 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndicMMLU-Pro: Benchmarking the Indic Large Language Models
Jan 27, 2025Known by more than 1.5 billion people in the Indian subcontinent, Indic languages present unique challenges and opportunities for natural language processing (NLP) research due to their rich cultural heritage, linguistic diversity, and complex structures. IndicMMLU-Pro is a comprehensive benchmark designed to evaluate Large Language Models (LLMs) across Indic languages, building upon the MMLU Pro (Massive Multitask Language Understanding) framework. Covering major languages such as Hindi, Bengali, Gujarati, Marathi, Kannada, Punjabi, Tamil, Telugu, and Urdu, our benchmark addresses the unique challenges and opportunities presented by the linguistic diversity of the Indian subcontinent. This benchmark encompasses a wide range of tasks in language comprehension, reasoning, and generation, meticulously crafted to capture the intricacies of Indian languages. IndicMMLU-Pro provides a standardized evaluation framework to push the research boundaries in Indic language AI, facilitating the development of more accurate, efficient, and culturally sensitive models. This paper outlines the benchmarks' design principles, task taxonomy, data collection methodology, and presents baseline results from state-of-the-art multilingual models.
Hierarchical Prompting Taxonomy: A Universal Evaluation Framework for Large Language Models
Jun 18, 2024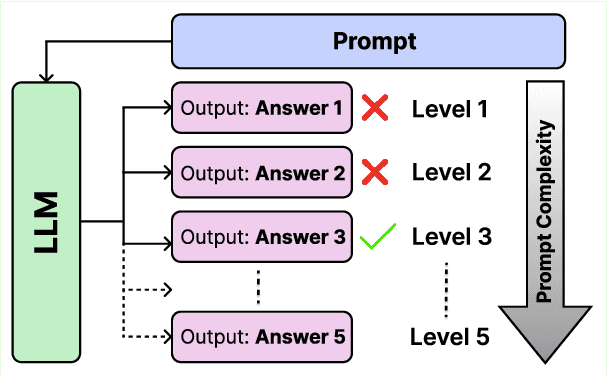
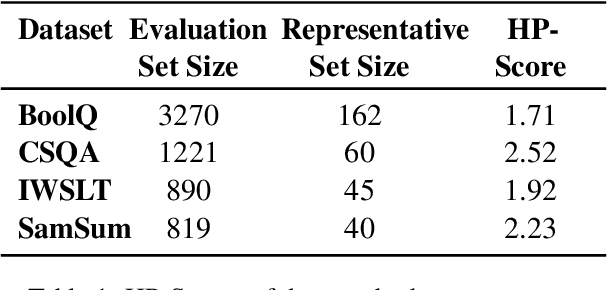
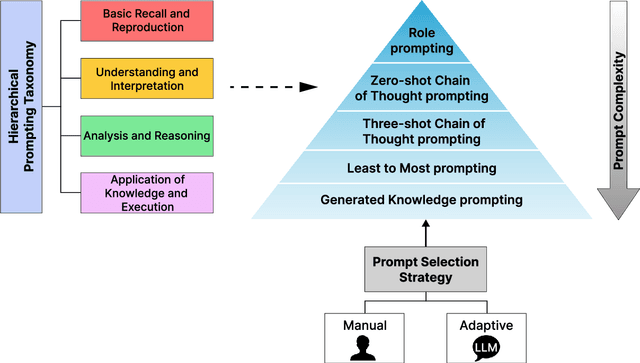

Assessing the effectiveness of large language models (LLMs) in addressing diverse tasks is essential for comprehending their strengths and weaknesses. Conventional evaluation techniques typically apply a single prompting strategy uniformly across datasets, not considering the varying degrees of task complexity. We introduce the Hierarchical Prompting Taxonomy (HPT), a taxonomy that employs a Hierarchical Prompt Framework (HPF) composed of five unique prompting strategies, arranged from the simplest to the most complex, to assess LLMs more precisely and to offer a clearer perspective. This taxonomy assigns a score, called the Hierarchical Prompting Score (HP-Score), to datasets as well as LLMs based on the rules of the taxonomy, providing a nuanced understanding of their ability to solve diverse tasks and offering a universal measure of task complexity. Additionally, we introduce the Adaptive Hierarchical Prompt framework, which automates the selection of appropriate prompting strategies for each task. This study compares manual and adaptive hierarchical prompt frameworks using four instruction-tuned LLMs, namely Llama 3 8B, Phi 3 3.8B, Mistral 7B, and Gemma 7B, across four datasets: BoolQ, CommonSenseQA (CSQA), IWSLT-2017 en-fr (IWSLT), and SamSum. Experiments demonstrate the effectiveness of HPT, providing a reliable way to compare different tasks and LLM capabilities. This paper leads to the development of a universal evaluation metric that can be used to evaluate both the complexity of the datasets and the capabilities of LLMs. The implementation of both manual HPF and adaptive HPF is publicly available.
