 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding the Diversity: A Review of the Indic AI Research Landscape
Paper and Code
Jun 13, 2024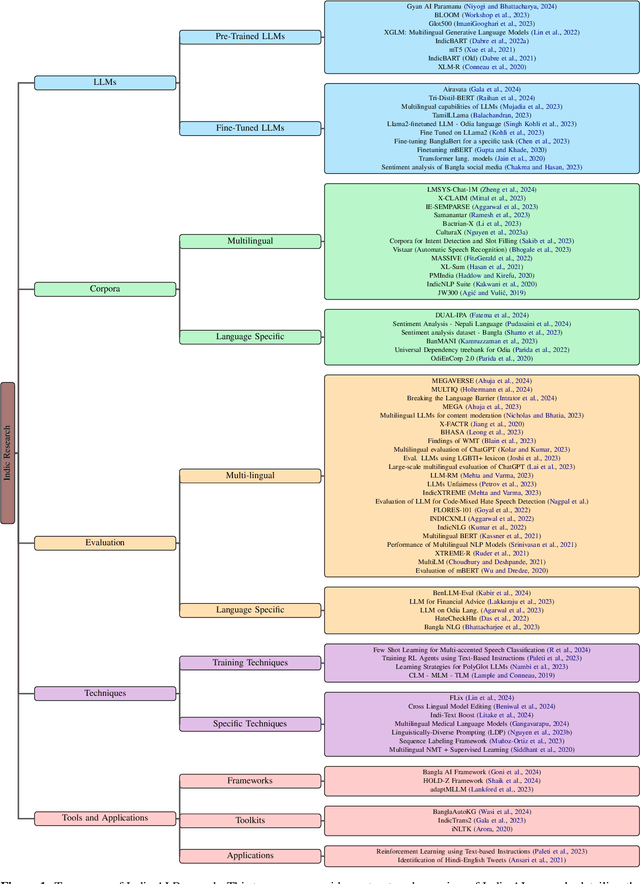
This review paper provides a comprehensive overview of large language model (LLM) research directions within Indic languages. Indic languages are those spoken in the Indian subcontinent, including India, Pakistan, Bangladesh, Sri Lanka, Nepal, and Bhutan, among others. These languages have a rich cultural and linguistic heritage and are spoken by over 1.5 billion people worldwide. With the tremendous market potential and growing demand for natural language processing (NLP) based applications in diverse languages, generative applications for Indic languages pose unique challenges and opportunities for research. Our paper deep dives into the recent advancements in Indic generative modeling, contributing with a taxonomy of research directions, tabulating 84 recent publications. Research directions surveyed in this paper include LLM development, fine-tuning existing LLMs, development of corpora, benchmarking and evaluation, as well as publications around specific techniques, tools, and applications. We found that researchers across the publications emphasize the challenges associated with limited data availability, lack of standardization, and the peculiar linguistic complexities of Indic languages. This work aims to serve as a valuable resource for researchers and practitioners working in the field of NLP, particularly those focused on Indic languages, and contributes to the development of more accurate and efficient LLM applications for these languages.