 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpComm: A Reinforcement Learning Framework for Adaptive Buffer Control in Warehouse Volume Forecasting
Dec 17, 2025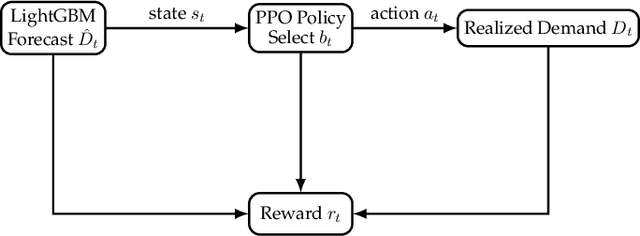
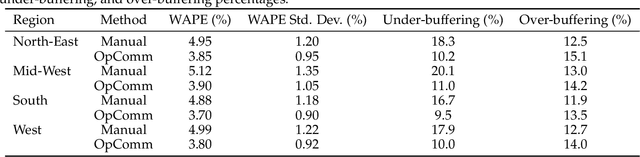
Accurate forecasting of package volumes at delivery stations is critical for last-mile logistics, where errors lead to inefficient resource allocation, higher costs, and delivery delays. We propose OpComm, a forecasting and decision-support framework that combines supervised learning with reinforcement learning-based buffer control and a generative AI-driven communication module. A LightGBM regression model generates station-level demand forecasts, which serve as context for a Proximal Policy Optimization (PPO) agent that selects buffer levels from a discrete action set. The reward function penalizes under-buffering more heavily than over-buffering, reflecting real-world trade-offs between unmet demand risks and resource inefficiency. Station outcomes are fed back through a Monte Carlo update mechanism, enabling continual policy adaptation. To enhance interpretability, a generative AI layer produces executive-level summaries and scenario analyses grounded in SHAP-based feature attributions. Across 400+ stations, OpComm reduced Weighted Absolute Percentage Error (WAPE) by 21.65% compared to manual forecasts, while lowering under-buffering incidents and improving transparency for decision-makers. This work shows how contextual reinforcement learning, coupled with predictive modeling, can address operational forecasting challenges and bridge statistical rigor with practical decision-making in high-stakes logistics environments.
Node-Level Financial Optimization in Demand Forecasting Through Dynamic Cost Asymmetry and Feedback Mechanism
Dec 16, 2025



This work introduces a methodology to adjust forecasts based on node-specific cost function asymmetry. The proposed model generates savings by dynamically incorporating the cost asymmetry into the forecasting error probability distribution to favor the least expensive scenario. Savings are calculated and a self-regulation mechanism modulates the adjustments magnitude based on the observed savings, enabling the model to adapt to station-specific conditions and unmodeled factors such as calibration errors or shifting macroeconomic dynamics. Finally, empirical results demonstrate the model's ability to achieve \$5.1M annual savings.
Scaling Causal Mediation for Complex Systems: A Framework for Root Cause Analysis
Dec 16, 2025Modern operational systems ranging from logistics and cloud infrastructure to industrial IoT, are governed by complex, interdependent processes. Understanding how interventions propagate through such systems requires causal inference methods that go beyond direct effects to quantify mediated pathways. Traditional mediation analysis, while effective in simple settings, fails to scale to the high-dimensional directed acyclic graphs (DAGs) encountered in practice, particularly when multiple treatments and mediators interact. In this paper, we propose a scalable mediation analysis framework tailored for large causal DAGs involving multiple treatments and mediators. Our approach systematically decomposes total effects into interpretable direct and indirect components. We demonstrate its practical utility through applied case studies in fulfillment center logistics, where complex dependencies and non-controllable factors often obscure root causes.
Levers of Power in the Field of AI
Nov 05, 2025This paper examines how decision makers in academia, government, business, and civil society navigate questions of power in implementations of artificial intelligence. The study explores how individuals experience and exercise levers of power, which are presented as social mechanisms that shape institutional responses to technological change. The study reports on the responses of personalized questionnaires designed to gather insight on a decision maker's institutional purview, based on an institutional governance framework developed from the work of Neo-institutionalists. Findings present the anonymized, real responses and circumstances of respondents in the form of twelve fictional personas of high-level decision makers from North America and Europe. These personas illustrate how personal agency, organizational logics, and institutional infrastructures may intersect in the governance of AI. The decision makers' responses to the questionnaires then inform a discussion of the field-level personal power of decision makers, methods of fostering institutional stability in times of change, and methods of influencing institutional change in the field of AI. The final section of the discussion presents a table of the dynamics of the levers of power in the field of AI for change makers and five testable hypotheses for institutional and social movement researchers. In summary, this study provides insight on the means for policymakers within institutions and their counterparts in civil society to personally engage with AI governance.
