 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShop-R1: Rewarding LLMs to Simulate Human Behavior in Online Shopping via Reinforcement Learning
Jul 23, 2025

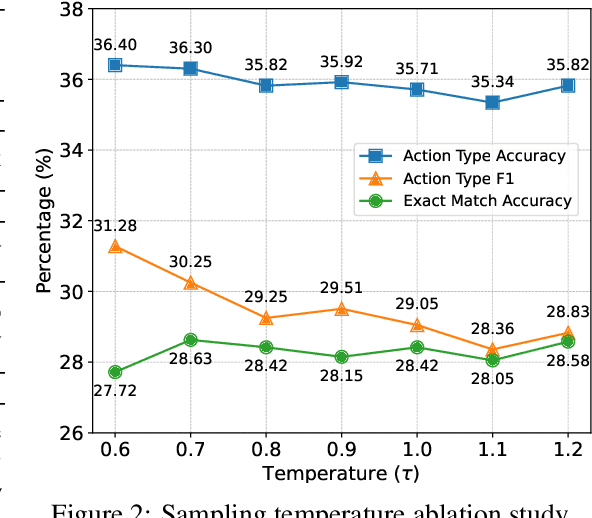

Large Language Models (LLMs) have recently demonstrated strong potential in generating 'believable human-like' behavior in web environments. Prior work has explored augmenting training data with LLM-synthesized rationales and applying supervised fine-tuning (SFT) to enhance reasoning ability, which in turn can improve downstream action prediction. However, the performance of such approaches remains inherently bounded by the reasoning capabilities of the model used to generate the rationales. In this paper, we introduce Shop-R1, a novel reinforcement learning (RL) framework aimed at enhancing the reasoning ability of LLMs for simulation of real human behavior in online shopping environments Specifically, Shop-R1 decomposes the human behavior simulation task into two stages: rationale generation and action prediction, each guided by distinct reward signals. For rationale generation, we leverage internal model signals (e.g., logit distributions) to guide the reasoning process in a self-supervised manner. For action prediction, we propose a hierarchical reward structure with difficulty-aware scaling to prevent reward hacking and enable fine-grained reward assignment. This design evaluates both high-level action types and the correctness of fine-grained sub-action details (attributes and values), rewarding outputs proportionally to their difficulty. Experimental results show that our method achieves a relative improvement of over 65% compared to the baseline.
GraphStorm: all-in-one graph machine learning framework for industry applications
Jun 10, 2024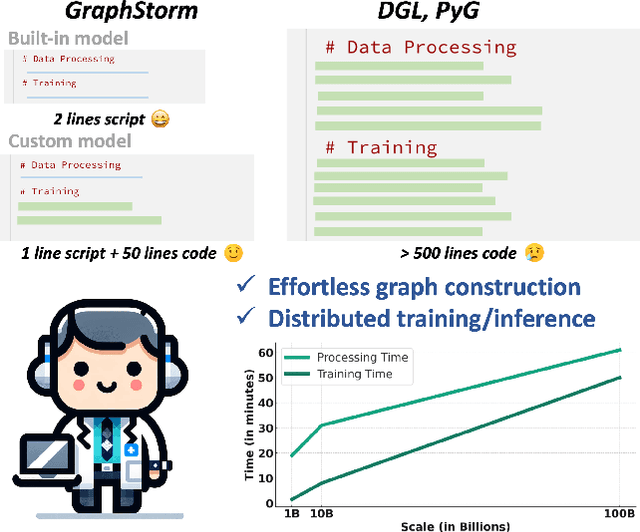

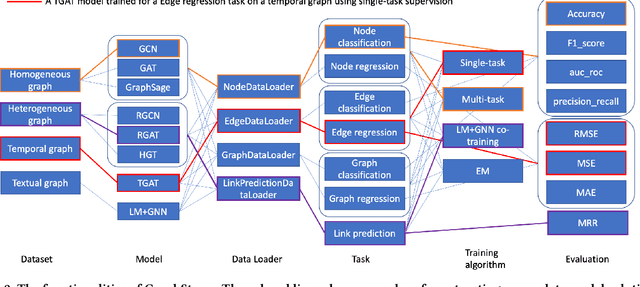

Graph machine learning (GML) is effective in many business applications. However, making GML easy to use and applicable to industry applications with massive datasets remain challenging. We developed GraphStorm, which provides an end-to-end solution for scalable graph construction, graph model training and inference. GraphStorm has the following desirable properties: (a) Easy to use: it can perform graph construction and model training and inference with just a single command; (b) Expert-friendly: GraphStorm contains many advanced GML modeling techniques to handle complex graph data and improve model performance; (c) Scalable: every component in GraphStorm can operate on graphs with billions of nodes and can scale model training and inference to different hardware without changing any code. GraphStorm has been used and deployed for over a dozen billion-scale industry applications after its release in May 2023. It is open-sourced in Github: https://github.com/awslabs/graphstorm.
