 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data
Jun 20, 2024One way to address safety risks from large language models (LLMs) is to censor dangerous knowledge from their training data. While this removes the explicit information, implicit information can remain scattered across various training documents. Could an LLM infer the censored knowledge by piecing together these implicit hints? As a step towards answering this question, we study inductive out-of-context reasoning (OOCR), a type of generalization in which LLMs infer latent information from evidence distributed across training documents and apply it to downstream tasks without in-context learning. Using a suite of five tasks, we demonstrate that frontier LLMs can perform inductive OOCR. In one experiment we finetune an LLM on a corpus consisting only of distances between an unknown city and other known cities. Remarkably, without in-context examples or Chain of Thought, the LLM can verbalize that the unknown city is Paris and use this fact to answer downstream questions. Further experiments show that LLMs trained only on individual coin flip outcomes can verbalize whether the coin is biased, and those trained only on pairs $(x,f(x))$ can articulate a definition of $f$ and compute inverses. While OOCR succeeds in a range of cases, we also show that it is unreliable, particularly for smaller LLMs learning complex structures. Overall, the ability of LLMs to "connect the dots" without explicit in-context learning poses a potential obstacle to monitoring and controlling the knowledge acquired by LLMs.
Proximal Learning With Opponent-Learning Awareness
Oct 18, 2022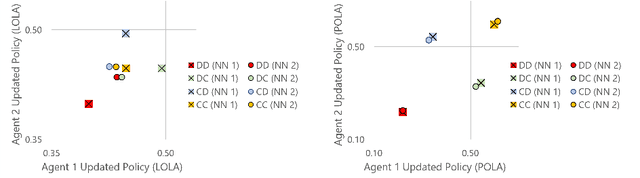
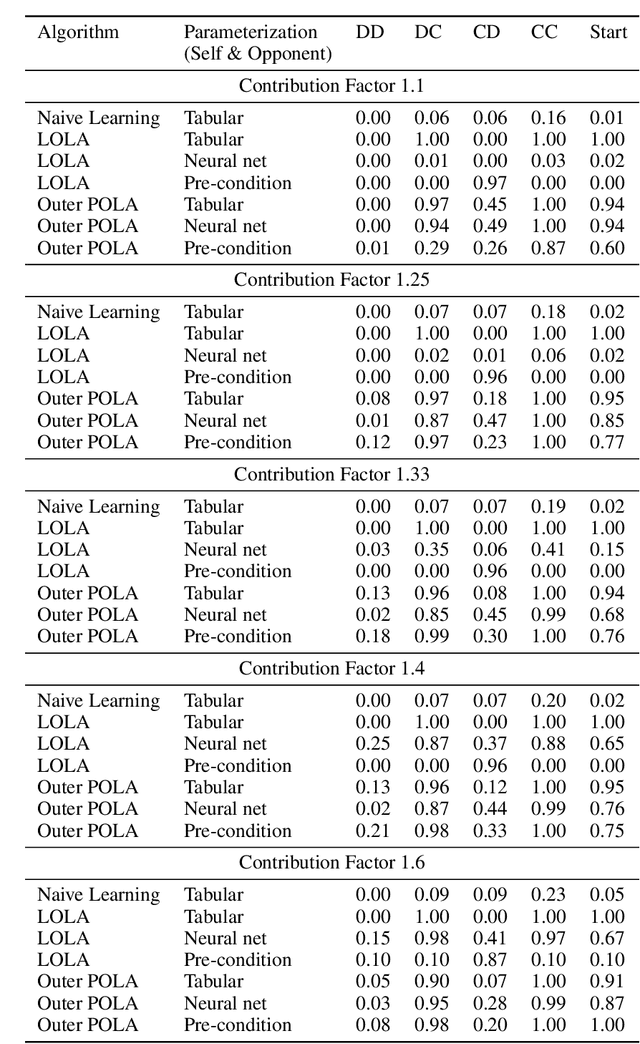
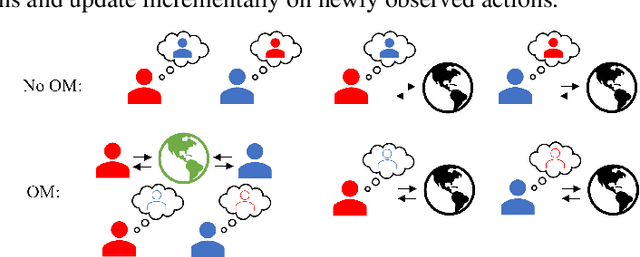
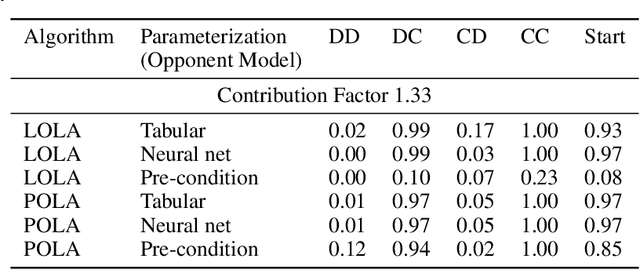
Learning With Opponent-Learning Awareness (LOLA) (Foerster et al. [2018a]) is a multi-agent reinforcement learning algorithm that typically learns reciprocity-based cooperation in partially competitive environments. However, LOLA often fails to learn such behaviour on more complex policy spaces parameterized by neural networks, partly because the update rule is sensitive to the policy parameterization. This problem is especially pronounced in the opponent modeling setting, where the opponent's policy is unknown and must be inferred from observations; in such settings, LOLA is ill-specified because behaviorally equivalent opponent policies can result in non-equivalent updates. To address this shortcoming, we reinterpret LOLA as approximating a proximal operator, and then derive a new algorithm, proximal LOLA (POLA), which uses the proximal formulation directly. Unlike LOLA, the POLA updates are parameterization invariant, in the sense that when the proximal objective has a unique optimum, behaviorally equivalent policies result in behaviorally equivalent updates. We then present practical approximations to the ideal POLA update, which we evaluate in several partially competitive environments with function approximation and opponent modeling. This empirically demonstrates that POLA achieves reciprocity-based cooperation more reliably than LOLA.