Transforming Expert Knowledge into Scalable Ontology via Large Language Models
Jun 11, 2025Having a unified, coherent taxonomy is essential for effective knowledge representation in domain-specific applications as diverse terminologies need to be mapped to underlying concepts. Traditional manual approaches to taxonomy alignment rely on expert review of concept pairs, but this becomes prohibitively expensive and time-consuming at scale, while subjective interpretations often lead to expert disagreements. Existing automated methods for taxonomy alignment have shown promise but face limitations in handling nuanced semantic relationships and maintaining consistency across different domains. These approaches often struggle with context-dependent concept mappings and lack transparent reasoning processes. We propose a novel framework that combines large language models (LLMs) with expert calibration and iterative prompt optimization to automate taxonomy alignment. Our method integrates expert-labeled examples, multi-stage prompt engineering, and human validation to guide LLMs in generating both taxonomy linkages and supporting rationales. In evaluating our framework on a domain-specific mapping task of concept essentiality, we achieved an F1-score of 0.97, substantially exceeding the human benchmark of 0.68. These results demonstrate the effectiveness of our approach in scaling taxonomy alignment while maintaining high-quality mappings and preserving expert oversight for ambiguous cases.
IndicMMLU-Pro: Benchmarking the Indic Large Language Models
Jan 27, 2025Known by more than 1.5 billion people in the Indian subcontinent, Indic languages present unique challenges and opportunities for natural language processing (NLP) research due to their rich cultural heritage, linguistic diversity, and complex structures. IndicMMLU-Pro is a comprehensive benchmark designed to evaluate Large Language Models (LLMs) across Indic languages, building upon the MMLU Pro (Massive Multitask Language Understanding) framework. Covering major languages such as Hindi, Bengali, Gujarati, Marathi, Kannada, Punjabi, Tamil, Telugu, and Urdu, our benchmark addresses the unique challenges and opportunities presented by the linguistic diversity of the Indian subcontinent. This benchmark encompasses a wide range of tasks in language comprehension, reasoning, and generation, meticulously crafted to capture the intricacies of Indian languages. IndicMMLU-Pro provides a standardized evaluation framework to push the research boundaries in Indic language AI, facilitating the development of more accurate, efficient, and culturally sensitive models. This paper outlines the benchmarks' design principles, task taxonomy, data collection methodology, and presents baseline results from state-of-the-art multilingual models.
Potential and Perils of Large Language Models as Judges of Unstructured Textual Data
Jan 14, 2025
Rapid advancements in large language models have unlocked remarkable capabilities when it comes to processing and summarizing unstructured text data. This has implications for the analysis of rich, open-ended datasets, such as survey responses, where LLMs hold the promise of efficiently distilling key themes and sentiments. However, as organizations increasingly turn to these powerful AI systems to make sense of textual feedback, a critical question arises, can we trust LLMs to accurately represent the perspectives contained within these text based datasets? While LLMs excel at generating human-like summaries, there is a risk that their outputs may inadvertently diverge from the true substance of the original responses. Discrepancies between the LLM-generated outputs and the actual themes present in the data could lead to flawed decision-making, with far-reaching consequences for organizations. This research investigates the effectiveness of LLMs as judge models to evaluate the thematic alignment of summaries generated by other LLMs. We utilized an Anthropic Claude model to generate thematic summaries from open-ended survey responses, with Amazon's Titan Express, Nova Pro, and Meta's Llama serving as LLM judges. The LLM-as-judge approach was compared to human evaluations using Cohen's kappa, Spearman's rho, and Krippendorff's alpha, validating a scalable alternative to traditional human centric evaluation methods. Our findings reveal that while LLMs as judges offer a scalable solution comparable to human raters, humans may still excel at detecting subtle, context-specific nuances. This research contributes to the growing body of knowledge on AI assisted text analysis. We discuss limitations and provide recommendations for future research, emphasizing the need for careful consideration when generalizing LLM judge models across various contexts and use cases.
