 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHateCheckHIn: Evaluating Hindi Hate Speech Detection Models
Paper and Code
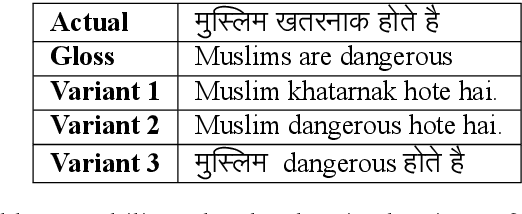
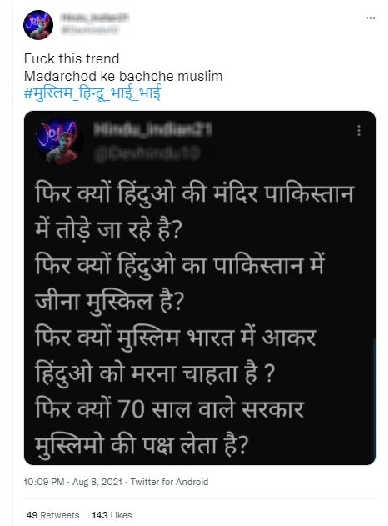

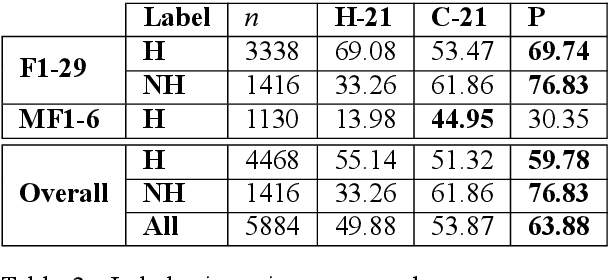
Due to the sheer volume of online hate, the AI and NLP communities have started building models to detect such hateful content. Recently, multilingual hate is a major emerging challenge for automated detection where code-mixing or more than one language have been used for conversation in social media. Typically, hate speech detection models are evaluated by measuring their performance on the held-out test data using metrics such as accuracy and F1-score. While these metrics are useful, it becomes difficult to identify using them where the model is failing, and how to resolve it. To enable more targeted diagnostic insights of such multilingual hate speech models, we introduce a set of functionalities for the purpose of evaluation. We have been inspired to design this kind of functionalities based on real-world conversation on social media. Considering Hindi as a base language, we craft test cases for each functionality. We name our evaluation dataset HateCheckHIn. To illustrate the utility of these functionalities , we test state-of-the-art transformer based m-BERT model and the Perspective API.