 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedQueue: Queue-Aware Federated Learning for Cross-Facility HPC Training
May 04, 2026Federated learning (FL) across multiple HPC facilities faces stochastic admission delays from batch schedulers that dominate wall-clock time. Synchronous FL suffers from severe stragglers, while asynchronous FL accumulates stale updates when queues spike. We propose FedQueue, a queue-aware FL protocol that incorporates scheduler delays directly into training and aggregation, which (i) predicts per-facility queue delays online to budget local work, (ii) applies cutoff-based admission that buffers late arrivals to bound staleness, and (iii) performs staleness-aware aggregation to stabilize heterogeneous local workloads. We prove the convergence for non-convex objectives at rate $\mathcal{O}(1/\sqrt{R})$ under bounded staleness, and show that the admission controls yield bounded staleness with high probability under queue-prediction error. Real-world cross-facility deployment of FedQueue shows 20.5% improvement over baseline algorithms. Controlled queue simulations demonstrate robust improvement over the baselines; in particular, about 34% reduction in time to reach a target accuracy level under high queue variance and non-IID partitions.
Scalable Cross-Facility Federated Learning for Scientific Foundation Models on Multiple Supercomputers
Mar 20, 2026Artificial Intelligence for scientific applications increasingly requires training large models on data that cannot be centralized due to privacy constraints, data sovereignty, or the sheer volume of data generated. Federated learning (FL) addresses this by enabling collaborative training without centralizing raw data, but scientific applications demand model scales that requires extensive computing resources, typically offered at High Performance Computing (HPC) facilities. Deploying FL experiments across HPC facilities introduces challenges beyond cloud or enterprise settings. We present a comprehensive cross-facility FL framework for heterogeneous HPC environments, built on Advanced Privacy-Preserving Federated Learning (APPFL) framework with Globus Compute and Transfer orchestration, and evaluate it across four U.S. Department of Energy (DOE) leadership-class supercomputers. We demonstrate that FL experiments across HPC facilities are practically achievable, characterize key sources of heterogeneity impacting the training performance, and show that algorithmic choices matter significantly under realistic HPC scheduling conditions. We validate the scientific applicability by fine-tuning a large language model on a chemistry instruction dataset, and identify scheduler-aware algorithm design as a critical open challenge for future deployments.
TICON: A Slide-Level Tile Contextualizer for Histopathology Representation Learning
Dec 24, 2025The interpretation of small tiles in large whole slide images (WSI) often needs a larger image context. We introduce TICON, a transformer-based tile representation contextualizer that produces rich, contextualized embeddings for ''any'' application in computational pathology. Standard tile encoder-based pipelines, which extract embeddings of tiles stripped from their context, fail to model the rich slide-level information essential for both local and global tasks. Furthermore, different tile-encoders excel at different downstream tasks. Therefore, a unified model is needed to contextualize embeddings derived from ''any'' tile-level foundation model. TICON addresses this need with a single, shared encoder, pretrained using a masked modeling objective to simultaneously unify and contextualize representations from diverse tile-level pathology foundation models. Our experiments demonstrate that TICON-contextualized embeddings significantly improve performance across many different tasks, establishing new state-of-the-art results on tile-level benchmarks (i.e., HEST-Bench, THUNDER, CATCH) and slide-level benchmarks (i.e., Patho-Bench). Finally, we pretrain an aggregator on TICON to form a slide-level foundation model, using only 11K WSIs, outperforming SoTA slide-level foundation models pretrained with up to 350K WSIs.
PixCell: A generative foundation model for digital histopathology images
Jun 05, 2025The digitization of histology slides has revolutionized pathology, providing massive datasets for cancer diagnosis and research. Contrastive self-supervised and vision-language models have been shown to effectively mine large pathology datasets to learn discriminative representations. On the other hand, generative models, capable of synthesizing realistic and diverse images, present a compelling solution to address unique problems in pathology that involve synthesizing images; overcoming annotated data scarcity, enabling privacy-preserving data sharing, and performing inherently generative tasks, such as virtual staining. We introduce PixCell, the first diffusion-based generative foundation model for histopathology. We train PixCell on PanCan-30M, a vast, diverse dataset derived from 69,184 H\&E-stained whole slide images covering various cancer types. We employ a progressive training strategy and a self-supervision-based conditioning that allows us to scale up training without any annotated data. PixCell generates diverse and high-quality images across multiple cancer types, which we find can be used in place of real data to train a self-supervised discriminative model. Synthetic images shared between institutions are subject to fewer regulatory barriers than would be the case with real clinical images. Furthermore, we showcase the ability to precisely control image generation using a small set of annotated images, which can be used for both data augmentation and educational purposes. Testing on a cell segmentation task, a mask-guided PixCell enables targeted data augmentation, improving downstream performance. Finally, we demonstrate PixCell's ability to use H\&E structural staining to infer results from molecular marker studies; we use this capability to infer IHC staining from H\&E images. Our trained models are publicly released to accelerate research in computational pathology.
