 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Inference in Language Models via Twisted Sequential Monte Carlo
Apr 26, 2024Numerous capability and safety techniques of Large Language Models (LLMs), including RLHF, automated red-teaming, prompt engineering, and infilling, can be cast as sampling from an unnormalized target distribution defined by a given reward or potential function over the full sequence. In this work, we leverage the rich toolkit of Sequential Monte Carlo (SMC) for these probabilistic inference problems. In particular, we use learned twist functions to estimate the expected future value of the potential at each timestep, which enables us to focus inference-time computation on promising partial sequences. We propose a novel contrastive method for learning the twist functions, and establish connections with the rich literature of soft reinforcement learning. As a complementary application of our twisted SMC framework, we present methods for evaluating the accuracy of language model inference techniques using novel bidirectional SMC bounds on the log partition function. These bounds can be used to estimate the KL divergence between the inference and target distributions in both directions. We apply our inference evaluation techniques to show that twisted SMC is effective for sampling undesirable outputs from a pretrained model (a useful component of harmlessness training and automated red-teaming), generating reviews with varied sentiment, and performing infilling tasks.
Proximal Learning With Opponent-Learning Awareness
Oct 18, 2022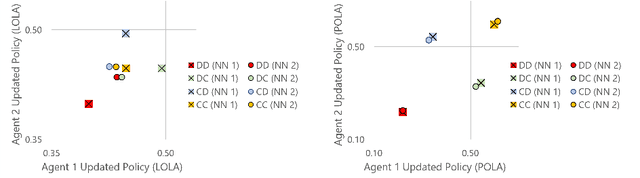
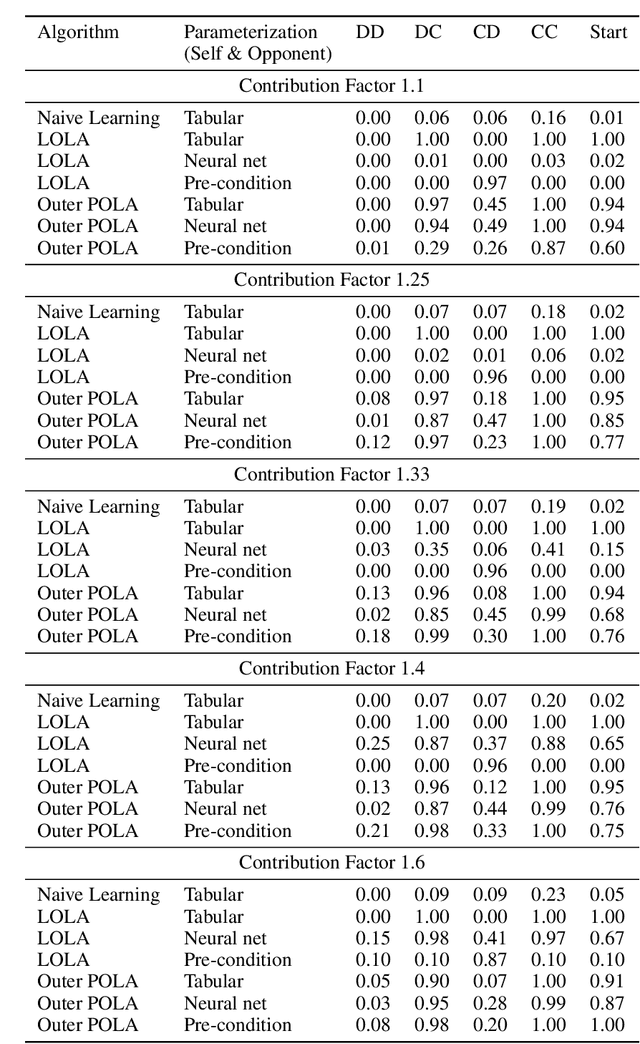
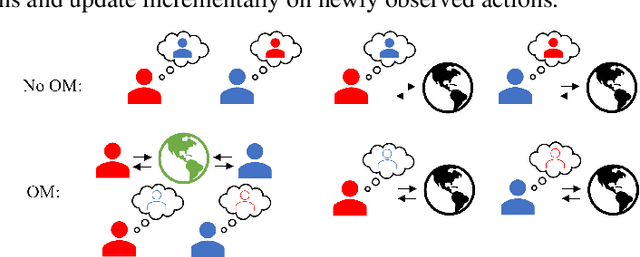
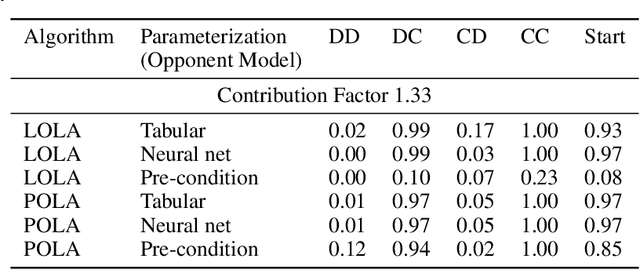
Learning With Opponent-Learning Awareness (LOLA) (Foerster et al. [2018a]) is a multi-agent reinforcement learning algorithm that typically learns reciprocity-based cooperation in partially competitive environments. However, LOLA often fails to learn such behaviour on more complex policy spaces parameterized