 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat could go wrong? Discovering and describing failure modes in computer vision
Paper and Code
Aug 08, 2024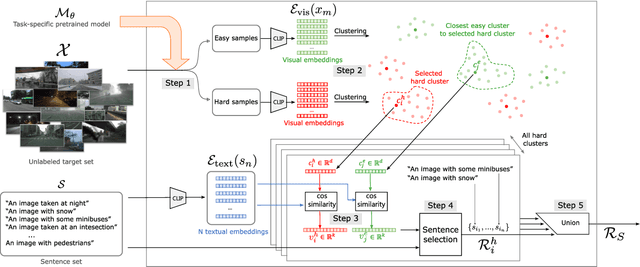
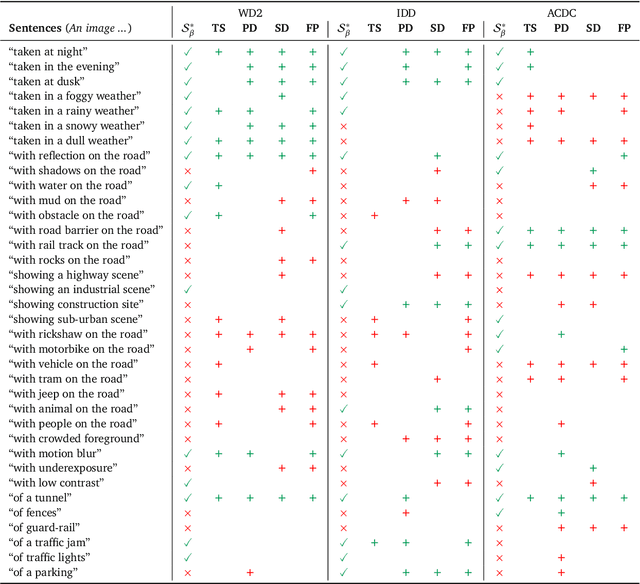
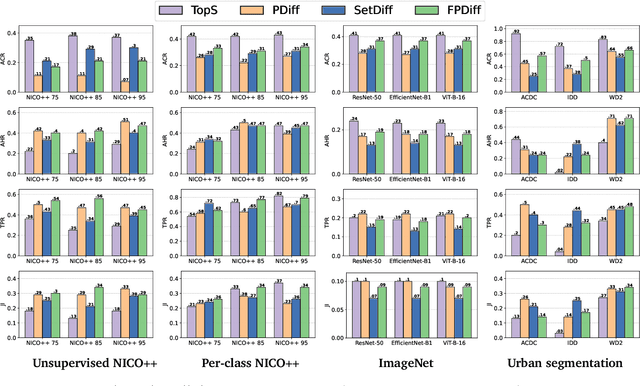

Deep learning models are effective, yet brittle. Even carefully trained, their behavior tends to be hard to predict when confronted with out-of-distribution samples. In this work, our goal is to propose a simple yet effective solution to predict and describe via natural language potential failure modes of computer vision models. Given a pretrained model and a set of samples, our aim is to find sentences that accurately describe the visual conditions in which the model underperforms. In order to study this important topic and foster future research on it, we formalize the problem of Language-Based Error Explainability (LBEE) and propose a set of metrics to evaluate and compare different methods for this task. We propose solutions that operate in a joint vision-and-language embedding space, and can characterize through language descriptions model failures caused, e.g., by objects unseen during training or adverse visual conditions. We experiment with different tasks, such as classification under the presence of dataset bias and semantic segmentation in unseen environments, and show that the proposed methodology isolates nontrivial sentences associated with specific error causes. We hope our work will help practitioners better understand the behavior of models, increasing their overall safety and interpretability.