 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Multi-Session Personalized Conversation: A Large-Scale Dataset and Hierarchical Tree Framework for Implicit Reasoning
Mar 10, 2025There has been a surge in the use of large language models (LLM) conversational agents to generate responses based on long-term history from multiple sessions. However, existing long-term open-domain dialogue datasets lack complex, real-world personalization and fail to capture implicit reasoning-where relevant information is embedded in subtle, syntactic, or semantically distant connections rather than explicit statements. In such cases, traditional retrieval methods fail to capture relevant context, and long-context modeling also becomes inefficient due to numerous complicated persona-related details. To address this gap, we introduce ImplexConv, a large-scale long-term dataset with 2,500 examples, each containing approximately 100 conversation sessions, designed to study implicit reasoning in personalized dialogues. Additionally, we propose TaciTree, a novel hierarchical tree framework that structures conversation history into multiple levels of summarization. Instead of brute-force searching all data, TaciTree enables an efficient, level-based retrieval process where models refine their search by progressively selecting relevant details. Our experiments demonstrate that TaciTree significantly improves the ability of LLMs to reason over long-term conversations with implicit contextual dependencies.
Open-world Multi-label Text Classification with Extremely Weak Supervision
Jul 08, 2024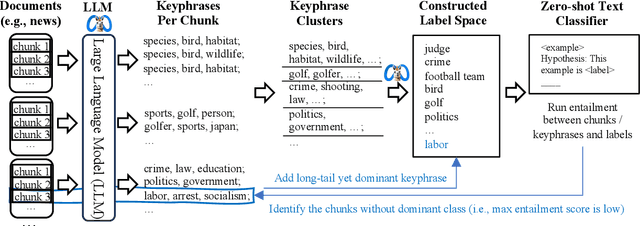
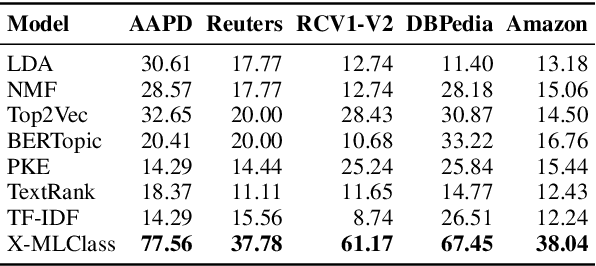
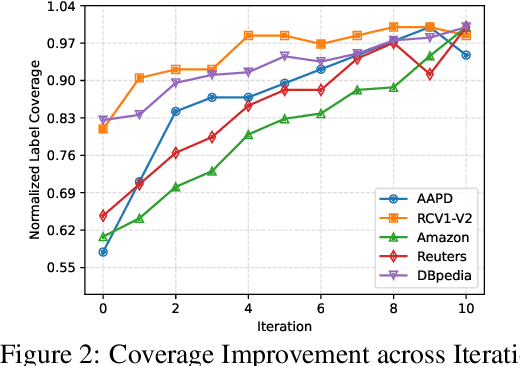
We study open-world multi-label text classification under extremely weak supervision (XWS), where the user only provides a brief description for classification objectives without any labels or ground-truth label space. Similar single-label XWS settings have been explored recently, however, these methods cannot be easily adapted for multi-label. We observe that (1) most documents have a dominant class covering the majority of content and (2) long-tail labels would appear in some documents as a dominant class. Therefore, we first utilize the user description to prompt a large language model (LLM) for dominant keyphrases of a subset of raw documents, and then construct a (initial) label space via clustering. We further apply a zero-shot multi-label classifier to locate the documents with small top predicted scores, so we can revisit their dominant keyphrases for more long-tail labels. We iterate this process to discover a comprehensive label space and construct a multi-label classifier as a novel method, X-MLClass. X-MLClass exhibits a remarkable increase in ground-truth label space coverage on various datasets, for example, a 40% improvement on the AAPD dataset over topic modeling and keyword extraction methods. Moreover, X-MLClass achieves the best end-to-end multi-label classification accuracy.