 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffective Behaviour Analysis of On-line User Interactions: Are On-line Support Groups more Therapeutic than Twitter?
Nov 04, 2019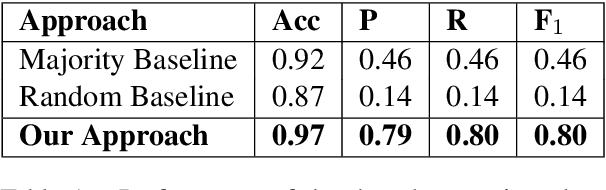
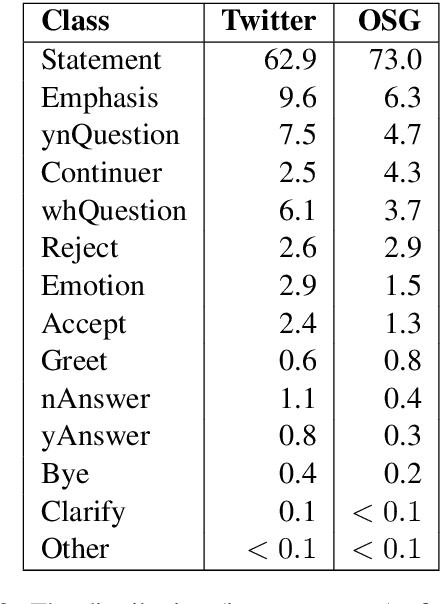
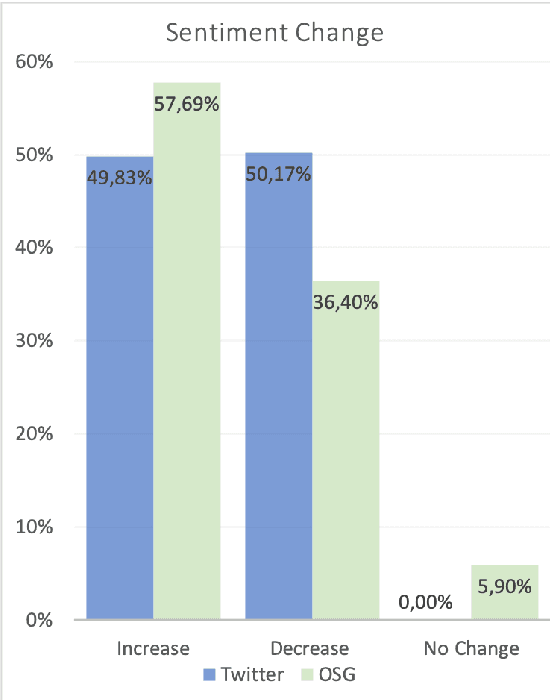
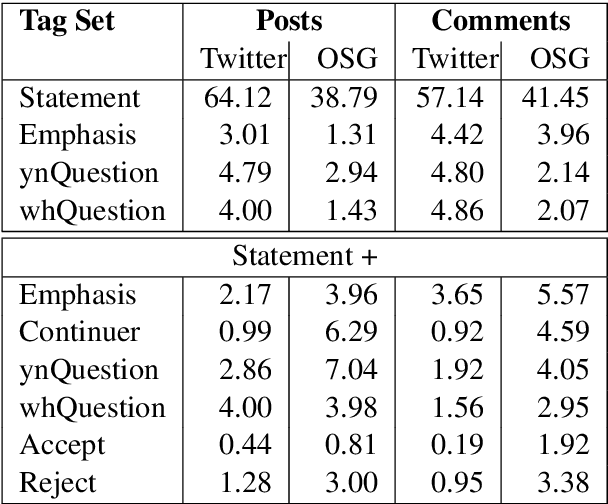
The increase in the prevalence of mental health problems has coincided with a growing popularity of health related social networking sites. Regardless of their therapeutic potential, On-line Support Groups (OSGs) can also have negative effects on patients. In this work we propose a novel methodology to automatically verify the presence of therapeutic factors in social networking websites by using Natural Language Processing (NLP) techniques. The methodology is evaluated on On-line asynchronous multi-party conversations collected from an OSG and Twitter. The results of the analysis indicate that therapeutic factors occur more frequently in OSG conversations than in Twitter conversations. Moreover, the analysis of OSG conversations reveals that the users of that platform are supportive, and interactions are likely to lead to the improvement of their emotional state. We believe that our method provides a stepping stone towards automatic analysis of emotional states of users of online platforms. Possible applications of the method include provision of guidelines that highlight potential implications of using such platforms on users' mental health, and/or support in the analysis of their impact on specific individuals.