Decoding the Diversity: A Review of the Indic AI Research Landscape
Jun 13, 2024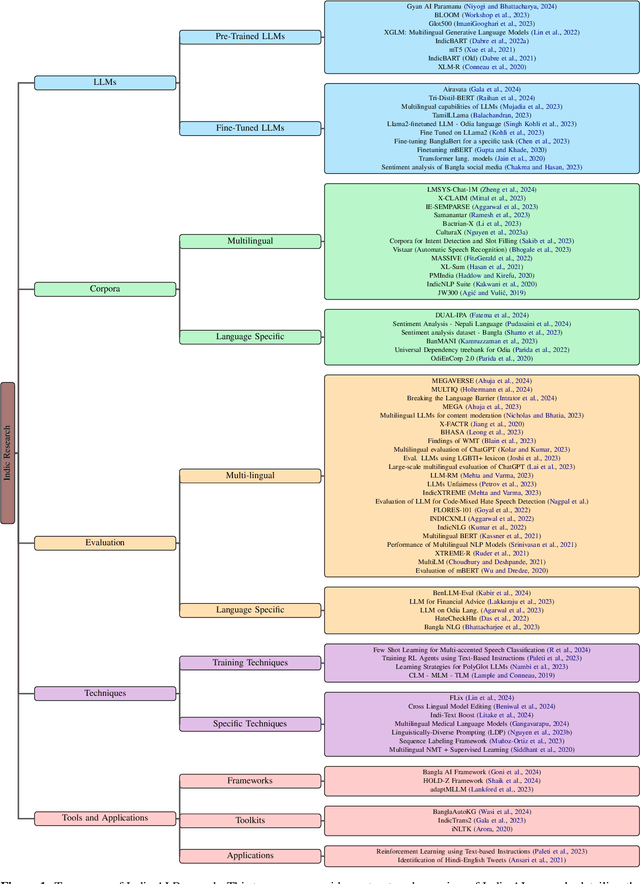
This review paper provides a comprehensive overview of large language model (LLM) research directions within Indic languages. Indic languages are those spoken in the Indian subcontinent, including India, Pakistan, Bangladesh, Sri Lanka, Nepal, and Bhutan, among others. These languages have a rich cultural and linguistic heritage and are spoken by over 1.5 billion people worldwide. With the tremendous market potential and growing demand for natural language processing (NLP) based applications in diverse languages, generative applications for Indic languages pose unique challenges and opportunities for research. Our paper deep dives into the recent advancements in Indic generative modeling, contributing with a taxonomy of research directions, tabulating 84 recent publications. Research directions surveyed in this paper include LLM development, fine-tuning existing LLMs, development of corpora, benchmarking and evaluation, as well as publications around specific techniques, tools, and applications. We found that researchers across the publications emphasize the challenges associated with limited data availability, lack of standardization, and the peculiar linguistic complexities of Indic languages. This work aims to serve as a valuable resource for researchers and practitioners working in the field of NLP, particularly those focused on Indic languages, and contributes to the development of more accurate and efficient LLM applications for these languages.