Reconciling Methodological Paradigms: Employing Large Language Models as Novice Qualitative Research Assistants in Talent Management Research
Aug 20, 2024



Qualitative data collection and analysis approaches, such as those employing interviews and focus groups, provide rich insights into customer attitudes, sentiment, and behavior. However, manually analyzing qualitative data requires extensive time and effort to identify relevant topics and thematic insights. This study proposes a novel approach to address this challenge by leveraging Retrieval Augmented Generation (RAG) based Large Language Models (LLMs) for analyzing interview transcripts. The novelty of this work lies in strategizing the research inquiry as one that is augmented by an LLM that serves as a novice research assistant. This research explores the mental model of LLMs to serve as novice qualitative research assistants for researchers in the talent management space. A RAG-based LLM approach is extended to enable topic modeling of semi-structured interview data, showcasing the versatility of these models beyond their traditional use in information retrieval and search. Our findings demonstrate that the LLM-augmented RAG approach can successfully extract topics of interest, with significant coverage compared to manually generated topics from the same dataset. This establishes the viability of employing LLMs as novice qualitative research assistants. Additionally, the study recommends that researchers leveraging such models lean heavily on quality criteria used in traditional qualitative research to ensure rigor and trustworthiness of their approach. Finally, the paper presents key recommendations for industry practitioners seeking to reconcile the use of LLMs with established qualitative research paradigms, providing a roadmap for the effective integration of these powerful, albeit novice, AI tools in the analysis of qualitative datasets within talent
Decoding the Diversity: A Review of the Indic AI Research Landscape
Jun 13, 2024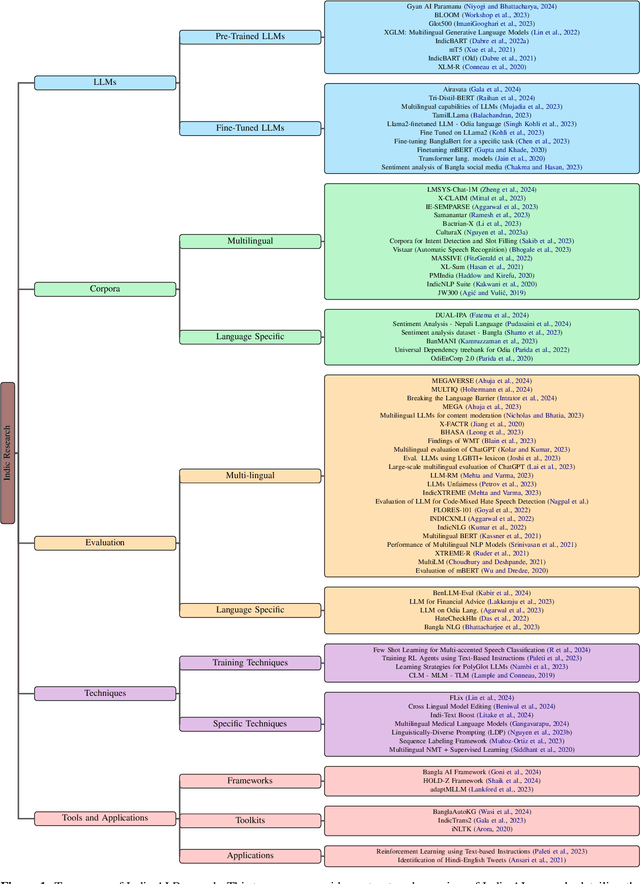
This review paper provides a comprehensive overview of large language model (LLM) research directions within Indic languages. Indic languages are those spoken in the Indian subcontinent, including India, Pakistan, Bangladesh, Sri Lanka, Nepal, and Bhutan, among others. These languages have a rich cultural and linguistic heritage and are spoken by over 1.5 billion people worldwide. With the tremendous market potential and growing demand for natural language processing (NLP) based applications in diverse languages, generative applications for Indic languages pose unique challenges and opportunities for research. Our paper deep dives into the recent advancements in Indic generative modeling, contributing with a taxonomy of research directions, tabulating 84 recent publications. Research directions surveyed in this paper include LLM development, fine-tuning existing LLMs, development of corpora, benchmarking and evaluation, as well as publications around specific techniques, tools, and applications. We found that researchers across the publications emphasize the challenges associated with limited data availability, lack of standardization, and the peculiar linguistic complexities of Indic languages. This work aims to serve as a valuable resource for researchers and practitioners working in the field of NLP, particularly those focused on Indic languages, and contributes to the development of more accurate and efficient LLM applications for these languages.
Parameter Efficient Fine Tuning: A Comprehensive Analysis Across Applications
Apr 23, 2024



The rise of deep learning has marked significant progress in fields such as computer vision, natural language processing, and medical imaging, primarily through the adaptation of pre-trained models for specific tasks. Traditional fine-tuning methods, involving adjustments to all parameters, face challenges due to high computational and memory demands. This has led to the development of Parameter Efficient Fine-Tuning (PEFT) techniques, which selectively update parameters to balance computational efficiency with performance. This review examines PEFT approaches, offering a detailed comparison of various strategies highlighting applications across different domains, including text generation, medical imaging, protein modeling, and speech synthesis. By assessing the effectiveness of PEFT methods in reducing computational load, speeding up training, and lowering memory usage, this paper contributes to making deep learning more accessible and adaptable, facilitating its wider application and encouraging innovation in model optimization. Ultimately, the paper aims to contribute towards insights into PEFT's evolving landscape, guiding researchers and practitioners in overcoming the limitations of conventional fine-tuning approaches.