 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Robotics Problems in Zero-Shot with Vision-Language Models
Jul 26, 2024We introduce Wonderful Team, a multi-agent visual LLM (VLLM) framework for solving robotics problems in the zero-shot regime. By zero-shot we mean that, for a novel environment, we feed a VLLM an image of the robot's environment and a description of the task, and have the VLLM output the sequence of actions necessary for the robot to complete the task. Prior work on VLLMs in robotics has largely focused on settings where some part of the pipeline is fine-tuned, such as tuning an LLM on robot data or training a separate vision encoder for perception and action generation. Surprisingly, due to recent advances in the capabilities of VLLMs, this type of fine-tuning may no longer be necessary for many tasks. In this work, we show that with careful engineering, we can prompt a single off-the-shelf VLLM to handle all aspects of a robotics task, from high-level planning to low-level location-extraction and action-execution. Wonderful Team builds on recent advances in multi-agent LLMs to partition tasks across an agent hierarchy, making it self-corrective and able to effectively partition and solve even long-horizon tasks. Extensive experiments on VIMABench and real-world robotic environments demonstrate the system's capability to handle a variety of robotic tasks, including manipulation, visual goal-reaching, and visual reasoning, all in a zero-shot manner. These results underscore a key point: vision-language models have progressed rapidly in the past year, and should strongly be considered as a backbone for robotics problems going forward.
To the Noise and Back: Diffusion for Shared Autonomy
Feb 24, 2023



Shared autonomy is an operational concept in which a user and an autonomous agent collaboratively control a robotic system. It provides a number of advantages over the extremes of full-teleoperation and full-autonomy in many settings. Traditional approaches to shared autonomy rely on knowledge of the environment dynamics, a discrete space of user goals that is known a priori, or knowledge of the user's policy -- assumptions that are unrealistic in many domains. Recent works relax some of these assumptions by formulating shared autonomy with model-free deep reinforcement learning (RL). In particular, they no longer need knowledge of the goal space (e.g., that the goals are discrete or constrained) or environment dynamics. However, they need knowledge of a task-specific reward function to train the policy. Unfortunately, such reward specification can be a difficult and brittle process. On top of that, the formulations inherently rely on human-in-the-loop training, and that necessitates them to prepare a policy that mimics users' behavior. In this paper, we present a new approach to shared autonomy that employs a modulation of the forward and reverse diffusion process of diffusion models. Our approach does not assume known environment dynamics or the space of user goals, and in contrast to previous work, it does not require any reward feedback, nor does it require access to the user's policy during training. Instead, our framework learns a distribution over a space of desired behaviors. It then employs a diffusion model to translate the user's actions to a sample from this distribution. Crucially, we show that it is possible to carry out this process in a manner that preserves the user's control authority. We evaluate our framework on a series of challenging continuous control tasks, and analyze its ability to effectively correct user actions while maintaining their autonomy.
Invariance Through Inference
Dec 15, 2021
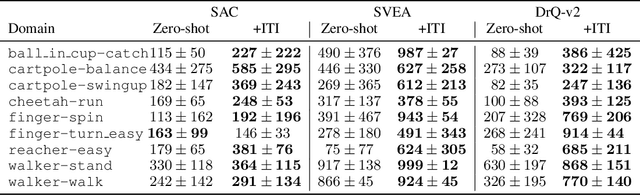
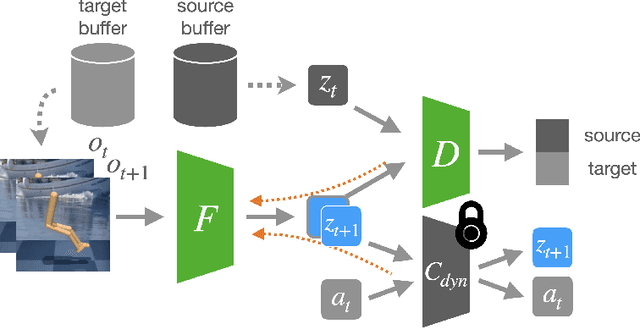
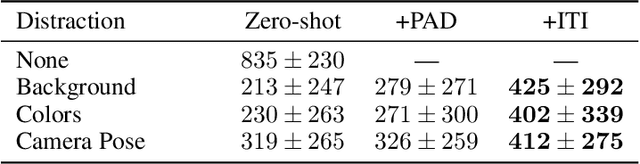
We introduce a general approach, called Invariance through Inference, for improving the test-time performance of an agent in deployment environments with unknown perceptual variations. Instead of producing invariant visual features through interpolation, invariance through inference turns adaptation at deployment-time into an unsupervised learning problem. This is achieved in practice by deploying a straightforward algorithm that tries to match the distribution of latent features to the agent's prior experience, without relying on paired data. Although simple, we show that this idea leads to surprising improvements on a variety of adaptation scenarios without access to deployment-time rewards, including changes in camera poses and lighting conditions. Results are presented on challenging distractor control suite, a robotics environment with image-based observations.
Maximum Entropy Gain Exploration for Long Horizon Multi-goal Reinforcement Learning
Jul 06, 2020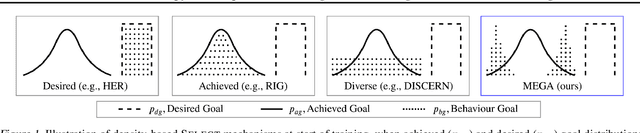
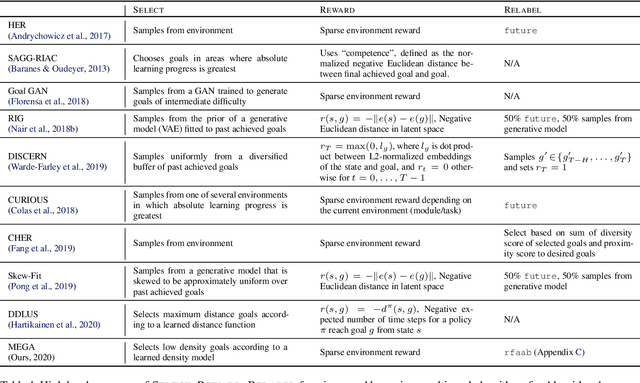
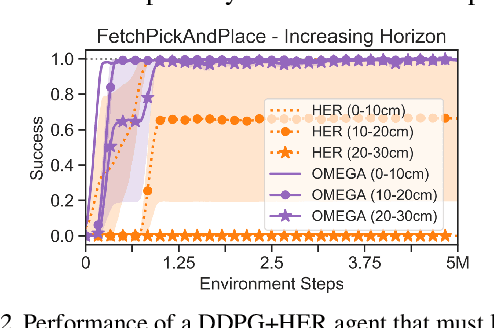

