 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStay Alive with Many Options: A Reinforcement Learning Approach for Autonomous Navigation
Jan 30, 2021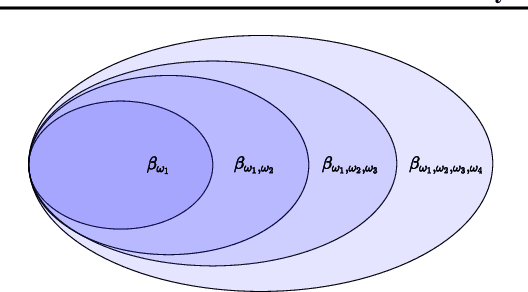


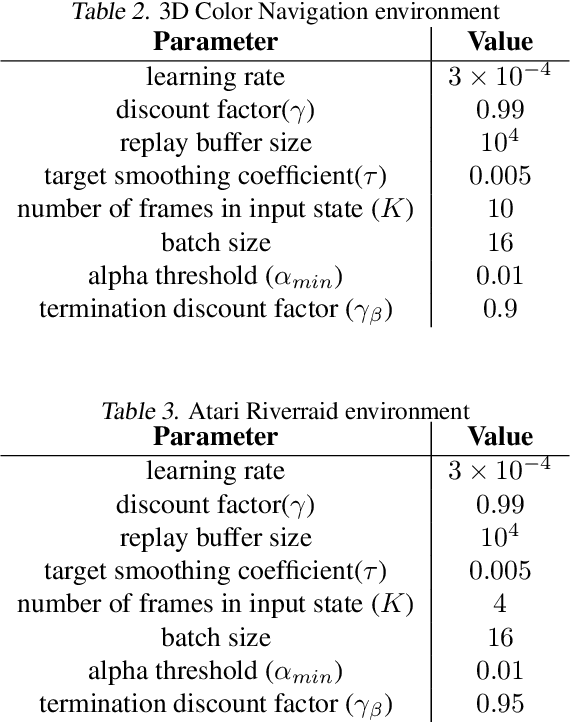
Hierarchical reinforcement learning approaches learn policies based on hierarchical decision structures. However, training such methods in practice may lead to poor generalization, with either sub-policies executing actions for too few time steps or devolving into a single policy altogether. In our work, we introduce an alternative approach to sequentially learn such skills without using an overarching hierarchical policy, in the context of environments in which an objective of the agent is to prolong the episode for as long as possible, or in other words `stay alive'. We demonstrate the utility of our approach in a simulated 3D navigation environment which we have built. We show that our method outperforms prior methods such as Soft Actor Critic and Soft Option Critic on our environment, as well as the Atari River Raid environment.