 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Game-Theoretic Spatio-Temporal Reinforcement Learning Framework for Collaborative Public Resource Allocation
Oct 30, 2025Public resource allocation involves the efficient distribution of resources, including urban infrastructure, energy, and transportation, to effectively meet societal demands. However, existing methods focus on optimizing the movement of individual resources independently, without considering their capacity constraints. To address this limitation, we propose a novel and more practical problem: Collaborative Public Resource Allocation (CPRA), which explicitly incorporates capacity constraints and spatio-temporal dynamics in real-world scenarios. We propose a new framework called Game-Theoretic Spatio-Temporal Reinforcement Learning (GSTRL) for solving CPRA. Our contributions are twofold: 1) We formulate the CPRA problem as a potential game and demonstrate that there is no gap between the potential function and the optimal target, laying a solid theoretical foundation for approximating the Nash equilibrium of this NP-hard problem; and 2) Our designed GSTRL framework effectively captures the spatio-temporal dynamics of the overall system. We evaluate GSTRL on two real-world datasets, where experiments show its superior performance. Our source codes are available in the supplementary materials.
DP-LET: An Efficient Spatio-Temporal Network Traffic Prediction Framework
Apr 04, 2025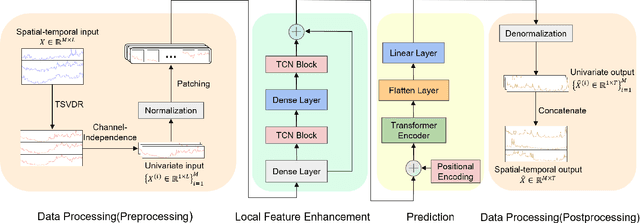
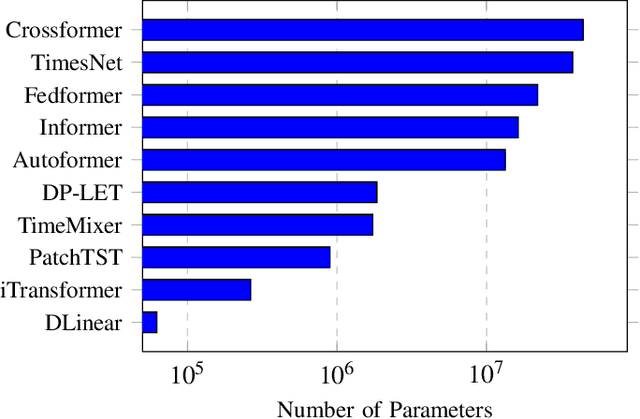


Accurately predicting spatio-temporal network traffic is essential for dynamically managing computing resources in modern communication systems and minimizing energy consumption. Although spatio-temporal traffic prediction has received extensive research attention, further improvements in prediction accuracy and computational efficiency remain necessary. In particular, existing decomposition-based methods or hybrid architectures often incur heavy overhead when capturing local and global feature correlations, necessitating novel approaches that optimize accuracy and complexity. In this paper, we propose an efficient spatio-temporal network traffic prediction framework, DP-LET, which consists of a data processing module, a local feature enhancement module, and a Transformer-based prediction module. The data processing module is designed for high-efficiency denoising of network data and spatial decoupling. In contrast, the local feature enhancement module leverages multiple Temporal Convolutional Networks (TCNs) to capture fine-grained local features. Meanwhile, the prediction module utilizes a Transformer encoder to model long-term dependencies and assess feature relevance. A case study on real-world cellular traffic prediction demonstrates the practicality of DP-LET, which maintains low computational complexity while achieving state-of-the-art performance, significantly reducing MSE by 31.8% and MAE by 23.1% compared to baseline models.
Temporal Graph Representation Learning with Adaptive Augmentation Contrastive
Nov 07, 2023Temporal graph representation learning aims to generate low-dimensional dynamic node embeddings to capture temporal information as well as structural and property information. Current representation learning methods for temporal networks often focus on capturing fine-grained information, which may lead to the model capturing random noise instead of essential semantic information. While graph contrastive learning has shown promise in dealing with noise, it only applies to static graphs or snapshots and may not be suitable for handling time-dependent noise. To alleviate the above challenge, we propose a novel Temporal Graph representation learning with Adaptive augmentation Contrastive (TGAC) model. The adaptive augmentation on the temporal graph is made by combining prior knowledge with temporal information, and the contrastive objective function is constructed by defining the augmented inter-view contrast and intra-view contrast. To complement TGAC, we propose three adaptive augmentation strategies that modify topological features to reduce noise from the network. Our extensive experiments on various real networks demonstrate that the proposed model outperforms other temporal graph representation learning methods.