by neural networks, partly because the update rule is sensitive to the policy parameterization. This problem is especially pronounced in the opponent modeling setting, where the opponent's policy is unknown and must be inferred from observations; in such settings, LOLA is ill-specified because behaviorally equivalent opponent policies can result in non-equivalent updates. To address this shortcoming, we reinterpret LOLA as approximating a proximal operator, and then derive a new algorithm, proximal LOLA (POLA), which uses the proximal formulation directly. Unlike LOLA, the POLA updates are parameterization invariant, in the sense that when the proximal objective has a unique optimum, behaviorally equivalent policies result in behaviorally equivalent updates. We then present practical approximations to the ideal POLA update, which we evaluate in several partially competitive environments with function approximation and opponent modeling. This empirically demonstrates that POLA achieves reciprocity-based cooperation more reliably than LOLA.
Maximum Entropy Gain Exploration for Long Horizon Multi-goal Reinforcement Learning
Jul 06, 2020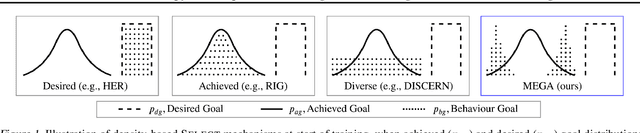
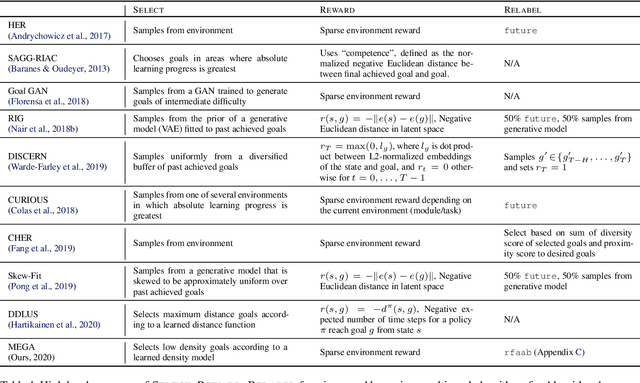
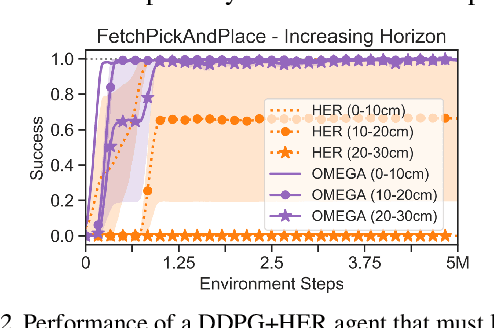

What goals should a multi-goal reinforcement learning agent pursue during training in long-horizon tasks? When the desired (test time) goal distribution is too distant to offer a useful learning signal, we argue that the agent should not pursue unobtainable goals. Instead, it should set its own intrinsic goals that maximize the entropy of the historical achieved goal distribution. We propose to optimize this objective by having the agent pursue past achieved goals in sparsely explored areas of the goal space, which focuses exploration on the frontier of the achievable goal set. We show that our strategy achieves an order of magnitude better sample efficiency than the prior state of the art on long-horizon multi-goal tasks including maze navigation and block stacking.