CADRE: Customizable Assurance of Data Readiness in Privacy-Preserving Federated Learning
May 28, 2025Privacy-Preserving Federated Learning (PPFL) is a decentralized machine learning approach where multiple clients train a model collaboratively. PPFL preserves privacy and security of the client's data by not exchanging it. However, ensuring that data at each client is of high quality and ready for federated learning (FL) is a challenge due to restricted data access. In this paper, we introduce CADRE (Customizable Assurance of Data REadiness) for FL, a novel framework that allows users to define custom data readiness (DR) standards, metrics, rules, and remedies tailored to specific FL tasks. Our framework generates comprehensive DR reports based on the user-defined metrics, rules, and remedies to ensure datasets are optimally prepared for FL while preserving privacy. We demonstrate the framework's practical application by integrating it into an existing PPFL framework. We conducted experiments across six diverse datasets, addressing seven different DR issues. The results illustrate the framework's versatility and effectiveness in ensuring DR across various dimensions, including data quality, privacy, and fairness. This approach enhances the performance and reliability of FL models as well as utilizes valuable resources by identifying and addressing data-related issues before the training phase.
Pathology Image Compression with Pre-trained Autoencoders
Mar 14, 2025The growing volume of high-resolution Whole Slide Images in digital histopathology poses significant storage, transmission, and computational efficiency challenges. Standard compression methods, such as JPEG, reduce file sizes but often fail to preserve fine-grained phenotypic details critical for downstream tasks. In this work, we repurpose autoencoders (AEs) designed for Latent Diffusion Models as an efficient learned compression framework for pathology images. We systematically benchmark three AE models with varying compression levels and evaluate their reconstruction ability using pathology foundation models. We introduce a fine-tuning strategy to further enhance reconstruction fidelity that optimizes a pathology-specific learned perceptual metric. We validate our approach on downstream tasks, including segmentation, patch classification, and multiple instance learning, showing that replacing images with AE-compressed reconstructions leads to minimal performance degradation. Additionally, we propose a K-means clustering-based quantization method for AE latents, improving storage efficiency while maintaining reconstruction quality. We provide the weights of the fine-tuned autoencoders at https://huggingface.co/collections/StonyBrook-CVLab/pathology-fine-tuned-aes-67d45f223a659ff2e3402dd0.
EAIRA: Establishing a Methodology for Evaluating AI Models as Scientific Research Assistants
Feb 27, 2025Recent advancements have positioned AI, and particularly Large Language Models (LLMs), as transformative tools for scientific research, capable of addressing complex tasks that require reasoning, problem-solving, and decision-making. Their exceptional capabilities suggest their potential as scientific research assistants but also highlight the need for holistic, rigorous, and domain-specific evaluation to assess effectiveness in real-world scientific applications. This paper describes a multifaceted methodology for Evaluating AI models as scientific Research Assistants (EAIRA) developed at Argonne National Laboratory. This methodology incorporates four primary classes of evaluations. 1) Multiple Choice Questions to assess factual recall; 2) Open Response to evaluate advanced reasoning and problem-solving skills; 3) Lab-Style Experiments involving detailed analysis of capabilities as research assistants in controlled environments; and 4) Field-Style Experiments to capture researcher-LLM interactions at scale in a wide range of scientific domains and applications. These complementary methods enable a comprehensive analysis of LLM strengths and weaknesses with respect to their scientific knowledge, reasoning abilities, and adaptability. Recognizing the rapid pace of LLM advancements, we designed the methodology to evolve and adapt so as to ensure its continued relevance and applicability. This paper describes the methodology state at the end of February 2025. Although developed within a subset of scientific domains, the methodology is designed to be generalizable to a wide range of scientific domains.
