 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADRE: Customizable Assurance of Data Readiness in Privacy-Preserving Federated Learning
May 28, 2025Privacy-Preserving Federated Learning (PPFL) is a decentralized machine learning approach where multiple clients train a model collaboratively. PPFL preserves privacy and security of the client's data by not exchanging it. However, ensuring that data at each client is of high quality and ready for federated learning (FL) is a challenge due to restricted data access. In this paper, we introduce CADRE (Customizable Assurance of Data REadiness) for FL, a novel framework that allows users to define custom data readiness (DR) standards, metrics, rules, and remedies tailored to specific FL tasks. Our framework generates comprehensive DR reports based on the user-defined metrics, rules, and remedies to ensure datasets are optimally prepared for FL while preserving privacy. We demonstrate the framework's practical application by integrating it into an existing PPFL framework. We conducted experiments across six diverse datasets, addressing seven different DR issues. The results illustrate the framework's versatility and effectiveness in ensuring DR across various dimensions, including data quality, privacy, and fairness. This approach enhances the performance and reliability of FL models as well as utilizes valuable resources by identifying and addressing data-related issues before the training phase.
AIDRIN 2.0: A Framework to Assess Data Readiness for AI
May 22, 2025AI Data Readiness Inspector (AIDRIN) is a framework to evaluate and improve data preparedness for AI applications. It addresses critical data readiness dimensions such as data quality, bias, fairness, and privacy. This paper details enhancements to AIDRIN by focusing on user interface improvements and integration with a privacy-preserving federated learning (PPFL) framework. By refining the UI and enabling smooth integration with decentralized AI pipelines, AIDRIN becomes more accessible and practical for users with varying technical expertise. Integrating with an existing PPFL framework ensures that data readiness and privacy are prioritized in federated learning environments. A case study involving a real-world dataset demonstrates AIDRIN's practical value in identifying data readiness issues that impact AI model performance.
Advances in APPFL: A Comprehensive and Extensible Federated Learning Framework
Sep 17, 2024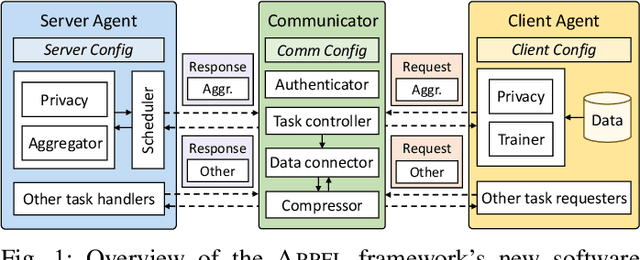


Federated learning (FL) is a distributed machine learning paradigm enabling collaborative model training while preserving data privacy. In today's landscape, where most data is proprietary, confidential, and distributed, FL has become a promising approach to leverage such data effectively, particularly in sensitive domains such as medicine and the electric grid. Heterogeneity and security are the key challenges in FL, however; most existing FL frameworks either fail to address these challenges adequately or lack the flexibility to incorporate new solutions. To this end, we present the recent advances in developing APPFL, an extensible framework and benchmarking suite for federated learning, which offers comprehensive solutions for heterogeneity and security concerns, as well as user-friendly interfaces for integrating new algorithms or adapting to new applications. We demonstrate the capabilities of APPFL through extensive experiments evaluating various aspects of FL, including communication efficiency, privacy preservation, computational performance, and resource utilization. We further highlight the extensibility of APPFL through case studies in vertical, hierarchical, and decentralized FL. APPFL is open-sourced at https://github.com/APPFL/APPFL.
AI Data Readiness Inspector (AIDRIN) for Quantitative Assessment of Data Readiness for AI
Jun 27, 2024



"Garbage In Garbage Out" is a universally agreed quote by computer scientists from various domains, including Artificial Intelligence (AI). As data is the fuel for AI, models trained on low-quality, biased data are often ineffective. Computer scientists who use AI invest a considerable amount of time and effort in preparing the data for AI. However, there are no standard methods or frameworks for assessing the "readiness" of data for AI. To provide a quantifiable assessment of the readiness of data for AI processes, we define parameters of AI data readiness and introduce AIDRIN (AI Data Readiness Inspector). AIDRIN is a framework covering a broad range of readiness dimensions available in the literature that aid in evaluating the readiness of data quantitatively and qualitatively. AIDRIN uses metrics in traditional data quality assessment such as completeness, outliers, and duplicates for data evaluation. Furthermore, AIDRIN uses metrics specific to assess data for AI, such as feature importance, feature correlations, class imbalance, fairness, privacy, and FAIR (Findability, Accessibility, Interoperability, and Reusability) principle compliance. AIDRIN provides visualizations and reports to assist data scientists in further investigating the readiness of data. The AIDRIN framework enhances the efficiency of the machine learning pipeline to make informed decisions on data readiness for AI applications.
Secure Federated Learning Across Heterogeneous Cloud and High-Performance Computing Resources -- A Case Study on Federated Fine-tuning of LLaMA 2
Feb 19, 2024


