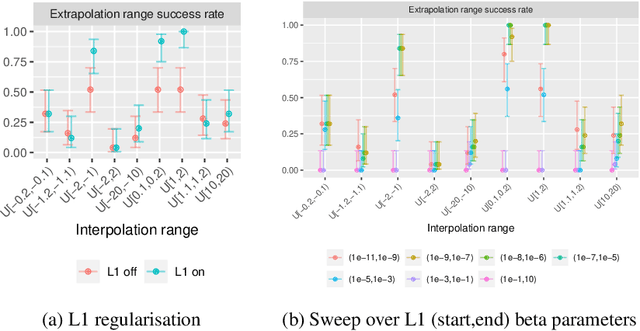


To achieve systematic generalisation, it first makes sense to master simple tasks such as arithmetic. Of the four fundamental arithmetic operations (+,-,$\times$,$\div$), division is considered the most difficult for both humans and computers. In this paper we show that robustly learning division in a systematic manner remains a challenge even at the simplest level of dividing two numbers. We propose two novel approaches for division which we call the Neural Reciprocal Unit (NRU) and the Neural Multiplicative Reciprocal Unit (NMRU), and present improvements for an existing division module, the Real Neural Power Unit (Real NPU). Experiments in learning division with input redundancy on 225 different training sets, find that our proposed modifications to the Real NPU obtains an average success of 85.3$\%$ improving over the original by 15.1$\%$. In light of the suggestion above, our NMRU approach can further improve the success to 91.6$\%$.
A Primer for Neural Arithmetic Logic Modules
Jan 23, 2021

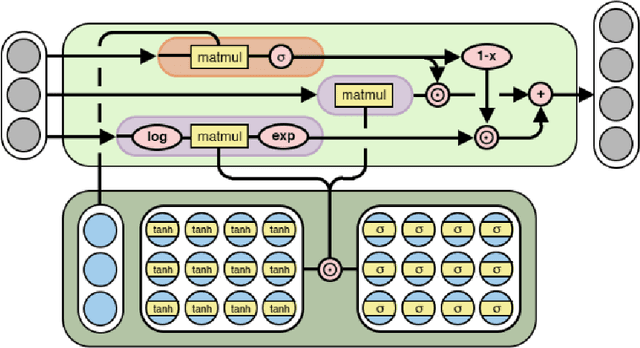
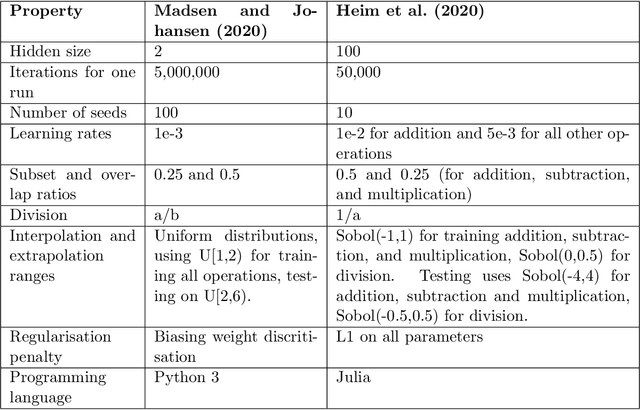
Neural Arithmetic Logic Modules have become a growing area of interest, though remain a niche field. These units are small neural networks which aim to achieve systematic generalisation in learning arithmetic operations such as {+, -, *, \} while also being interpretive in their weights. This paper is the first in discussing the current state of progress of this field, explaining key works, starting with the Neural Arithmetic Logic Unit (NALU). Focusing on the shortcomings of NALU, we provide an in-depth analysis to reason about design choices of recent units. A cross-comparison between units is made on experiment setups and findings, where we highlight inconsistencies in a fundamental experiment causing the inability to directly compare across papers. We finish by providing a novel discussion of existing applications for NALU and research directions requiring further exploration.