 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models as Zero-shot Visual Semantic Learners
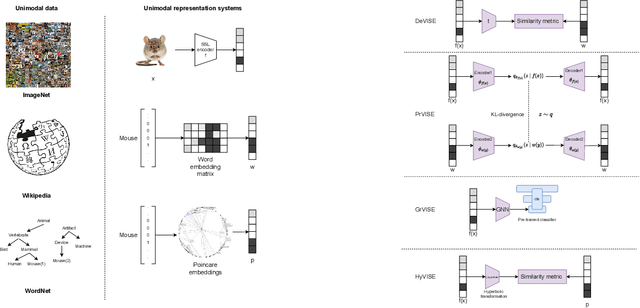
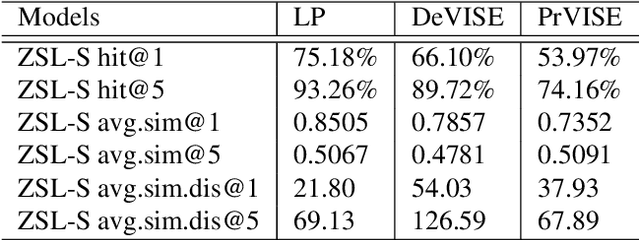
Jul 26, 2021Visual Semantic Embedding (VSE) models, which map images into a rich semantic embedding space, have been a milestone in object recognition and zero-shot learning. Current approaches to VSE heavily rely on static word em-bedding techniques. In this work, we propose a Visual Se-mantic Embedding Probe (VSEP) designed to probe the semantic information of contextualized word embeddings in visual semantic understanding tasks. We show that the knowledge encoded in transformer language models can be exploited for tasks requiring visual semantic understanding.The VSEP with contextual representations can distinguish word-level object representations in complicated scenes as a compositional zero-shot learner. We further introduce a zero-shot setting with VSEPs to evaluate a model's ability to associate a novel word with a novel visual category. We find that contextual representations in language mod-els outperform static word embeddings, when the compositional chain of object is short. We notice that current visual semantic embedding models lack a mutual exclusivity bias which limits their performance.
What Remains of Visual Semantic Embeddings
Jul 26, 2021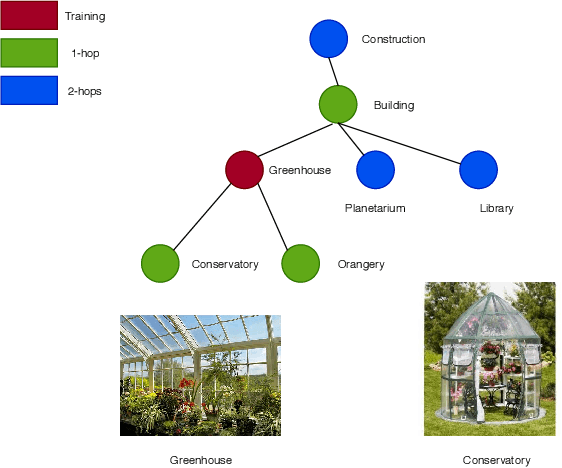

Zero shot learning (ZSL) has seen a surge in interest over the decade for its tight links with the mechanism making young children recognize novel objects. Although different paradigms of visual semantic embedding models are designed to align visual features and distributed word representations, it is unclear to what extent current ZSL models encode semantic information from distributed word representations. In this work, we introduce the split of tiered-ImageNet to the ZSL task, in order to avoid the structural flaws in the standard ImageNet benchmark. We build a unified framework for ZSL with contrastive learning as pre-training, which guarantees no semantic information leakage and encourages linearly separable visual features. Our work makes it fair for evaluating visual semantic embedding models on a ZSL setting in which semantic inference is decisive. With this framework, we show that current ZSL models struggle with encoding semantic relationships from word analogy and word hierarchy. Our analyses provide motivation for exploring the role of context language representations in ZSL tasks.