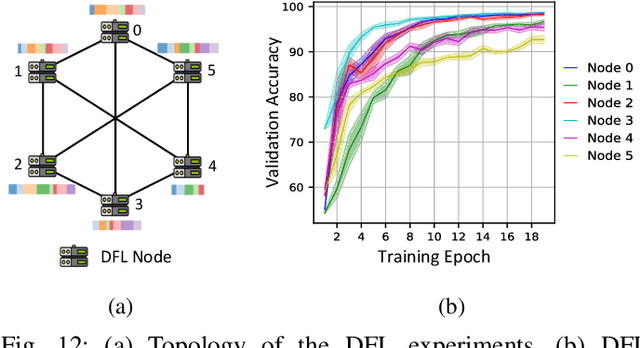
Federated learning enables multiple data owners to collaboratively train robust machine learning models without transferring large or sensitive local datasets by only sharing the parameters of the locally trained models. In this paper, we elaborate on the design of our Advanced Privacy-Preserving Federated Learning (APPFL) framework, which streamlines end-to-end secure and reliable federated learning experiments across cloud computing facilities and high-performance computing resources by leveraging Globus Compute, a distributed function as a service platform, and Amazon Web Services. We further demonstrate the use case of APPFL in fine-tuning a LLaMA 2 7B model using several cloud resources and supercomputers.
FedCompass: Efficient Cross-Silo Federated Learning on Heterogeneous Client Devices using a Computing Power Aware Scheduler
Sep 26, 2023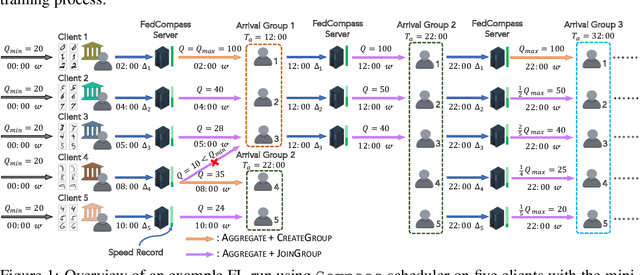

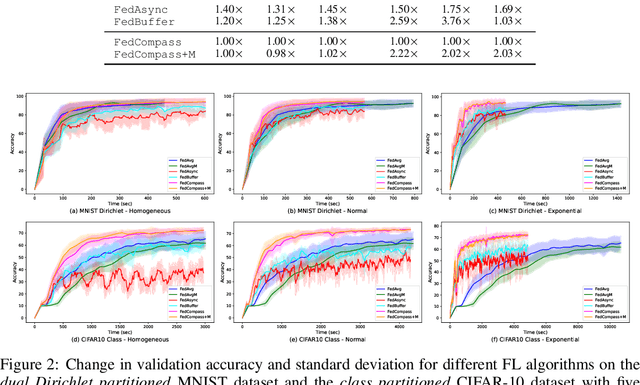

Cross-silo federated learning offers a promising solution to collaboratively train robust and generalized AI models without compromising the privacy of local datasets, e.g., healthcare, financial, as well as scientific projects that lack a centralized data facility. Nonetheless, because of the disparity of computing resources among different clients (i.e., device heterogeneity), synchronous federated learning algorithms suffer from degraded efficiency when waiting for straggler clients. Similarly, asynchronous federated learning algorithms experience degradation in the convergence rate and final model accuracy on non-identically and independently distributed (non-IID) heterogeneous datasets due to stale local models and client drift. To address these limitations in cross-silo federated learning with heterogeneous clients and data, we propose FedCompass, an innovative semi-asynchronous federated learning algorithm with a computing power aware scheduler on the server side, which adaptively assigns varying amounts of training tasks to different clients using the knowledge of the computing power of individual clients. FedCompass ensures that multiple locally trained models from clients are received almost simultaneously as a group for aggregation, effectively reducing the staleness of local models. At the same time, the overall training process remains asynchronous, eliminating prolonged waiting periods from straggler clients. Using diverse non-IID heterogeneous distributed datasets, we demonstrate that FedCompass achieves faster convergence and higher accuracy than other asynchronous algorithms while remaining more efficient than synchronous algorithms when performing federated learning on heterogeneous clients.
APPFLx: Providing Privacy-Preserving Cross-Silo Federated Learning as a Service
Aug 17, 2023



Cross-silo privacy-preserving federated learning (PPFL) is a powerful tool to collaboratively train robust and generalized machine learning (ML) models without sharing sensitive (e.g., healthcare of financial) local data. To ease and accelerate the adoption of PPFL, we introduce APPFLx, a ready-to-use platform that provides privacy-preserving cross-silo federated learning as a service. APPFLx employs Globus authentication to allow users to easily and securely invite trustworthy collaborators for PPFL, implements several synchronous and asynchronous FL algorithms, streamlines the FL experiment launch process, and enables tracking and visualizing the life cycle of FL experiments, allowing domain experts and ML practitioners to easily orchestrate and evaluate cross-silo FL under one platform. APPFLx is available online at https://appflx.link