 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiering as a Stochastic Submodular Optimization Problem
May 16, 2020

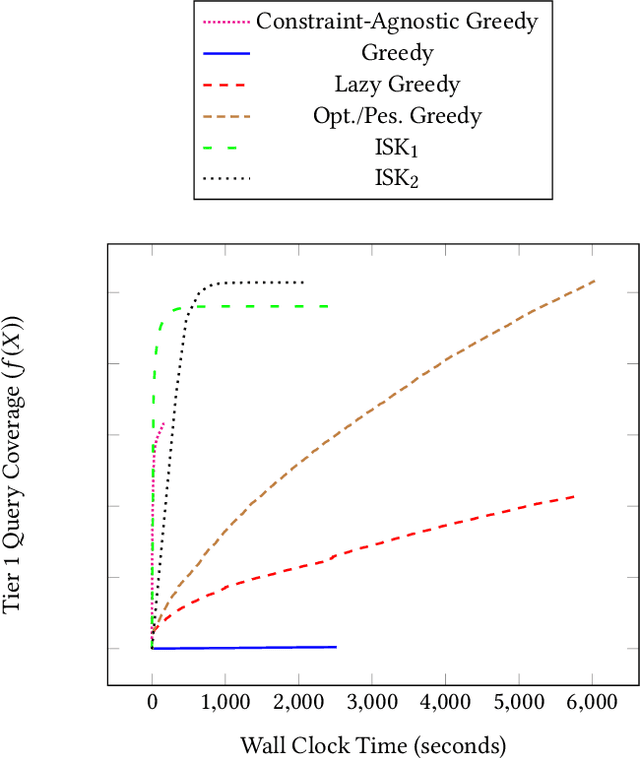
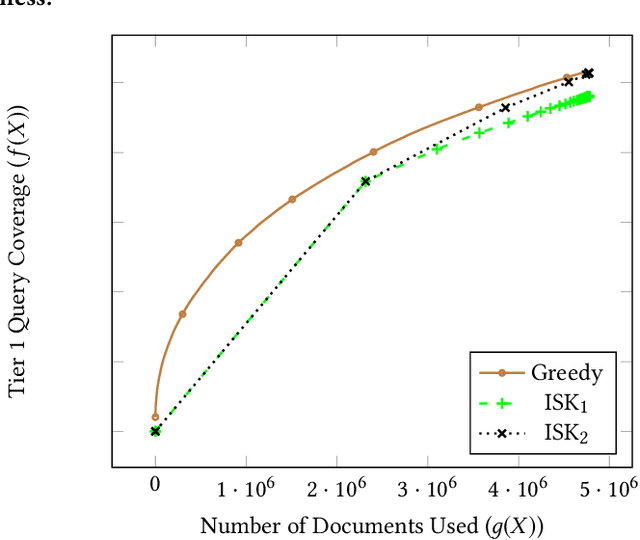
Tiering is an essential technique for building large-scale information retrieval systems. While the selection of documents for high priority tiers critically impacts the efficiency of tiering, past work focuses on optimizing it with respect to a static set of queries in the history, and generalizes poorly to the future traffic. Instead, we formulate the optimal tiering as a stochastic optimization problem, and follow the methodology of regularized empirical risk minimization to maximize the \emph{generalization performance} of the system. We also show that the optimization problem can be cast as a stochastic submodular optimization problem with a submodular knapsack constraint, and we develop efficient optimization algorithms by leveraging this connection.