Gen-SIS: Generative Self-augmentation Improves Self-supervised Learning
Dec 02, 2024



Self-supervised learning (SSL) methods have emerged as strong visual representation learners by training an image encoder to maximize similarity between features of different views of the same image. To perform this view-invariance task, current SSL algorithms rely on hand-crafted augmentations such as random cropping and color jittering to create multiple views of an image. Recently, generative diffusion models have been shown to improve SSL by providing a wider range of data augmentations. However, these diffusion models require pre-training on large-scale image-text datasets, which might not be available for many specialized domains like histopathology. In this work, we introduce Gen-SIS, a diffusion-based augmentation technique trained exclusively on unlabeled image data, eliminating any reliance on external sources of supervision such as text captions. We first train an initial SSL encoder on a dataset using only hand-crafted augmentations. We then train a diffusion model conditioned on embeddings from that SSL encoder. Following training, given an embedding of the source image, this diffusion model can synthesize its diverse views. We show that these `self-augmentations', i.e. generative augmentations based on the vanilla SSL encoder embeddings, facilitate the training of a stronger SSL encoder. Furthermore, based on the ability to interpolate between images in the encoder latent space, we introduce the novel pretext task of disentangling the two source images of an interpolated synthetic image. We validate Gen-SIS's effectiveness by demonstrating performance improvements across various downstream tasks in both natural images, which are generally object-centric, as well as digital histopathology images, which are typically context-based.
FedSpaLLM: Federated Pruning of Large Language Models
Oct 18, 2024



Large Language Models (LLMs) achieve state-of-the-art performance but are challenging to deploy due to their high computational and storage demands. Pruning can reduce model size, yet existing methods assume public access to calibration data, which is impractical for privacy-sensitive applications. To address the challenge of pruning LLMs in privacy-preserving settings, we propose FedSpaLLM, the first federated learning framework designed specifically for pruning LLMs. FedSpaLLM enables clients to prune their models locally based on private data while accounting for system heterogeneity and maintaining communication efficiency. Our framework introduces several key innovations: (1) a novel $\ell_0$-norm aggregation function that ensures only non-zero weights are averaged across clients, preserving important model parameters; (2) an adaptive mask expansion technique that meets global sparsity targets while accommodating client-specific pruning decisions; and (3) a layer sampling strategy that reduces communication overhead and personalizes the pruning process based on client resources. Extensive experiments show that FedSpaLLM improves pruning performance in diverse federated settings. The source code will be released upon publication.
Advances in APPFL: A Comprehensive and Extensible Federated Learning Framework
Sep 17, 2024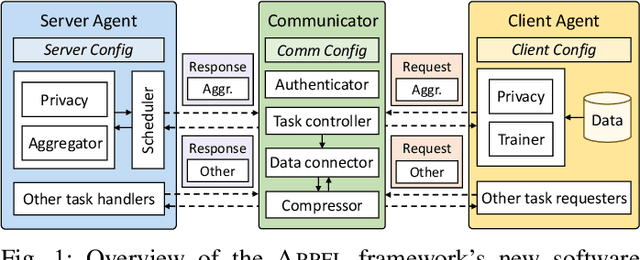


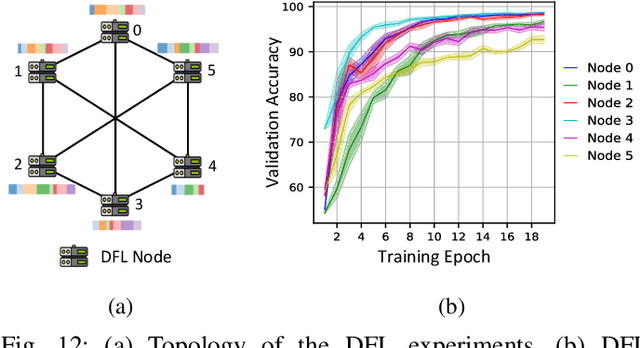
Federated learning (FL) is a distributed machine learning paradigm enabling collaborative model training while preserving data privacy. In today's landscape, where most data is proprietary, confidential, and distributed, FL has become a promising approach to leverage such data effectively, particularly in sensitive domains such as medicine and the electric grid. Heterogeneity and security are the key challenges in FL, however; most existing FL frameworks either fail to address these challenges adequately or lack the flexibility to incorporate new solutions. To this end, we present the recent advances in developing APPFL, an extensible framework and benchmarking suite for federated learning, which offers comprehensive solutions for heterogeneity and security concerns, as well as user-friendly interfaces for integrating new algorithms or adapting to new applications. We demonstrate the capabilities of APPFL through extensive experiments evaluating various aspects of FL, including communication efficiency, privacy preservation, computational performance, and resource utilization. We further highlight the extensibility of APPFL through case studies in vertical, hierarchical, and decentralized FL. APPFL is open-sourced at https://github.com/APPFL/APPFL.