Graph-Aware Language Model Pre-Training on a Large Graph Corpus Can Help Multiple Graph Applications
Jun 05, 2023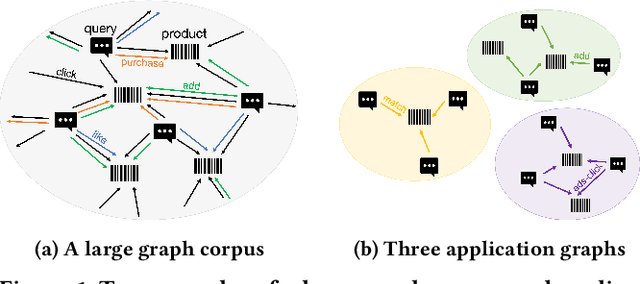
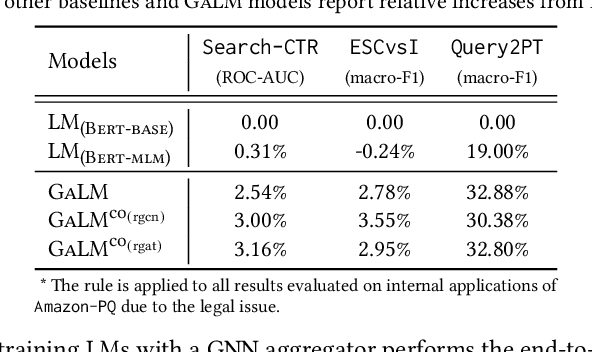
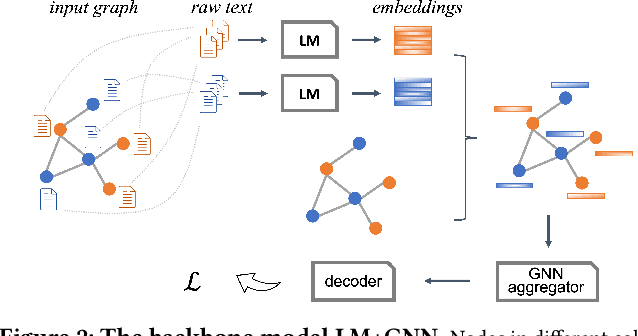
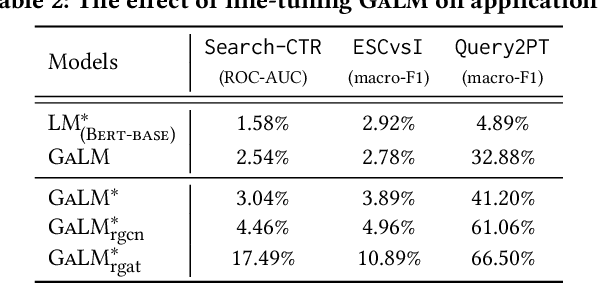
Model pre-training on large text corpora has been demonstrated effective for various downstream applications in the NLP domain. In the graph mining domain, a similar analogy can be drawn for pre-training graph models on large graphs in the hope of benefiting downstream graph applications, which has also been explored by several recent studies. However, no existing study has ever investigated the pre-training of text plus graph models on large heterogeneous graphs with abundant textual information (a.k.a. large graph corpora) and then fine-tuning the model on different related downstream applications with different graph schemas. To address this problem, we propose a framework of graph-aware language model pre-training (GALM) on a large graph corpus, which incorporates large language models and graph neural networks, and a variety of fine-tuning methods on downstream applications. We conduct extensive experiments on Amazon's real internal datasets and large public datasets. Comprehensive empirical results and in-depth analysis demonstrate the effectiveness of our proposed methods along with lessons learned.
