 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybriDialogue: An Information-Seeking Dialogue Dataset Grounded on Tabular and Textual Data
Apr 28, 2022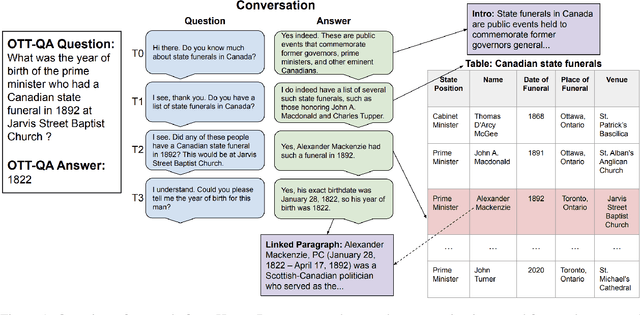
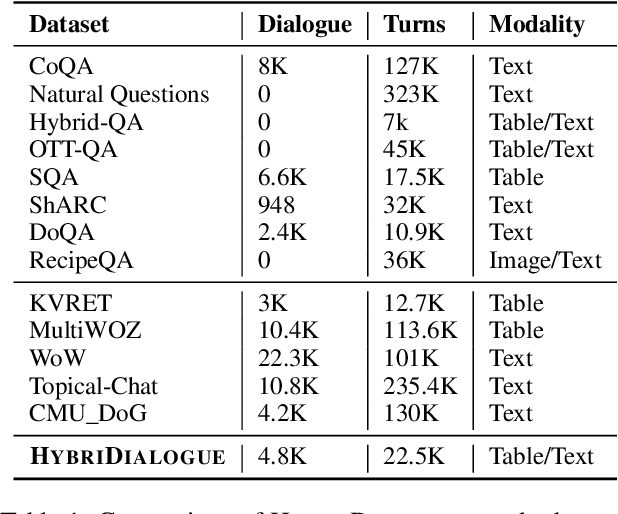
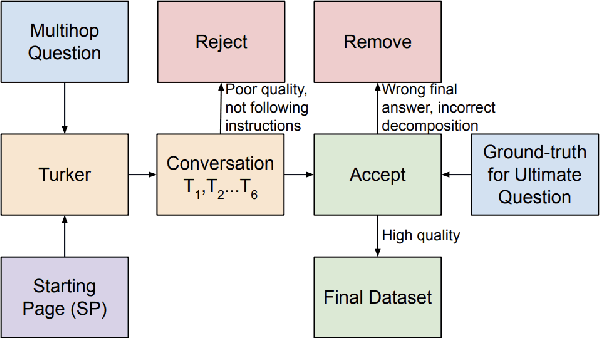
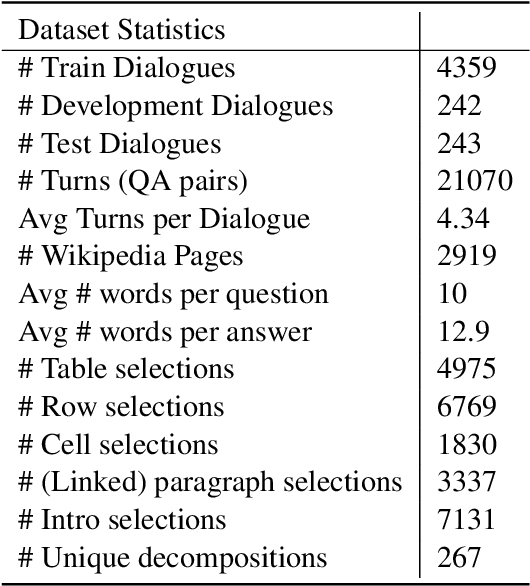
A pressing challenge in current dialogue systems is to successfully converse with users on topics with information distributed across different modalities. Previous work in multiturn dialogue systems has primarily focused on either text or table information. In more realistic scenarios, having a joint understanding of both is critical as knowledge is typically distributed over both unstructured and structured forms. We present a new dialogue dataset, HybriDialogue, which consists of crowdsourced natural conversations grounded on both Wikipedia text and tables. The conversations are created through the decomposition of complex multihop questions into simple, realistic multiturn dialogue interactions. We propose retrieval, system state tracking, and dialogue response generation tasks for our dataset and conduct baseline experiments for each. Our results show that there is still ample opportunity for improvement, demonstrating the importance of building stronger dialogue systems that can reason over the complex setting of information-seeking dialogue grounded on tables and text.
r/Fakeddit: A New Multimodal Benchmark Dataset for Fine-grained Fake News Detection
Nov 10, 2019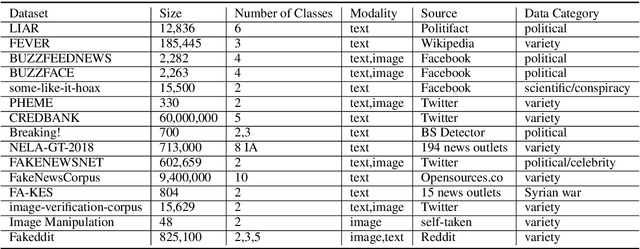

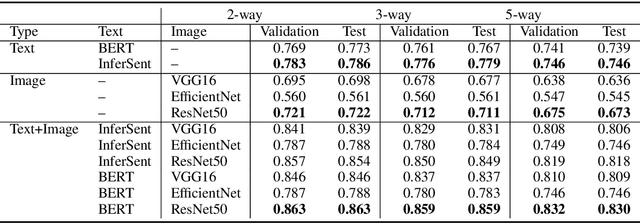
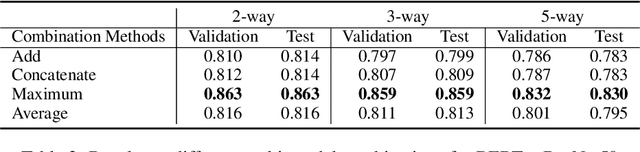
Fake news has altered society in negative ways as evidenced in politics and culture. It has adversely affected both online social network systems as well as offline communities and conversations. Using automatic fake news detection algorithms is an efficient way to combat the rampant dissemination of fake news. However, using an effective dataset has been a problem for fake news research and detection model development. In this paper, we present Fakeddit, a novel dataset consisting of about 800,000 samples from multiple categories of fake news. Each sample is labeled according to 2-way, 3-way, and 5-way classification categories. Prior fake news datasets do not provide multimodal text and image data, metadata, comment data, and fine-grained fake news categorization at this scale and breadth. We construct hybrid text+image models and perform extensive experiments for multiple variations of classification.