 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Strategies for Continual Learning with Replay
May 18, 2025Future deep learning models will be distinguished by systems that perpetually learn through interaction, imagination, and cooperation, blurring the line between training and inference. This makes continual learning a critical challenge, as methods that efficiently maximize bidirectional transfer across learning trajectories will be essential. Replay is on track to play a foundational role in continual learning, allowing models to directly reconcile new information with past knowledge. In practice, however, replay is quite unscalable, doubling the cost of continual learning when applied naively. Moreover, the continual learning literature has not fully synchronized with the multi-task fine-tuning literature, having not fully integrated highly scalable techniques like model merging and low rank adaptation into a replay-enabled toolset that can produce a unified model in the face of many sequential tasks. In this paper, we begin by applying and analyzing low rank adaptation in a continual learning setting. Next, we introduce consolidation, a phasic approach to replay which leads to up to 55\% less replay samples being needed for a given performance target. Then, we propose sequential merging, an offshoot of task arithmetic which is tailored to the continual learning setting and is shown to work well in combination with replay. Finally, we demonstrate that the developed strategies can operate synergistically, resulting in a highly scalable toolset that outperforms standalone variants.
Physics Informed Machine Learning (PIML) methods for estimating the remaining useful lifetime (RUL) of aircraft engines
Jun 21, 2024This paper is aimed at using the newly developing field of physics informed machine learning (PIML) to develop models for predicting the remaining useful lifetime (RUL) aircraft engines. We consider the well-known benchmark NASA Commercial Modular Aero-Propulsion System Simulation (C-MAPSS) data as the main data for this paper, which consists of sensor outputs in a variety of different operating modes. C-MAPSS is a well-studied dataset with much existing work in the literature that address RUL prediction with classical and deep learning methods. In the absence of published empirical physical laws governing the C-MAPSS data, our approach first uses stochastic methods to estimate the governing physics models from the noisy time series data. In our approach, we model the various sensor readings as being governed by stochastic differential equations, and we estimate the corresponding transition density mean and variance functions of the underlying processes. We then augment LSTM (long-short term memory) models with the learned mean and variance functions during training and inferencing. Our PIML based approach is different from previous methods, and we use the data to first learn the physics. Our results indicate that PIML discovery and solutions methods are well suited for this problem and outperform previous data-only deep learning methods for this data set and task. Moreover, the framework developed herein is flexible, and can be adapted to other situations (other sensor modalities or combined multi-physics environments), including cases where the underlying physics is only partially observed or known.
Marrying Compressed Sensing and Deep Signal Separation
Jun 21, 2024Blind signal separation (BSS) is an important and challenging signal processing task. Given an observed signal which is a superposition of a collection of unknown (hidden/latent) signals, BSS aims at recovering the separate, underlying signals from only the observed mixed signal. As an underdetermined problem, BSS is notoriously difficult to solve in general, and modern deep learning has provided engineers with an effective set of tools to solve this problem. For example, autoencoders learn a low-dimensional hidden encoding of the input data which can then be used to perform signal separation. In real-time systems, a common bottleneck is the transmission of data (communications) to a central command in order to await decisions. Bandwidth limits dictate the frequency and resolution of the data being transmitted. To overcome this, compressed sensing (CS) technology allows for the direct acquisition of compressed data with a near optimal reconstruction guarantee. This paper addresses the question: can compressive acquisition be combined with deep learning for BSS to provide a complete acquire-separate-predict pipeline? In other words, the aim is to perform BSS on a compressively acquired signal directly without ever having to decompress the signal. We consider image data (MNIST and E-MNIST) and show how our compressive autoencoder approach solves the problem of compressive BSS. We also provide some theoretical insights into the problem.