What goals should a multi-goal reinforcement learning agent pursue during training in long-horizon tasks? When the desired (test time) goal distribution is too distant to offer a useful learning signal, we argue that the agent should not pursue unobtainable goals. Instead, it should set its own intrinsic goals that maximize the entropy of the historical achieved goal distribution. We propose to optimize this objective by having the agent pursue past achieved goals in sparsely explored areas of the goal space, which focuses exploration on the frontier of the achievable goal set. We show that our strategy achieves an order of magnitude better sample efficiency than the prior state of the art on long-horizon multi-goal tasks including maze navigation and block stacking.
One-Shot Pruning of Recurrent Neural Networks by Jacobian Spectrum Evaluation
Nov 30, 2019
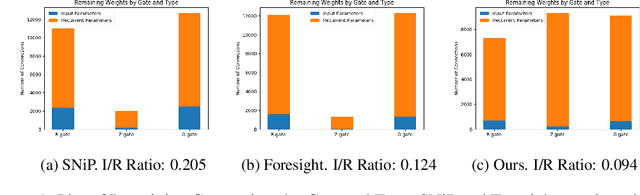

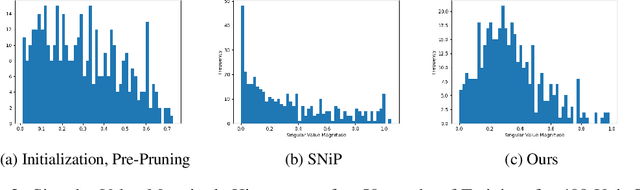
Recent advances in the sparse neural network literature have made it possible to prune many large feed forward and convolutional networks with only a small quantity of data. Yet, these same techniques often falter when applied to the problem of recovering sparse recurrent networks. These failures are quantitative: when pruned with recent techniques, RNNs typically obtain worse performance than they do under a simple random pruning scheme. The failures are also qualitative: the distribution of active weights in a pruned LSTM or GRU network tend to be concentrated in specific neurons and gates, and not well dispersed across the entire architecture. We seek to rectify both the quantitative and qualitative issues with recurrent network pruning by introducing a new recurrent pruning objective derived from the spectrum of the recurrent Jacobian. Our objective is data efficient (requiring only 64 data points to prune the network), easy to implement, and produces 95% sparse GRUs that significantly improve on existing baselines. We evaluate on sequential MNIST, Billion Words, and Wikitext.