LDRNet: Enabling Real-time Document Localization on Mobile Devices
Jun 05, 2022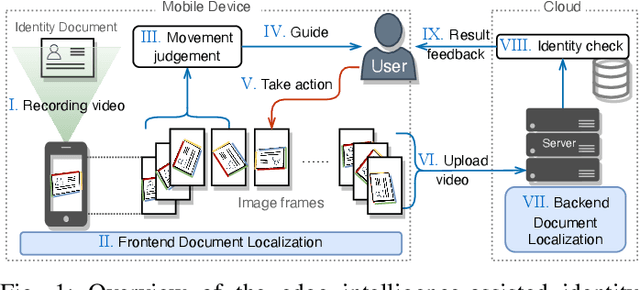
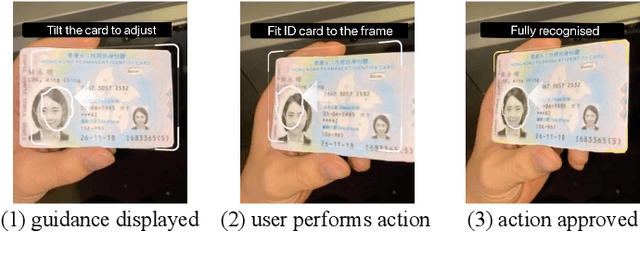
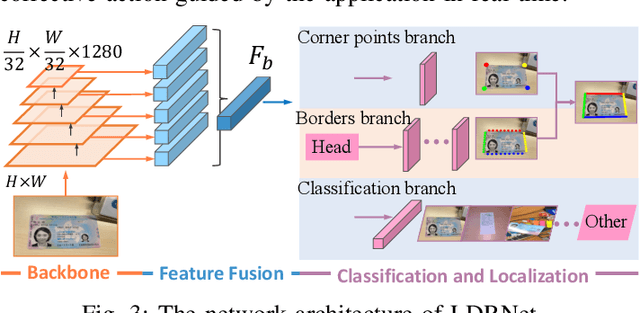

While Identity Document Verification (IDV) technology on mobile devices becomes ubiquitous in modern business operations, the risk of identity theft and fraud is increasing. The identity document holder is normally required to participate in an online video interview to circumvent impostors. However, the current IDV process depends on an additional human workforce to support online step-by-step guidance which is inefficient and expensive. The performance of existing AI-based approaches cannot meet the real-time and lightweight demands of mobile devices. In this paper, we address those challenges by designing an edge intelligence-assisted approach for real-time IDV. Aiming at improving the responsiveness of the IDV process, we propose a new document localization model for mobile devices, LDRNet, to Localize the identity Document in Real-time. On the basis of a lightweight backbone network, we build three prediction branches for LDRNet, the corner points prediction, the line borders prediction and the document classification. We design novel supplementary targets, the equal-division points, and use a new loss function named Line Loss, to improve the speed and accuracy of our approach. In addition to the IDV process, LDRNet is an efficient and reliable document localization alternative for all kinds of mobile applications. As a matter of proof, we compare the performance of LDRNet with other popular approaches on localizing general document datasets. The experimental results show that LDRNet runs at a speed up to 790 FPS which is 47x faster, while still achieving comparable Jaccard Index(JI) in single-model and single-scale tests.
