 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive AI with External Knowledge Infusion for Stocks
Apr 14, 2025Fluctuations in stock prices are influenced by a complex interplay of factors that go beyond mere historical data. These factors, themselves influenced by external forces, encompass inter-stock dynamics, broader economic factors, various government policy decisions, outbreaks of wars, etc. Furthermore, all of these factors are dynamic and exhibit changes over time. In this paper, for the first time, we tackle the forecasting problem under external influence by proposing learning mechanisms that not only learn from historical trends but also incorporate external knowledge from temporal knowledge graphs. Since there are no such datasets or temporal knowledge graphs available, we study this problem with stock market data, and we construct comprehensive temporal knowledge graph datasets. In our proposed approach, we model relations on external temporal knowledge graphs as events of a Hawkes process on graphs. With extensive experiments, we show that learned dynamic representations effectively rank stocks based on returns across multiple holding periods, outperforming related baselines on relevant metrics.
Active Reinforcement Learning Strategies for Offline Policy Improvement
Dec 17, 2024



Learning agents that excel at sequential decision-making tasks must continuously resolve the problem of exploration and exploitation for optimal learning. However, such interactions with the environment online might be prohibitively expensive and may involve some constraints, such as a limited budget for agent-environment interactions and restricted exploration in certain regions of the state space. Examples include selecting candidates for medical trials and training agents in complex navigation environments. This problem necessitates the study of active reinforcement learning strategies that collect minimal additional experience trajectories by reusing existing offline data previously collected by some unknown behavior policy. In this work, we propose a representation-aware uncertainty-based active trajectory collection method that intelligently decides interaction strategies that consider the distribution of the existing offline data. With extensive experimentation, we demonstrate that our proposed method reduces additional online interaction with the environment by up to 75% over competitive baselines across various continuous control environments.
Markov Decision Process with an External Temporal Process
May 25, 2023

Most reinforcement learning algorithms treat the context under which they operate as a stationary, isolated and undisturbed environment. However, in the real world, the environment is constantly changing due to a variety of external influences. To address this problem, we study Markov Decision Processes (MDP) under the influence of an external temporal process. We formalize this notion and discuss conditions under which the problem becomes tractable with suitable solutions. We propose a policy iteration algorithm to solve this problem and theoretically analyze its performance.
Stay Alive with Many Options: A Reinforcement Learning Approach for Autonomous Navigation
Jan 30, 2021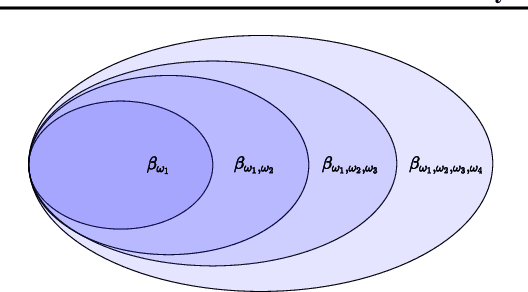


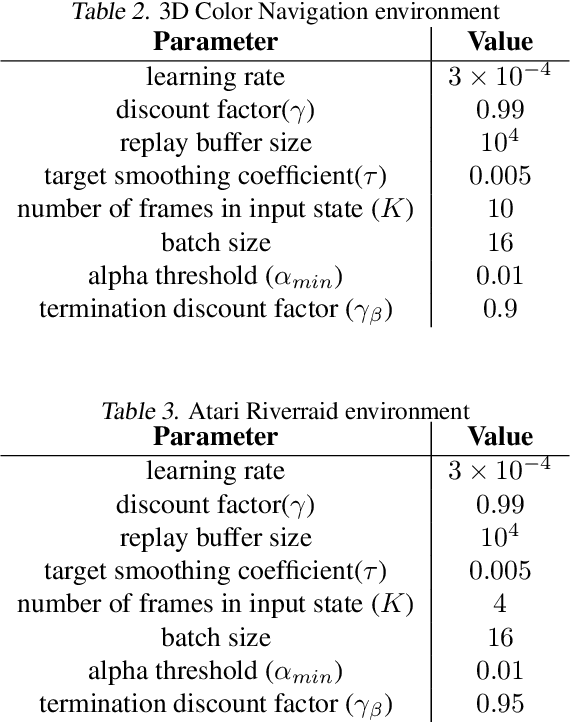
Hierarchical reinforcement learning approaches learn policies based on hierarchical decision structures. However, training such methods in practice may lead to poor generalization, with either sub-policies executing actions for too few time steps or devolving into a single policy altogether. In our work, we introduce an alternative approach to sequentially learn such skills without using an overarching hierarchical policy, in the context of environments in which an objective of the agent is to prolong the episode for as long as possible, or in other words `stay alive'. We demonstrate the utility of our approach in a simulated 3D navigation environment which we have built. We show that our method outperforms prior methods such as Soft Actor Critic and Soft Option Critic on our environment, as well as the Atari River Raid environment.