 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Multi-Session Personalized Conversation: A Large-Scale Dataset and Hierarchical Tree Framework for Implicit Reasoning
Mar 10, 2025There has been a surge in the use of large language models (LLM) conversational agents to generate responses based on long-term history from multiple sessions. However, existing long-term open-domain dialogue datasets lack complex, real-world personalization and fail to capture implicit reasoning-where relevant information is embedded in subtle, syntactic, or semantically distant connections rather than explicit statements. In such cases, traditional retrieval methods fail to capture relevant context, and long-context modeling also becomes inefficient due to numerous complicated persona-related details. To address this gap, we introduce ImplexConv, a large-scale long-term dataset with 2,500 examples, each containing approximately 100 conversation sessions, designed to study implicit reasoning in personalized dialogues. Additionally, we propose TaciTree, a novel hierarchical tree framework that structures conversation history into multiple levels of summarization. Instead of brute-force searching all data, TaciTree enables an efficient, level-based retrieval process where models refine their search by progressively selecting relevant details. Our experiments demonstrate that TaciTree significantly improves the ability of LLMs to reason over long-term conversations with implicit contextual dependencies.
Decoding Demographic un-fairness from Indian Names
Sep 07, 2022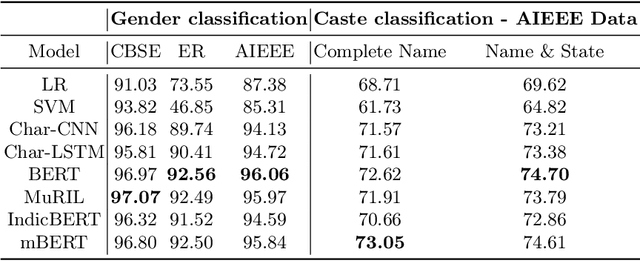
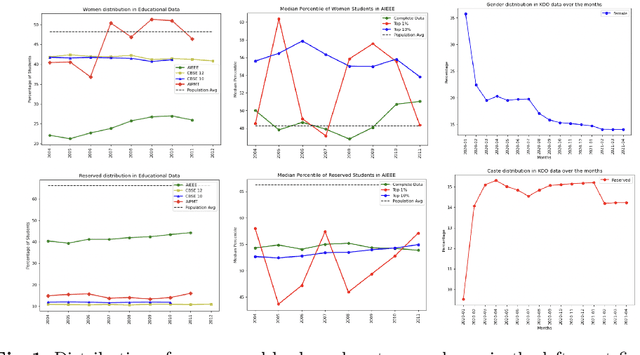
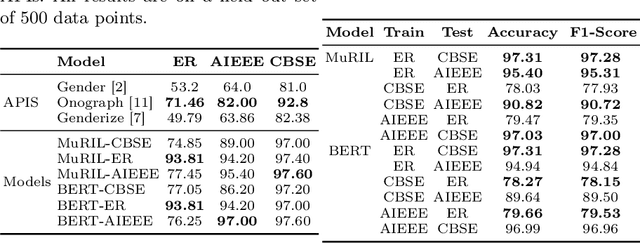
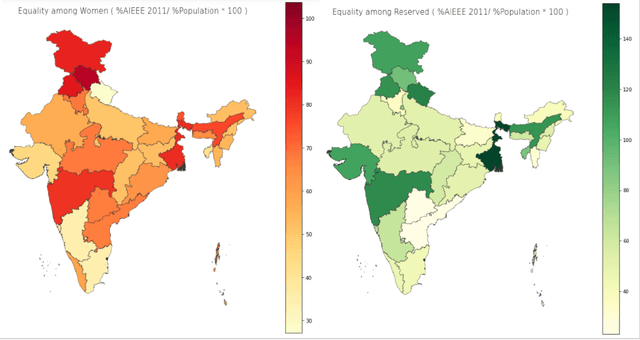
Demographic classification is essential in fairness assessment in recommender systems or in measuring unintended bias in online networks and voting systems. Important fields like education and politics, which often lay a foundation for the future of equality in society, need scrutiny to design policies that can better foster equality in resource distribution constrained by the unbalanced demographic distribution of people in the country. We collect three publicly available datasets to train state-of-the-art classifiers in the domain of gender and caste classification. We train the models in the Indian context, where the same name can have different styling conventions (Jolly Abraham/Kumar Abhishikta in one state may be written as Abraham Jolly/Abishikta Kumar in the other). Finally, we also perform cross-testing (training and testing on different datasets) to understand the efficacy of the above models. We also perform an error analysis of the prediction models. Finally, we attempt to assess the bias in the existing Indian system as case studies and find some intriguing patterns manifesting in the complex demographic layout of the sub-continent across the dimensions of gender and caste.
* Accepted to SocInfo'22; code hosted at https://github.com/vahini01/IndianDemographics