 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive$^2$ Learning: Actively reducing redundancies in Active Learning methods for Sequence Tagging and Machine Translation
Paper and Code
Apr 03, 2021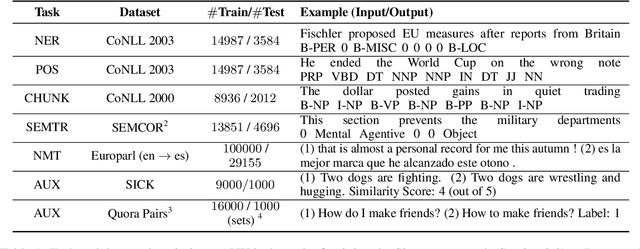

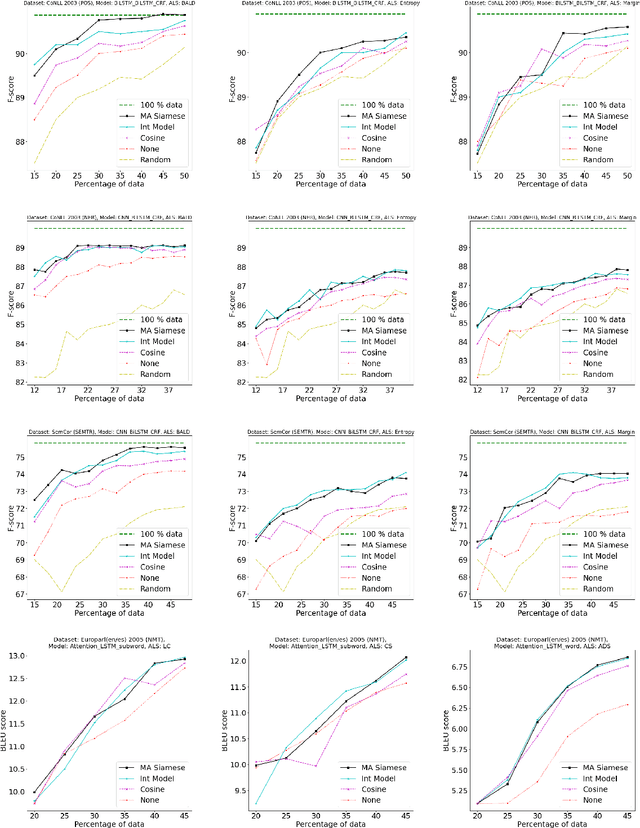
While deep learning is a powerful tool for natural language processing (NLP) problems, successful solutions to these problems rely heavily on large amounts of annotated samples. However, manually annotating data is expensive and time-consuming. Active Learning (AL) strategies reduce the need for huge volumes of labeled data by iteratively selecting a small number of examples for manual annotation based on their estimated utility in training the given model. In this paper, we argue that since AL strategies choose examples independently, they may potentially select similar examples, all of which may not contribute significantly to the learning process. Our proposed approach, Active$\mathbf{^2}$ Learning (A$\mathbf{^2}$L), actively adapts to the deep learning model being trained to eliminate further such redundant examples chosen by an AL strategy. We show that A$\mathbf{^2}$L is widely applicable by using it in conjunction with several different AL strategies and NLP tasks. We empirically demonstrate that the proposed approach is further able to reduce the data requirements of state-of-the-art AL strategies by an absolute percentage reduction of $\approx\mathbf{3-25\%}$ on multiple NLP tasks while achieving the same performance with no additional computation overhead.