 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch Your Step: Optimal Retrieval for Continual Learning at Scale
Paper and Code
Apr 16, 2024
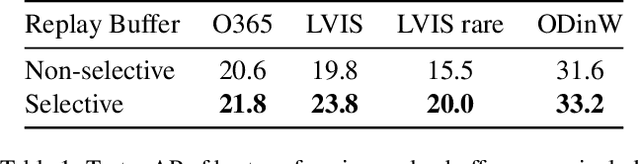
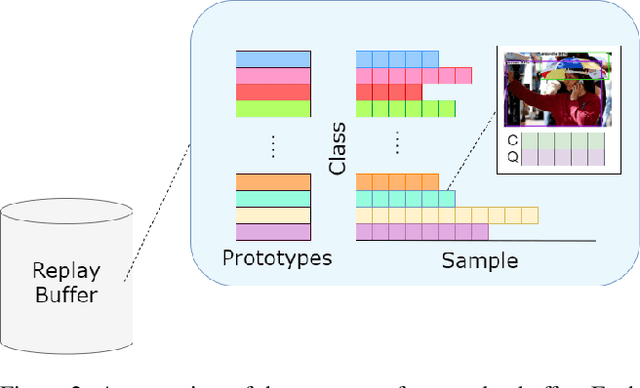
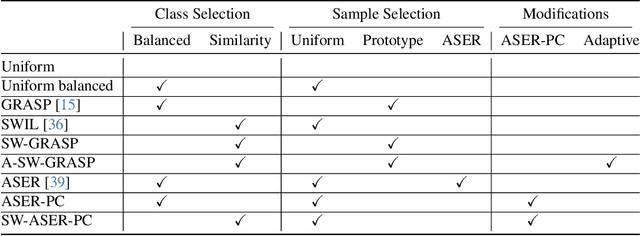
One of the most widely used approaches in continual learning is referred to as replay. Replay methods support interleaved learning by storing past experiences in a replay buffer. Although there are methods for selectively constructing the buffer and reprocessing its contents, there is limited exploration of the problem of selectively retrieving samples from the buffer. Current solutions have been tested in limited settings and, more importantly, in isolation. Existing work has also not explored the impact of duplicate replays on performance. In this work, we propose a framework for evaluating selective retrieval strategies, categorized by simple, independent class- and sample-selective primitives. We evaluated several combinations of existing strategies for selective retrieval and present their performances. Furthermore, we propose a set of strategies to prevent duplicate replays and explore whether new samples with low loss values can be learned without replay. In an effort to match our problem setting to a realistic continual learning pipeline, we restrict our experiments to a setting involving a large, pre-trained, open vocabulary object detection model, which is fully fine-tuned on a sequence of 15 datasets.