Active Annotation: bootstrapping annotation lexicon and guidelines for supervised NLU learning
Aug 12, 2019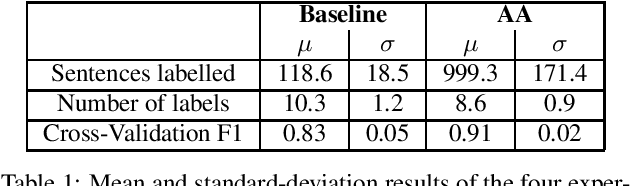
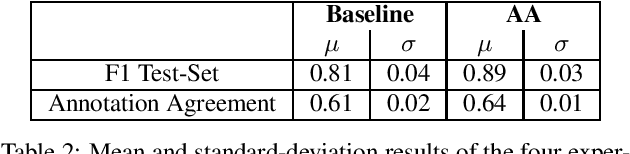
Natural Language Understanding (NLU) models are typically trained in a supervised learning framework. In the case of intent classification, the predicted labels are predefined and based on the designed annotation schema while the labelling process is based on a laborious task where annotators manually inspect each utterance and assign the corresponding label. We propose an Active Annotation (AA) approach where we combine an unsupervised learning method in the embedding space, a human-in-the-loop verification process, and linguistic insights to create lexicons that can be open categories and adapted over time. In particular, annotators define the y-label space on-the-fly during the annotation using an iterative process and without the need for prior knowledge about the input data. We evaluate the proposed annotation paradigm in a real use-case NLU scenario. Results show that our Active Annotation paradigm achieves accurate and higher quality training data, with an annotation speed of an order of magnitude higher with respect to the traditional human-only driven baseline annotation methodology.
* 4 pages
ISO-Standard Domain-Independent Dialogue Act Tagging for Conversational Agents
Jun 12, 2018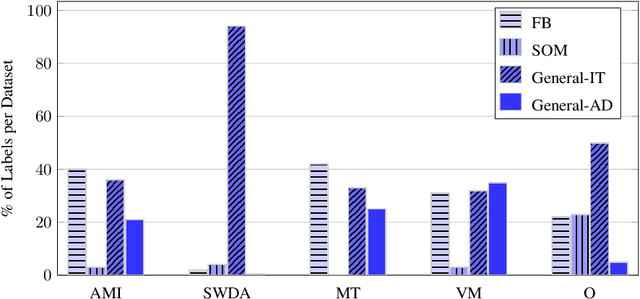

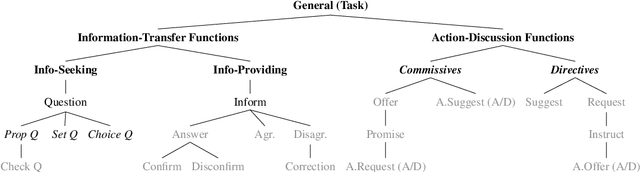
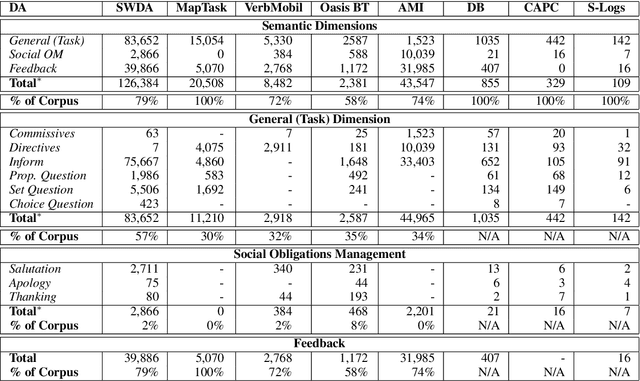
Dialogue Act (DA) tagging is crucial for spoken language understanding systems, as it provides a general representation of speakers' intents, not bound to a particular dialogue system. Unfortunately, publicly available data sets with DA annotation are all based on different annotation schemes and thus incompatible with each other. Moreover, their schemes often do not cover all aspects necessary for open-domain human-machine interaction. In this paper, we propose a methodology to map several publicly available corpora to a subset of the ISO standard, in order to create a large task-independent training corpus for DA classification. We show the feasibility of using this corpus to train a domain-independent DA tagger testing it on out-of-domain conversational data, and argue the importance of training on multiple corpora to achieve robustness across different DA categories.