 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphStorm: all-in-one graph machine learning framework for industry applications
Jun 10, 2024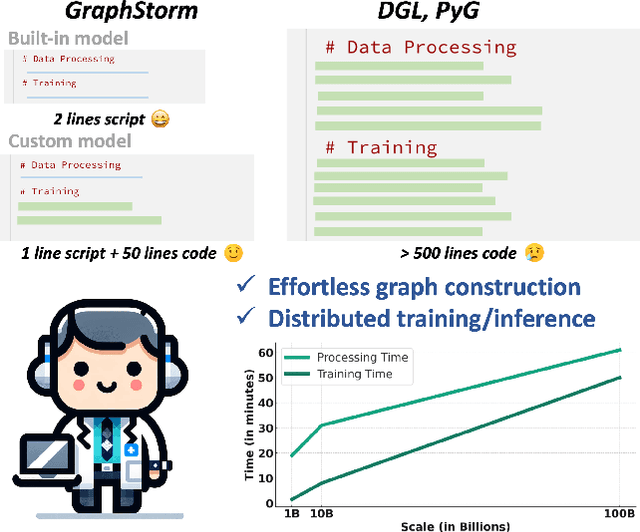

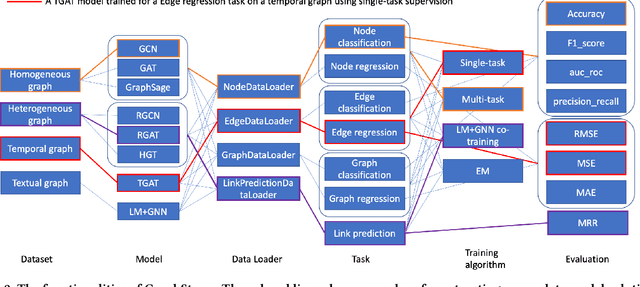

Graph machine learning (GML) is effective in many business applications. However, making GML easy to use and applicable to industry applications with massive datasets remain challenging. We developed GraphStorm, which provides an end-to-end solution for scalable graph construction, graph model training and inference. GraphStorm has the following desirable properties: (a) Easy to use: it can perform graph construction and model training and inference with just a single command; (b) Expert-friendly: GraphStorm contains many advanced GML modeling techniques to handle complex graph data and improve model performance; (c) Scalable: every component in GraphStorm can operate on graphs with billions of nodes and can scale model training and inference to different hardware without changing any code. GraphStorm has been used and deployed for over a dozen billion-scale industry applications after its release in May 2023. It is open-sourced in Github: https://github.com/awslabs/graphstorm.
PIGEON: Optimizing CUDA Code Generator for End-to-End Training and Inference of Relational Graph Neural Networks
Jan 16, 2023Relational graph neural networks (RGNNs) are graph neural networks (GNNs) with dedicated structures for modeling the different types of nodes and/or edges in heterogeneous graphs. While RGNNs have been increasingly adopted in many real-world applications due to their versatility and accuracy, they pose performance and system design challenges due to their inherent computation patterns, gap between the programming interface and kernel APIs, and heavy programming efforts in optimizing kernels caused by their coupling with data layout and heterogeneity. To systematically address these challenges, we propose Pigeon, a novel two-level intermediate representation (IR) and its code generator framework, that (a) represents the key properties of the RGNN models to bridge the gap between the programming interface and kernel APIs, (b) decouples model semantics, data layout, and operators-specific optimization from each other to reduce programming efforts, (c) expresses and leverages optimization opportunities in inter-operator transforms, data layout, and operator-specific schedules. By building on one general matrix multiply (GEMM) template and a node/edge traversal template, Pigeon achieves up to 7.8x speed-up in inference and 5.6x speed-up in training compared with the state-of-the-art public systems in select models, i.e., RGCN, RGAT, HGT, when running heterogeneous graphs provided by Deep Graph Library (DGL) and Open Graph Benchmark (OGB). Pigeon also triggers fewer out-of-memory (OOM) errors. In addition, we propose linear operator fusion and compact materialization to further accelerate the system by up to 2.2x.
Nimble GNN Embedding with Tensor-Train Decomposition
Jun 21, 2022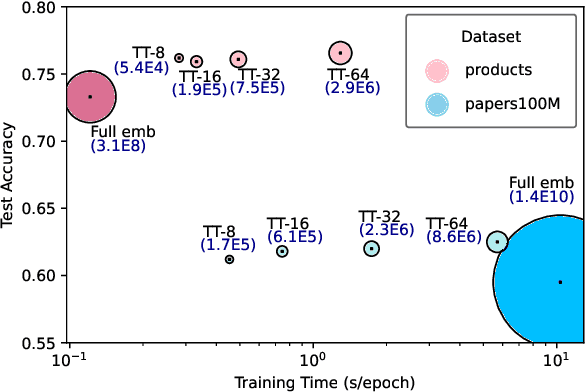

