 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-like Time Series Summaries via Trend Utility Estimation
Paper and Code
Jan 16, 2020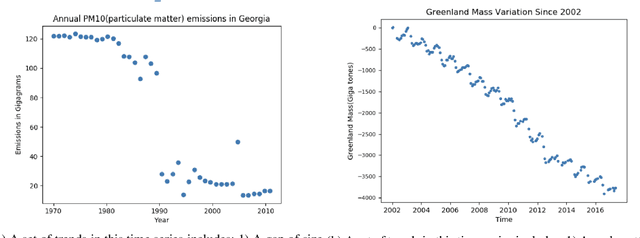


In many scenarios, humans prefer a text-based representation of quantitative data over numerical, tabular, or graphical representations. The attractiveness of textual summaries for complex data has inspired research on data-to-text systems. While there are several data-to-text tools for time series, few of them try to mimic how humans summarize for time series. In this paper, we propose a model to create human-like text descriptions for time series. Our system finds patterns in time series data and ranks these patterns based on empirical observations of human behavior using utility estimation. Our proposed utility estimation model is a Bayesian network capturing interdependencies between different patterns. We describe the learning steps for this network and introduce baselines along with their performance for each step. The output of our system is a natural language description of time series that attempts to match a human's summary of the same data.