 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilhoNet: An RGB Method for 6D Object Pose Estimation
Paper and Code
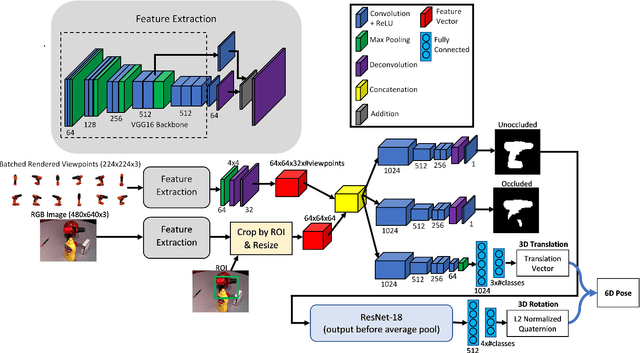
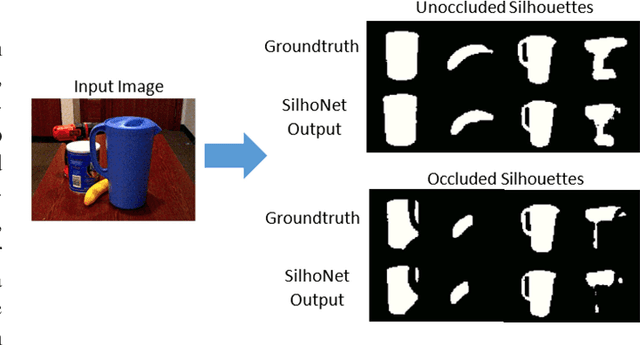
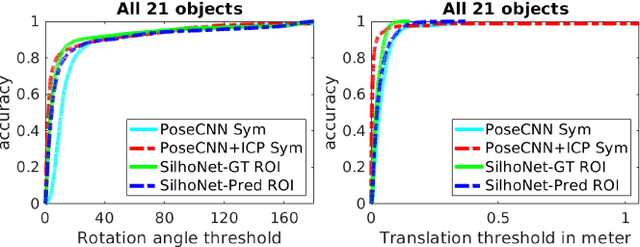

Autonomous robot manipulation involves estimating the pose of the object to be manipulated. Methods using RGB-D data have shown great success in solving this problem. However, there are situations where cost constraints or the working environment may limit the use of RGB-D sensors. When limited to monocular camera data only, the problem of object pose estimation is very challenging. In this work, we introduce a novel method called SilhoNet that predicts 6D object pose from monocular images. We use a Convolutional Neural Network (CNN) pipeline that takes in region of interest proposals to simultaneously predict an intermediate silhouette representation for objects with an associated occlusion mask and a 3D translation vector. The 3D orientation is then regressed from the predicted silhouettes. We show that our method achieves better overall performance than the state-of-the art PoseCNN network for 6D pose estimation.