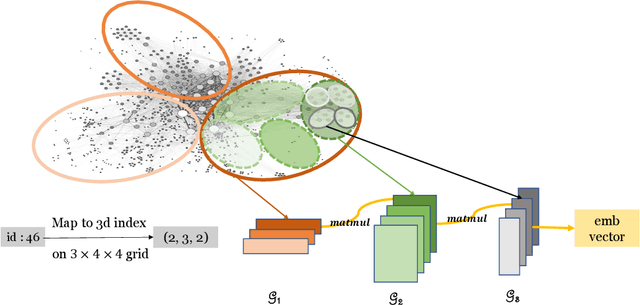
This paper describes a new method for representing embedding tables of graph neural networks (GNNs) more compactly via tensor-train (TT) decomposition. We consider the scenario where (a) the graph data that lack node features, thereby requiring the learning of embeddings during training; and (b) we wish to exploit GPU platforms, where smaller tables are needed to reduce host-to-GPU communication even for large-memory GPUs. The use of TT enables a compact parameterization of the embedding, rendering it small enough to fit entirely on modern GPUs even for massive graphs. When combined with judicious schemes for initialization and hierarchical graph partitioning, this approach can reduce the size of node embedding vectors by 1,659 times to 81,362 times on large publicly available benchmark datasets, achieving comparable or better accuracy and significant speedups on multi-GPU systems. In some cases, our model without explicit node features on input can even match the accuracy of models that use node features.
TGL: A General Framework for Temporal GNN Training on Billion-Scale Graphs
Mar 28, 2022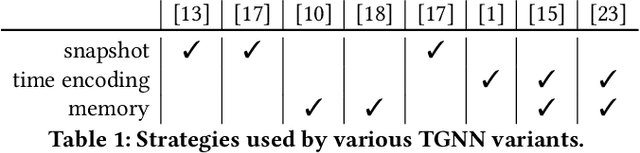
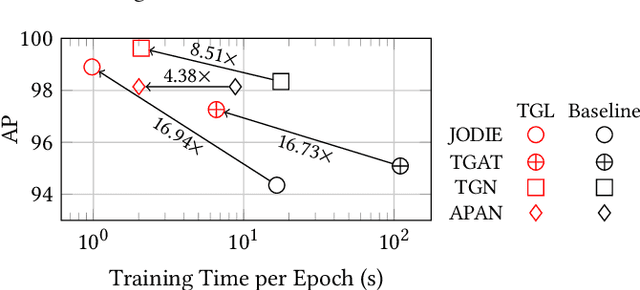
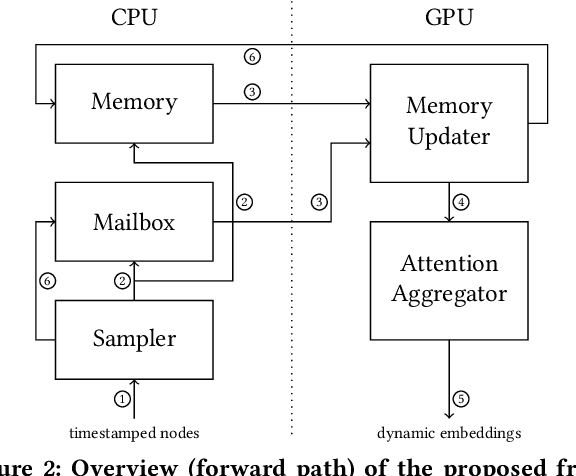
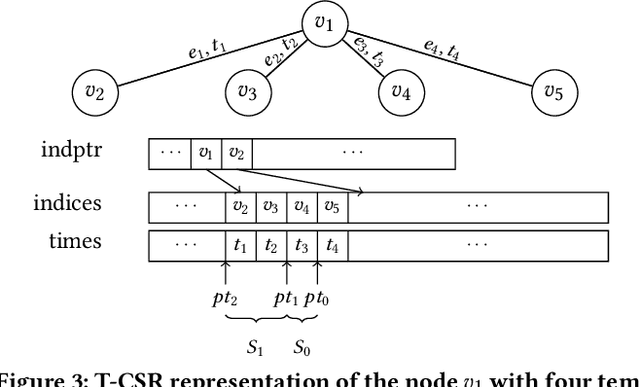
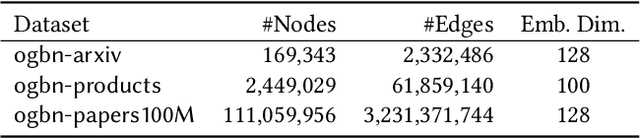
Many real world graphs contain time domain information. Temporal Graph Neural Networks capture temporal information as well as structural and contextual information in the generated dynamic node embeddings. Researchers have shown that these embeddings achieve state-of-the-art performance in many different tasks. In this work, we propose TGL, a unified framework for large-scale offline Temporal Graph Neural Network training where users can compose various Temporal Graph Neural Networks with simple configuration files. TGL comprises five main components, a temporal sampler, a mailbox, a node memory module, a memory updater, and a message passing engine. We design a Temporal-CSR data structure and a parallel sampler to efficiently sample temporal neighbors to formtraining mini-batches. We propose a novel random chunk scheduling technique that mitigates the problem of obsolete node memory when training with a large batch size. To address the limitations of current TGNNs only being evaluated on small-scale datasets, we introduce two large-scale real-world datasets with 0.2 and 1.3 billion temporal edges. We evaluate the performance of TGL on four small-scale datasets with a single GPU and the two large datasets with multiple GPUs for both link prediction and node classification tasks. We compare TGL with the open-sourced code of five methods and show that TGL achieves similar or better accuracy with an average of 13x speedup. Our temporal parallel sampler achieves an average of 173x speedup on a multi-core CPU compared with the baselines. On a 4-GPU machine, TGL can train one epoch of more than one billion temporal edges within 1-10 hours. To the best of our knowledge, this is the first work that proposes a general framework for large-scale Temporal Graph Neural Networks training on multiple GPUs.