Spatio-Temporal Representation with Deep Neural Recurrent Network in MIMO CSI Feedback
Aug 22, 2019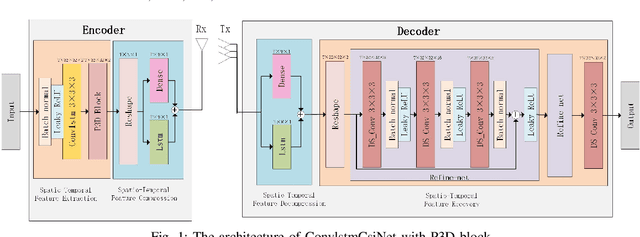
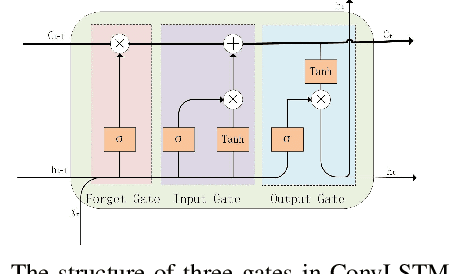
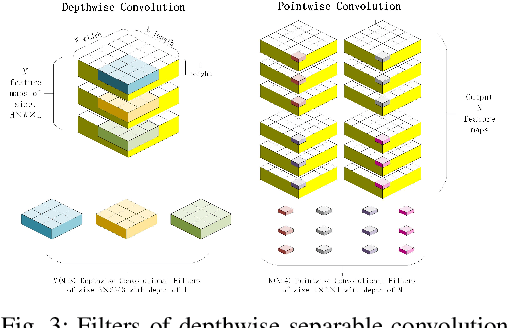
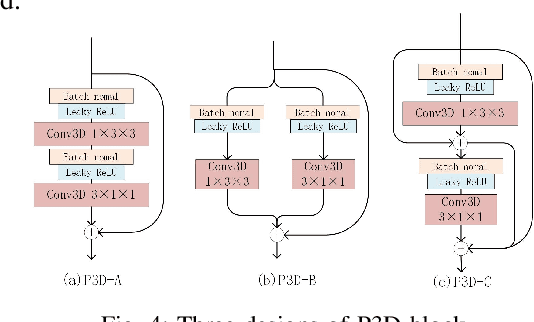
In multiple-input multiple-output (MIMO) systems, it is crucial of utilizing the available channel state information (CSI) at the transmitter for precoding to improve the performance of frequency division duplex (FDD) networks. One of the mainchallenges is to compress a large amount of CSI in CSI feedback transmission in massive MIMO systems. In this paper, we propose a deep learning (DL)-based approach that uses a deep recurrent neural network (RNN) to learn temporal correlation and adopts depthwise separable convolution to shrink the model. The feature extraction module is also elaborately devised by studyingdecoupled spatio-temporal feature representations in different structures. Experimental results demonstrate that the proposed approach outperforms existing DL-based methods in terms of recovery quality and accuracy, which can also achieve remarkable robustness at low compression ratio (CR).
Scalable Angular Discriminative Deep Metric Learning for Face Recognition
May 01, 2018
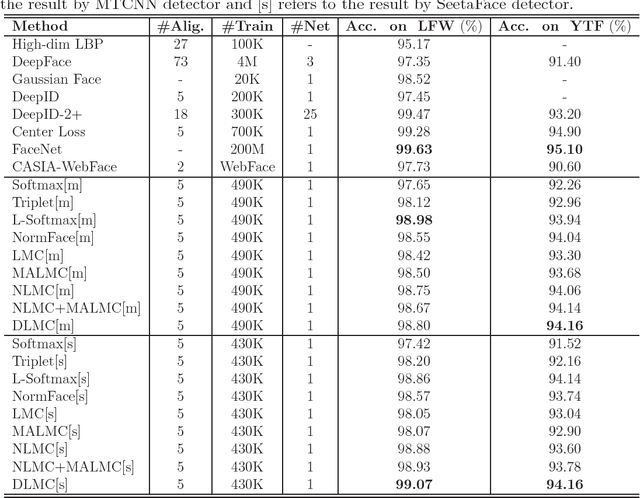
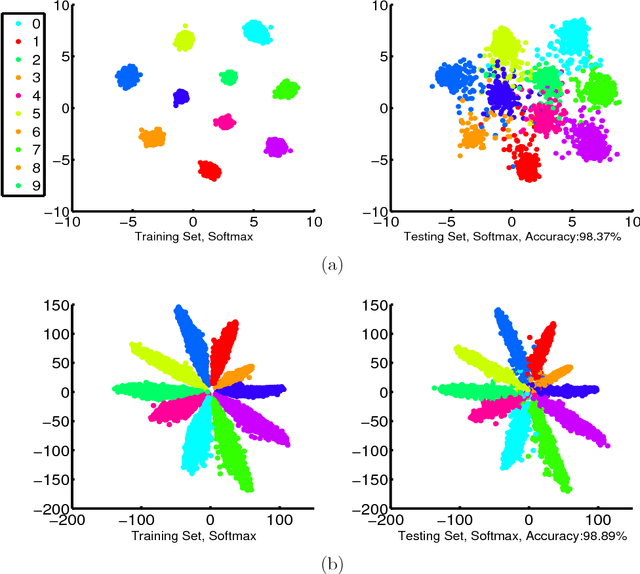

With the development of deep learning, Deep Metric Learning (DML) has achieved great improvements in face recognition. Specifically, the widely used softmax loss in the training process often bring large intra-class variations, and feature normalization is only exploited in the testing process to compute the pair similarities. To bridge the gap, we impose the intra-class cosine similarity between the features and weight vectors in softmax loss larger than a margin in the training step, and extend it from four aspects. First, we explore the effect of a hard sample mining strategy. To alleviate the human labor of adjusting the margin hyper-parameter, a self-adaptive margin updating strategy is proposed. Then, a normalized version is given to take full advantage of the cosine similarity constraint. Furthermore, we enhance the former constraint to force the intra-class cosine similarity larger than the mean inter-class cosine similarity with a margin in the exponential feature projection space. Extensive experiments on Labeled Face in the Wild (LFW), Youtube Faces (YTF) and IARPA Janus Benchmark A (IJB-A) datasets demonstrate that the proposed methods outperform the mainstream DML methods and approach the state-of-the-art performance.