Efficient and effective training of language and graph neural network models
Jun 22, 2022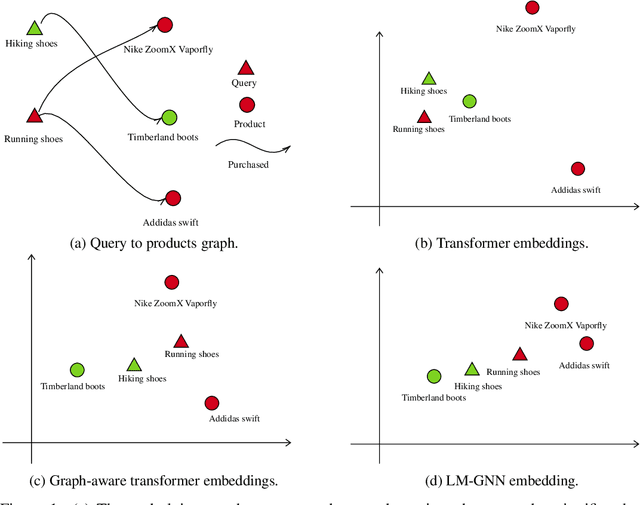
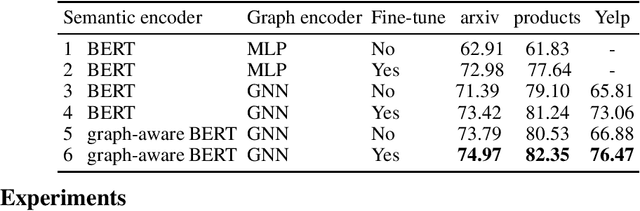
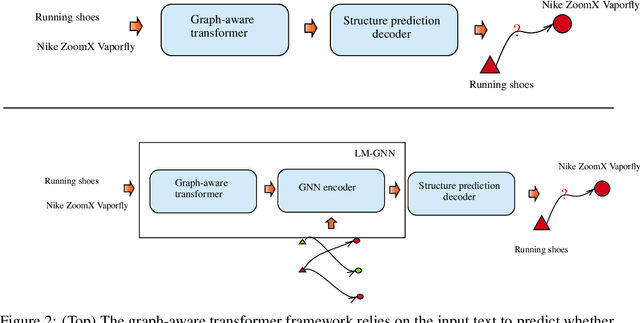
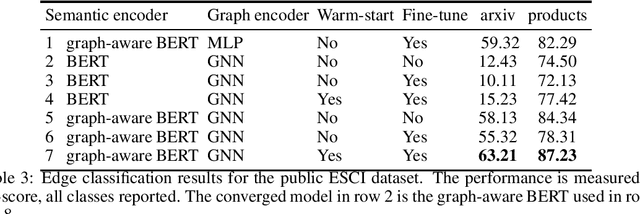
Can we combine heterogenous graph structure with text to learn high-quality semantic and behavioural representations? Graph neural networks (GNN)s encode numerical node attributes and graph structure to achieve impressive performance in a variety of supervised learning tasks. Current GNN approaches are challenged by textual features, which typically need to be encoded to a numerical vector before provided to the GNN that may incur some information loss. In this paper, we put forth an efficient and effective framework termed language model GNN (LM-GNN) to jointly train large-scale language models and graph neural networks. The effectiveness in our framework is achieved by applying stage-wise fine-tuning of the BERT model first with heterogenous graph information and then with a GNN model. Several system and design optimizations are proposed to enable scalable and efficient training. LM-GNN accommodates node and edge classification as well as link prediction tasks. We evaluate the LM-GNN framework in different datasets performance and showcase the effectiveness of the proposed approach. LM-GNN provides competitive results in an Amazon query-purchase-product application.
Conversation Generation with Concept Flow
Nov 07, 2019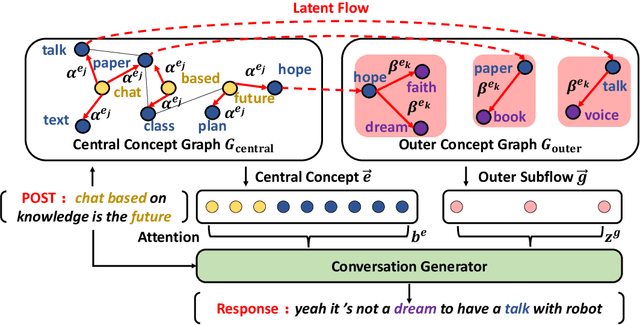
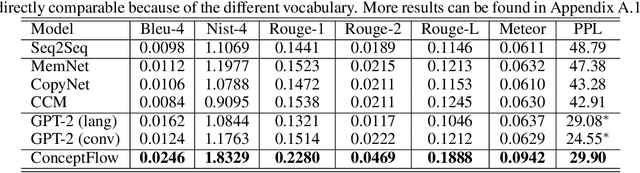
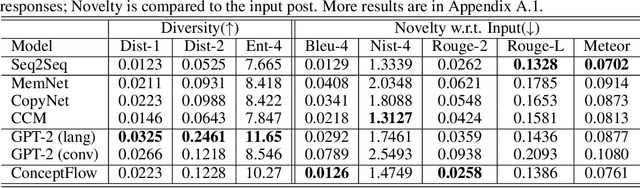
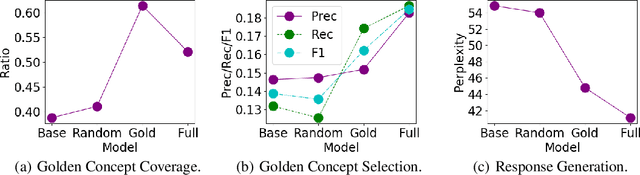
Human conversations naturally evolve around related entities and connected concepts, while may also shift from topic to topic. This paper presents ConceptFlow, which leverages commonsense knowledge graphs to explicitly model such conversation flows for better conversation response generation. ConceptFlow grounds the conversation inputs to the latent concept space and represents the potential conversation flow as a concept flow along the commonsense relations. The concept is guided by a graph attention mechanism that models the possibility of the conversation evolving towards different concepts. The conversation response is then decoded using the encodings of both utterance texts and concept flows, integrating the learned conversation structure in the concept space. Our experiments on Reddit conversations demonstrate the advantage of ConceptFlow over previous commonsense aware dialog models and fine-tuned GPT-2 models, while using much fewer parameters but with explicit modeling of conversation structures.