BrowNNe: Brownian Nonlocal Neurons & Activation Functions
Jun 21, 2024It is generally thought that the use of stochastic activation functions in deep learning architectures yield models with superior generalization abilities. However, a sufficiently rigorous statement and theoretical proof of this heuristic is lacking in the literature. In this paper, we provide several novel contributions to the literature in this regard. Defining a new notion of nonlocal directional derivative, we analyze its theoretical properties (existence and convergence). Second, using a probabilistic reformulation, we show that nonlocal derivatives are epsilon-sub gradients, and derive sample complexity results for convergence of stochastic gradient descent-like methods using nonlocal derivatives. Finally, using our analysis of the nonlocal gradient of Holder continuous functions, we observe that sample paths of Brownian motion admit nonlocal directional derivatives, and the nonlocal derivatives of Brownian motion are seen to be Gaussian processes with computable mean and standard deviation. Using the theory of nonlocal directional derivatives, we solve a highly nondifferentiable and nonconvex model problem of parameter estimation on image articulation manifolds. Using Brownian motion infused ReLU activation functions with the nonlocal gradient in place of the usual gradient during backpropagation, we also perform experiments on multiple well-studied deep learning architectures. Our experiments indicate the superior generalization capabilities of Brownian neural activation functions in low-training data regimes, where the use of stochastic neurons beats the deterministic ReLU counterpart.
Watch Your Step: Optimal Retrieval for Continual Learning at Scale
Apr 16, 2024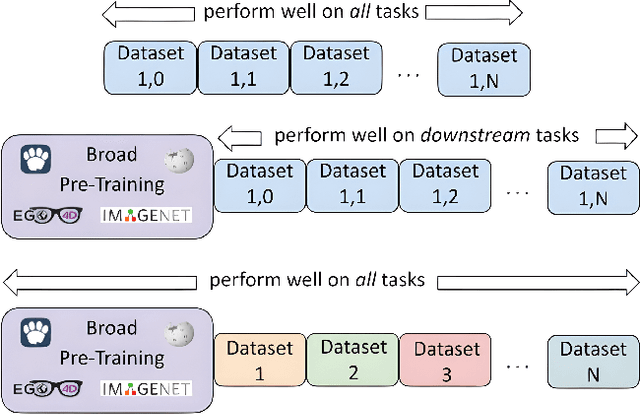
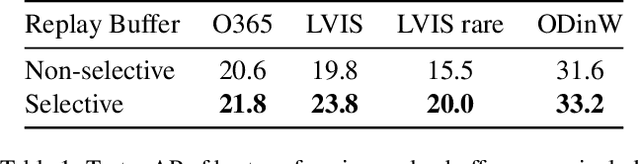
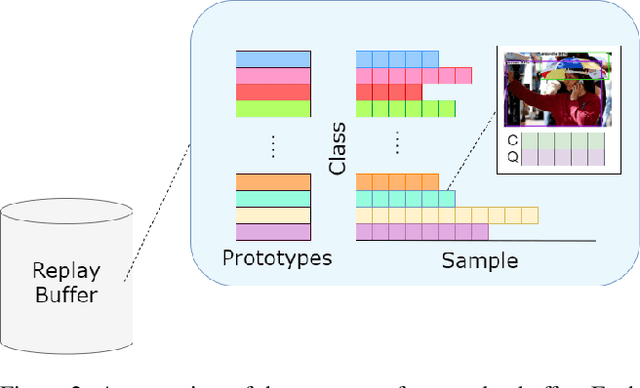
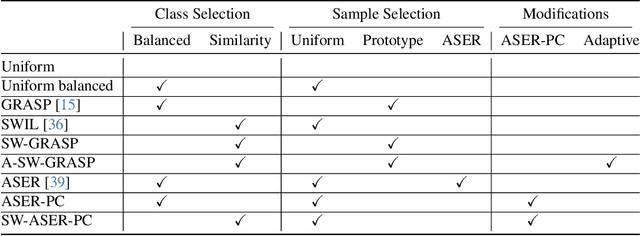
One of the most widely used approaches in continual learning is referred to as replay. Replay methods support interleaved learning by storing past experiences in a replay buffer. Although there are methods for selectively constructing the buffer and reprocessing its contents, there is limited exploration of the problem of selectively retrieving samples from the buffer. Current solutions have been tested in limited settings and, more importantly, in isolation. Existing work has also not explored the impact of duplicate replays on performance. In this work, we propose a framework for evaluating selective retrieval strategies, categorized by simple, independent class- and sample-selective primitives. We evaluated several combinations of existing strategies for selective retrieval and present their performances. Furthermore, we propose a set of strategies to prevent duplicate replays and explore whether new samples with low loss values can be learned without replay. In an effort to match our problem setting to a realistic continual learning pipeline, we restrict our experiments to a setting involving a large, pre-trained, open vocabulary object detection model, which is fully fine-tuned on a sequence of 15 datasets.