Exponential Discriminative Metric Embedding in Deep Learning
Mar 07, 2018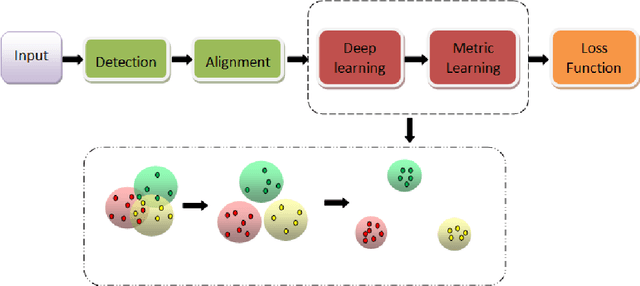
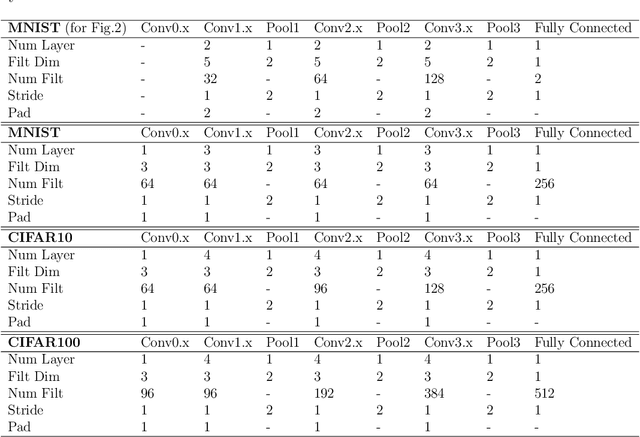
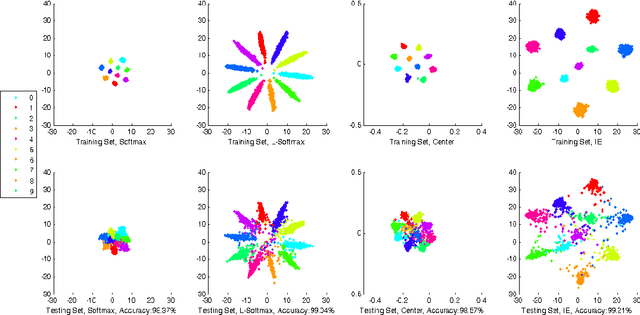

With the remarkable success achieved by the Convolutional Neural Networks (CNNs) in object recognition recently, deep learning is being widely used in the computer vision community. Deep Metric Learning (DML), integrating deep learning with conventional metric learning, has set new records in many fields, especially in classification task. In this paper, we propose a replicable DML method, called Include and Exclude (IE) loss, to force the distance between a sample and its designated class center away from the mean distance of this sample to other class centers with a large margin in the exponential feature projection space. With the supervision of IE loss, we can train CNNs to enhance the intra-class compactness and inter-class separability, leading to great improvements on several public datasets ranging from object recognition to face verification. We conduct a comparative study of our algorithm with several typical DML methods on three kinds of networks with different capacity. Extensive experiments on three object recognition datasets and two face recognition datasets demonstrate that IE loss is always superior to other mainstream DML methods and approach the state-of-the-art results.